 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDJSCC-Enabled Multi-User Semantic CSI Feedback for Hybrid Beamforming in Dual-Polarized cmWave Massive MIMO
May 19, 2026Driven by the ultra-high throughput requirements of 6G, wireless communications are migrating to centimeter wave (cmWave) bands to overcome the limitations of current spectral resources. Massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) systems aim to achieve high spectral efficiency in cmWave regimes but are often constrained by the heavy overhead of downlink channel state information (CSI) feedback. This paper proposes a deep learning scheme based on the multi-axis multi-layer perceptron for image processing (MAXIM) architecture for joint semantic CSI feedback and hybrid beamforming in multi-user cmWave MIMO-OFDM systems, which maximizes the downlink sum rate by end-to-end optimization. Specifically, distributed encoders at multiple user equipments (UEs) perform limited CSI feedback, while the decoder at the base station (BS) jointly designs the hybrid beamforming matrices without explicit CSI reconstruction. The uplink transmission is implemented via deep joint source-channel coding (DJSCC) to enhance CSI compression efficiency and noise robustness. Furthermore, considering the high correlation between vertical and horizontal polarization channels in dual-polarized massive MIMO systems, a cross-polarization interaction module is introduced at the UEs to exploit polarization correlations for joint CSI compression. Simulation results demonstrate that the proposed method improves the downlink sum rate under various signal-to-noise ratio (SNR) conditions with a limited number of feedback symbols, validating its robustness and superiority in multi-user dual-polarized cmWave MIMO-OFDM systems.
QSIM: Mitigating Overestimation in Multi-Agent Reinforcement Learning via Action Similarity Weighted Q-Learning
Feb 26, 2026Value decomposition (VD) methods have achieved remarkable success in cooperative multi-agent reinforcement learning (MARL). However, their reliance on the max operator for temporal-difference (TD) target calculation leads to systematic Q-value overestimation. This issue is particularly severe in MARL due to the combinatorial explosion of the joint action space, which often results in unstable learning and suboptimal policies. To address this problem, we propose QSIM, a similarity weighted Q-learning framework that reconstructs the TD target using action similarity. Instead of using the greedy joint action directly, QSIM forms a similarity weighted expectation over a structured near-greedy joint action space. This formulation allows the target to integrate Q-values from diverse yet behaviorally related actions while assigning greater influence to those that are more similar to the greedy choice. By smoothing the target with structurally relevant alternatives, QSIM effectively mitigates overestimation and improves learning stability. Extensive experiments demonstrate that QSIM can be seamlessly integrated with various VD methods, consistently yielding superior performance and stability compared to the original algorithms. Furthermore, empirical analysis confirms that QSIM significantly mitigates the systematic value overestimation in MARL. Code is available at https://github.com/MaoMaoLYJ/pymarl-qsim.
How to Build Robust, Scalable Models for GSV-Based Indicators in Neighborhood Research
Jan 10, 2026A substantial body of health research demonstrates a strong link between neighborhood environments and health outcomes. Recently, there has been increasing interest in leveraging advances in computer vision to enable large-scale, systematic characterization of neighborhood built environments. However, the generalizability of vision models across fundamentally different domains remains uncertain, for example, transferring knowledge from ImageNet to the distinct visual characteristics of Google Street View (GSV) imagery. In applied fields such as social health research, several critical questions arise: which models are most appropriate, whether to adopt unsupervised training strategies, what training scale is feasible under computational constraints, and how much such strategies benefit downstream performance. These decisions are often costly and require specialized expertise. In this paper, we answer these questions through empirical analysis and provide practical insights into how to select and adapt foundation models for datasets with limited size and labels, while leveraging larger, unlabeled datasets through unsupervised training. Our study includes comprehensive quantitative and visual analyses comparing model performance before and after unsupervised adaptation.
