 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Characterization and Mitigation of Sequential Knowledge Editing Collapse
Jan 16, 2026Sequential knowledge editing in large language models often causes catastrophic collapse of the model's general abilities, especially for parameter-modifying methods. Existing approaches mitigate this issue through heuristic constraints on parameter updates, yet the mechanisms underlying such degradation remain insufficiently understood. In this work, we present a spectral analysis of sequential knowledge editing and show that a model's general abilities are closely associated with dominant singular directions of pretrained weight matrices. These directions are highly sensitive to perturbations and are progressively disrupted by repeated edits, closely tracking the collapse in both editing efficacy and general performance. Building on this insight, we propose REVIVE, a plug-and-play framework that stabilizes sequential editing by explicitly preserving the dominant singular subspace. REVIVE represents parameter updates in the spectral basis of the original weights and filters components that would interfere with the protected region. Extensive experiments across multiple models and benchmarks show that REVIVE consistently improves editing efficacy while substantially preserving general abilities under long-horizon sequential editing, including extreme settings with up to 20,000 edits.
Bridging the Capability Gap: Joint Alignment Tuning for Harmonizing LLM-based Multi-Agent Systems
Sep 11, 2025The advancement of large language models (LLMs) has enabled the construction of multi-agent systems to solve complex tasks by dividing responsibilities among specialized agents, such as a planning agent for subgoal generation and a grounding agent for executing tool-use actions. Most existing methods typically fine-tune these agents independently, leading to capability gaps among them with poor coordination. To address this, we propose MOAT, a Multi-Agent Joint Alignment Tuning framework that improves agents collaboration through iterative alignment. MOAT alternates between two key stages: (1) Planning Agent Alignment, which optimizes the planning agent to generate subgoal sequences that better guide the grounding agent; and (2) Grounding Agent Improving, which fine-tunes the grounding agent using diverse subgoal-action pairs generated by the agent itself to enhance its generalization capablity. Theoretical analysis proves that MOAT ensures a non-decreasing and progressively convergent training process. Experiments across six benchmarks demonstrate that MOAT outperforms state-of-the-art baselines, achieving average improvements of 3.1% on held-in tasks and 4.4% on held-out tasks.
Disentangling Knowledge Representations for Large Language Model Editing
May 24, 2025Knowledge Editing has emerged as a promising solution for efficiently updating embedded knowledge in large language models (LLMs). While existing approaches demonstrate effectiveness in integrating new knowledge and preserving the original capabilities of LLMs, they fail to maintain fine-grained irrelevant knowledge facts that share the same subject as edited knowledge but differ in relation and object. This challenge arises because subject representations inherently encode multiple attributes, causing the target and fine-grained irrelevant knowledge to become entangled in the representation space, and thus vulnerable to unintended alterations during editing. To address this, we propose DiKE, a novel approach that Disentangles Knowledge representations for LLM Editing (DiKE). DiKE consists of two key components: a Knowledge Representation Disentanglement (KRD) module that decomposes the subject representation into target-knowledgerelated and -unrelated components, and a Disentanglement-based Knowledge Edit (DKE) module that updates only the target-related component while explicitly preserving the unrelated one. We further derive a closed-form, rank-one parameter update based on matrix theory to enable efficient and minimally invasive edits. To rigorously evaluate fine-grained irrelevant knowledge preservation, we construct FINE-KED, a new benchmark comprising fine-grained irrelevant knowledge at different levels of relational similarity to the edited knowledge. Extensive experiments across multiple LLMs demonstrate that DiKE substantially improves fine-grained irrelevant knowledge preservation while maintaining competitive general editing performance.
Direct Retrieval-augmented Optimization: Synergizing Knowledge Selection and Language Models
May 05, 2025Retrieval-augmented generation (RAG) integrates large language models ( LLM s) with retrievers to access external knowledge, improving the factuality of LLM generation in knowledge-grounded tasks. To optimize the RAG performance, most previous work independently fine-tunes the retriever to adapt to frozen LLM s or trains the LLMs to use documents retrieved by off-the-shelf retrievers, lacking end-to-end training supervision. Recent work addresses this limitation by jointly training these two components but relies on overly simplifying assumptions of document independence, which has been criticized for being far from real-world scenarios. Thus, effectively optimizing the overall RAG performance remains a critical challenge. We propose a direct retrieval-augmented optimization framework, named DRO, that enables end-to-end training of two key components: (i) a generative knowledge selection model and (ii) an LLM generator. DRO alternates between two phases: (i) document permutation estimation and (ii) re-weighted maximization, progressively improving RAG components through a variational approach. In the estimation step, we treat document permutation as a latent variable and directly estimate its distribution from the selection model by applying an importance sampling strategy. In the maximization step, we calibrate the optimization expectation using importance weights and jointly train the selection model and LLM generator. Our theoretical analysis reveals that DRO is analogous to policy-gradient methods in reinforcement learning. Extensive experiments conducted on five datasets illustrate that DRO outperforms the best baseline with 5%-15% improvements in EM and F1. We also provide in-depth experiments to qualitatively analyze the stability, convergence, and variance of DRO.
