 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Single Scan to Sequential Consistency: A New Paradigm for LIDAR Relocalization
Feb 03, 2026LiDAR relocalization aims to estimate the global 6-DoF pose of a sensor in the environment. However, existing regression-based approaches are prone to dynamic or ambiguous scenarios, as they either solely rely on single-frame inference or neglect the spatio-temporal consistency across scans. In this paper, we propose TempLoc, a new LiDAR relocalization framework that enhances the robustness of localization by effectively modeling sequential consistency. Specifically, a Global Coordinate Estimation module is first introduced to predict point-wise global coordinates and associated uncertainties for each LiDAR scan. A Prior Coordinate Generation module is then presented to estimate inter-frame point correspondences by the attention mechanism. Lastly, an Uncertainty-Guided Coordinate Fusion module is deployed to integrate both predictions of point correspondence in an end-to-end fashion, yielding a more temporally consistent and accurate global 6-DoF pose. Experimental results on the NCLT and Oxford Robot-Car benchmarks show that our TempLoc outperforms stateof-the-art methods by a large margin, demonstrating the effectiveness of temporal-aware correspondence modeling in LiDAR relocalization. Our code will be released soon.
Bridging the Capability Gap: Joint Alignment Tuning for Harmonizing LLM-based Multi-Agent Systems
Sep 11, 2025The advancement of large language models (LLMs) has enabled the construction of multi-agent systems to solve complex tasks by dividing responsibilities among specialized agents, such as a planning agent for subgoal generation and a grounding agent for executing tool-use actions. Most existing methods typically fine-tune these agents independently, leading to capability gaps among them with poor coordination. To address this, we propose MOAT, a Multi-Agent Joint Alignment Tuning framework that improves agents collaboration through iterative alignment. MOAT alternates between two key stages: (1) Planning Agent Alignment, which optimizes the planning agent to generate subgoal sequences that better guide the grounding agent; and (2) Grounding Agent Improving, which fine-tunes the grounding agent using diverse subgoal-action pairs generated by the agent itself to enhance its generalization capablity. Theoretical analysis proves that MOAT ensures a non-decreasing and progressively convergent training process. Experiments across six benchmarks demonstrate that MOAT outperforms state-of-the-art baselines, achieving average improvements of 3.1% on held-in tasks and 4.4% on held-out tasks.
Simulating Financial Market via Large Language Model based Agents
Jun 28, 2024



Most economic theories typically assume that financial market participants are fully rational individuals and use mathematical models to simulate human behavior in financial markets. However, human behavior is often not entirely rational and is challenging to predict accurately with mathematical models. In this paper, we propose \textbf{A}gent-based \textbf{S}imulated \textbf{F}inancial \textbf{M}arket (ASFM), which first constructs a simulated stock market with a real order matching system. Then, we propose a large language model based agent as the stock trader, which contains the profile, observation, and tool-learning based action module. The trading agent can comprehensively understand current market dynamics and financial policy information, and make decisions that align with their trading strategy. In the experiments, we first verify that the reactions of our ASFM are consistent with the real stock market in two controllable scenarios. In addition, we also conduct experiments in two popular economics research directions, and we find that conclusions drawn in our \model align with the preliminary findings in economics research. Based on these observations, we believe our proposed ASFM provides a new paradigm for economic research.
Confucius: Iterative Tool Learning from Introspection Feedback by Easy-to-Difficult Curriculum
Aug 27, 2023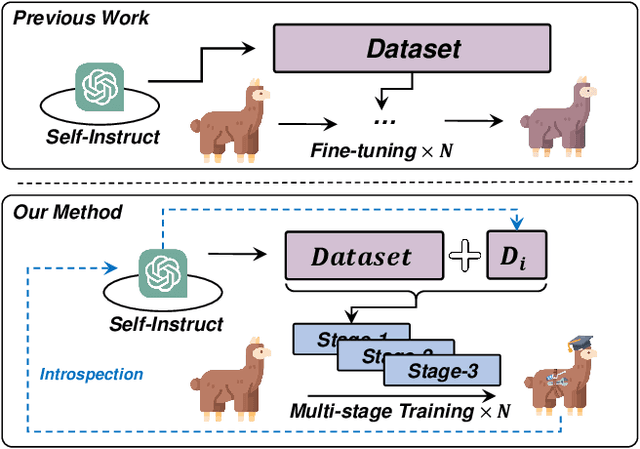
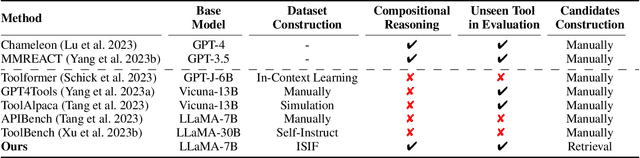
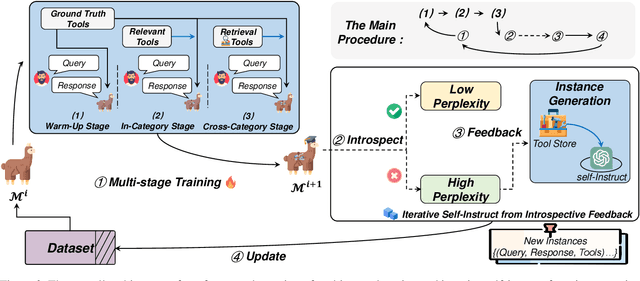

Augmenting large language models (LLMs) with external tools has emerged as a promising approach to extending the capability of LLMs. Although some works employ open-source LLMs for the tool learning task, most of them are trained in a controlled environment in which LLMs only learn to execute the human-provided tools. However, selecting proper tools from the large toolset is also a crucial ability for the tool learning model to be applied in real-world applications. Existing methods usually directly employ self-instruction methods to train the model, which ignores differences in tool complexity. In this paper, we propose the Confucius, a novel tool learning framework to train LLM to use complicated tools in real-world scenarios, which contains two main phases: (1) We first propose a multi-stage learning method to teach the LLM to use various tools from an easy-to-difficult curriculum; (2) thenceforth, we propose the Iterative Self-instruct from Introspective Feedback (ISIF) to dynamically construct the dataset to improve the ability to use the complicated tool. Extensive experiments conducted on both controlled and real-world settings demonstrate the superiority of our tool learning framework in the real-world application scenarios compared to both tuning-free (e.g. ChatGPT, Claude) and tuning-based baselines (e.g. GPT4Tools).