Replication and Exploration of Generative Retrieval over Dynamic Corpora
Apr 24, 2025Generative retrieval (GR) has emerged as a promising paradigm in information retrieval (IR). However, most existing GR models are developed and evaluated using a static document collection, and their performance in dynamic corpora where document collections evolve continuously is rarely studied. In this paper, we first reproduce and systematically evaluate various representative GR approaches over dynamic corpora. Through extensive experiments, we reveal that existing GR models with \textit{text-based} docids show superior generalization to unseen documents. We observe that the more fine-grained the docid design in the GR model, the better its performance over dynamic corpora, surpassing BM25 and even being comparable to dense retrieval methods. While GR models with \textit{numeric-based} docids show high efficiency, their performance drops significantly over dynamic corpora. Furthermore, our experiments find that the underperformance of numeric-based docids is partly due to their excessive tendency toward the initial document set, which likely results from overfitting on the training set. We then conduct an in-depth analysis of the best-performing GR methods. We identify three critical advantages of text-based docids in dynamic corpora: (i) Semantic alignment with language models' pretrained knowledge, (ii) Fine-grained docid design, and (iii) High lexical diversity. Building on these insights, we finally propose a novel multi-docid design that leverages both the efficiency of numeric-based docids and the effectiveness of text-based docids, achieving improved performance in dynamic corpus without requiring additional retraining. Our work offers empirical evidence for advancing GR methods over dynamic corpora and paves the way for developing more generalized yet efficient GR models in real-world search engines.
Integrating Learning-Based Manipulation and Physics-Based Locomotion for Whole-Body Badminton Robot Control
Apr 24, 2025Learning-based methods, such as imitation learning (IL) and reinforcement learning (RL), can produce excel control policies over challenging agile robot tasks, such as sports robot. However, no existing work has harmonized learning-based policy with model-based methods to reduce training complexity and ensure the safety and stability for agile badminton robot control. In this paper, we introduce \ourmethod, a novel hybrid control system for agile badminton robots. Specifically, we propose a model-based strategy for chassis locomotion which provides a base for arm policy. We introduce a physics-informed ``IL+RL'' training framework for learning-based arm policy. In this train framework, a model-based strategy with privileged information is used to guide arm policy training during both IL and RL phases. In addition, we train the critic model during IL phase to alleviate the performance drop issue when transitioning from IL to RL. We present results on our self-engineered badminton robot, achieving 94.5% success rate against the serving machine and 90.7% success rate against human players. Our system can be easily generalized to other agile mobile manipulation tasks such as agile catching and table tennis. Our project website: https://dreamstarring.github.io/HAMLET/.
Improving Sequential Recommenders through Counterfactual Augmentation of System Exposure
Apr 18, 2025In sequential recommendation (SR), system exposure refers to items that are exposed to the user. Typically, only a few of the exposed items would be interacted with by the user. Although SR has achieved great success in predicting future user interests, existing SR methods still fail to fully exploit system exposure data. Most methods only model items that have been interacted with, while the large volume of exposed but non-interacted items is overlooked. Even methods that consider the whole system exposure typically train the recommender using only the logged historical system exposure, without exploring unseen user interests. In this paper, we propose counterfactual augmentation over system exposure for sequential recommendation (CaseRec). To better model historical system exposure, CaseRec introduces reinforcement learning to account for different exposure rewards. CaseRec uses a decision transformer-based sequential model to take an exposure sequence as input and assigns different rewards according to the user feedback. To further explore unseen user interests, CaseRec proposes to perform counterfactual augmentation, where exposed original items are replaced with counterfactual items. Then, a transformer-based user simulator is proposed to predict the user feedback reward for the augmented items. Augmentation, together with the user simulator, constructs counterfactual exposure sequences to uncover new user interests. Finally, CaseRec jointly uses the logged exposure sequences with the counterfactual exposure sequences to train a decision transformer-based sequential model for generating recommendation. Experiments on three real-world benchmarks show the effectiveness of CaseRec. Our code is available at https://github.com/ZiqiZhao1/CaseRec.
Constrained Auto-Regressive Decoding Constrains Generative Retrieval
Apr 14, 2025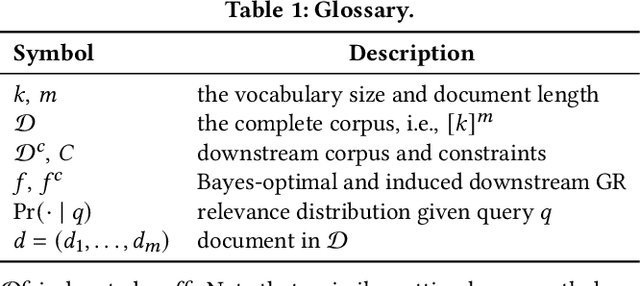
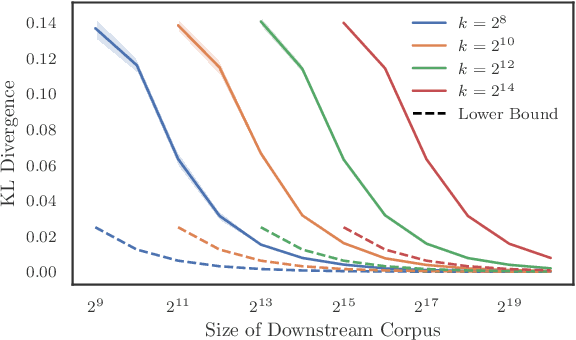
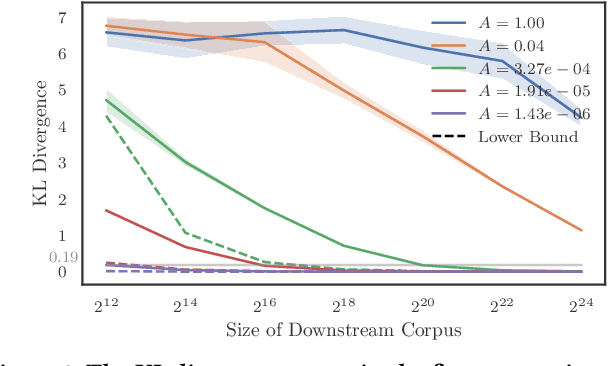
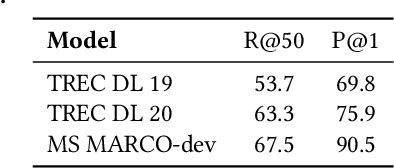
Generative retrieval seeks to replace traditional search index data structures with a single large-scale neural network, offering the potential for improved efficiency and seamless integration with generative large language models. As an end-to-end paradigm, generative retrieval adopts a learned differentiable search index to conduct retrieval by directly generating document identifiers through corpus-specific constrained decoding. The generalization capabilities of generative retrieval on out-of-distribution corpora have gathered significant attention. In this paper, we examine the inherent limitations of constrained auto-regressive generation from two essential perspectives: constraints and beam search. We begin with the Bayes-optimal setting where the generative retrieval model exactly captures the underlying relevance distribution of all possible documents. Then we apply the model to specific corpora by simply adding corpus-specific constraints. Our main findings are two-fold: (i) For the effect of constraints, we derive a lower bound of the error, in terms of the KL divergence between the ground-truth and the model-predicted step-wise marginal distributions. (ii) For the beam search algorithm used during generation, we reveal that the usage of marginal distributions may not be an ideal approach. This paper aims to improve our theoretical understanding of the generalization capabilities of the auto-regressive decoding retrieval paradigm, laying a foundation for its limitations and inspiring future advancements toward more robust and generalizable generative retrieval.
Learnable Sequence Augmenter for Triplet Contrastive Learning in Sequential Recommendation
Mar 26, 2025Most existing contrastive learning-based sequential recommendation (SR) methods rely on random operations (e.g., crop, reorder, and substitute) to generate augmented sequences. These methods often struggle to create positive sample pairs that closely resemble the representations of the raw sequences, potentially disrupting item correlations by deleting key items or introducing noisy iterac, which misguides the contrastive learning process. To address this limitation, we propose Learnable sequence Augmentor for triplet Contrastive Learning in sequential Recommendation (LACLRec). Specifically, the self-supervised learning-based augmenter can automatically delete noisy items from sequences and insert new items that better capture item transition patterns, generating a higher-quality augmented sequence. Subsequently, we randomly generate another augmented sequence and design a ranking-based triplet contrastive loss to differentiate the similarities between the raw sequence, the augmented sequence from augmenter, and the randomly augmented sequence, providing more fine-grained contrastive signals. Extensive experiments on three real-world datasets demonstrate that both the sequence augmenter and the triplet contrast contribute to improving recommendation accuracy. LACLRec significantly outperforms the baseline model CL4SRec, and demonstrates superior performance compared to several state-of-the-art sequential recommendation algorithms.
UIPE: Enhancing LLM Unlearning by Removing Knowledge Related to Forgetting Targets
Mar 06, 2025Large Language Models (LLMs) inevitably acquire harmful information during training on massive datasets. LLM unlearning aims to eliminate the influence of such harmful information while maintaining the model's overall performance. Existing unlearning methods, represented by gradient ascent-based approaches, primarily focus on forgetting target data while overlooking the crucial impact of logically related knowledge on the effectiveness of unlearning. In this paper, through both theoretical and experimental analyses, we first demonstrate that a key reason for the suboptimal unlearning performance is that models can reconstruct the target content through reasoning with logically related knowledge. To address this issue, we propose Unlearning Improvement via Parameter Extrapolation (UIPE), a method that removes knowledge highly correlated with the forgetting targets. Experimental results show that UIPE significantly enhances the performance of various mainstream LLM unlearning methods on the TOFU benchmark.