Balancing Rewards in Text Summarization: Multi-Objective Reinforcement Learning via HyperVolume Optimization
Oct 22, 2025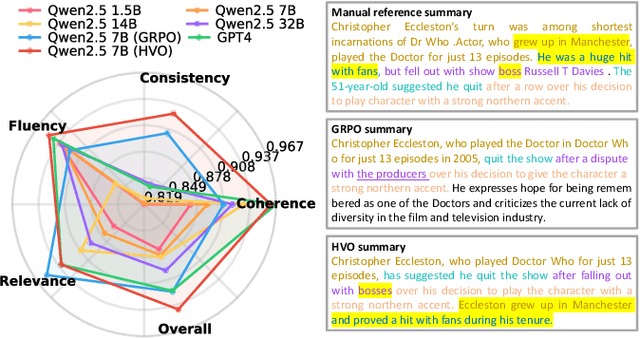
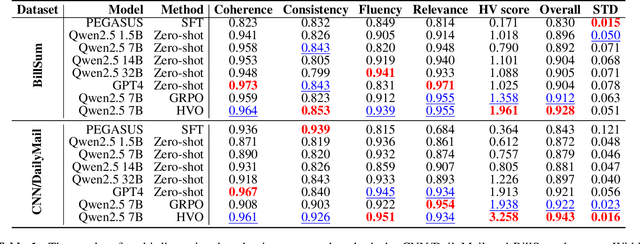
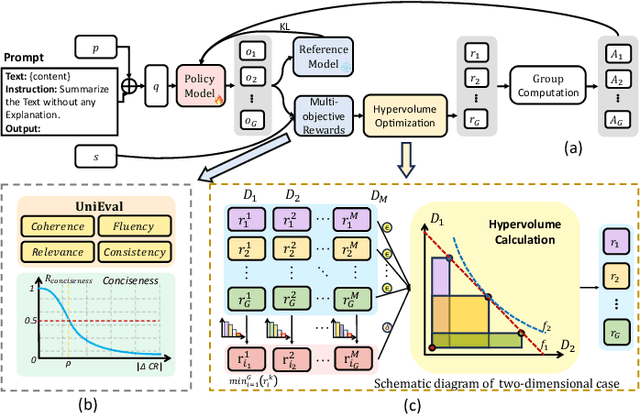

Text summarization is a crucial task that requires the simultaneous optimization of multiple objectives, including consistency, coherence, relevance, and fluency, which presents considerable challenges. Although large language models (LLMs) have demonstrated remarkable performance, enhanced by reinforcement learning (RL), few studies have focused on optimizing the multi-objective problem of summarization through RL based on LLMs. In this paper, we introduce hypervolume optimization (HVO), a novel optimization strategy that dynamically adjusts the scores between groups during the reward process in RL by using the hypervolume method. This method guides the model's optimization to progressively approximate the pareto front, thereby generating balanced summaries across multiple objectives. Experimental results on several representative summarization datasets demonstrate that our method outperforms group relative policy optimization (GRPO) in overall scores and shows more balanced performance across different dimensions. Moreover, a 7B foundation model enhanced by HVO performs comparably to GPT-4 in the summarization task, while maintaining a shorter generation length. Our code is publicly available at https://github.com/ai4business-LiAuto/HVO.git
Hybrid Frequency Transmission for Upload Latency Minimization of IoT Devices in HSR Scenario Aided by Intelligent Reflecting Surfaces
Feb 18, 2025The explosively growing demand for Internet of Things (IoT) in high-speed railway (HSR) scenario has attracted a lot of attention amongst researchers. However, limited IoT device (IoTD) batteries and large information upload latency still remain critical impediments to practical service applications. In this paper, we consider a HSR wireless mobile communication system, where two intelligent reflecting surfaces (IRSs) are deployed to help solve the problems above. Considering the carrier aggregation method, the IRS needs to be optimized globally in hybrid frequency bands. Meanwhile, to ensure information security, the transmission to the mobile communication relay (MCR) on the train is covert to passengers in the carriage by IRS. This problem is challenging to handle since the variables are coupled with each other and some tricky constraints. We firstly transform the original sum-of-ratios problem into the more tractable parametric problem. Then, the block coordinate descent (BCD) algorithm is adopted to decouple the problem into two main sub-problems, and the downlink and uplink settings are alternatively optimized using low-complexity iterative algorithms. Finally, a heuristic algorithm to mitigate the Doppler spread is proposed to further improve the performance. Simulation results corroborate the performance improvement of the proposed algorithm.
Beyond Local Views: Global State Inference with Diffusion Models for Cooperative Multi-Agent Reinforcement Learning
Aug 18, 2024



In partially observable multi-agent systems, agents typically only have access to local observations. This severely hinders their ability to make precise decisions, particularly during decentralized execution. To alleviate this problem and inspired by image outpainting, we propose State Inference with Diffusion Models (SIDIFF), which uses diffusion models to reconstruct the original global state based solely on local observations. SIDIFF consists of a state generator and a state extractor, which allow agents to choose suitable actions by considering both the reconstructed global state and local observations. In addition, SIDIFF can be effortlessly incorporated into current multi-agent reinforcement learning algorithms to improve their performance. Finally, we evaluated SIDIFF on different experimental platforms, including Multi-Agent Battle City (MABC), a novel and flexible multi-agent reinforcement learning environment we developed. SIDIFF achieved desirable results and outperformed other popular algorithms.
Verco: Learning Coordinated Verbal Communication for Multi-agent Reinforcement Learning
Apr 27, 2024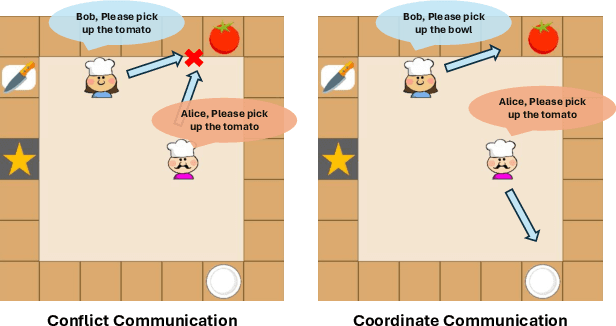
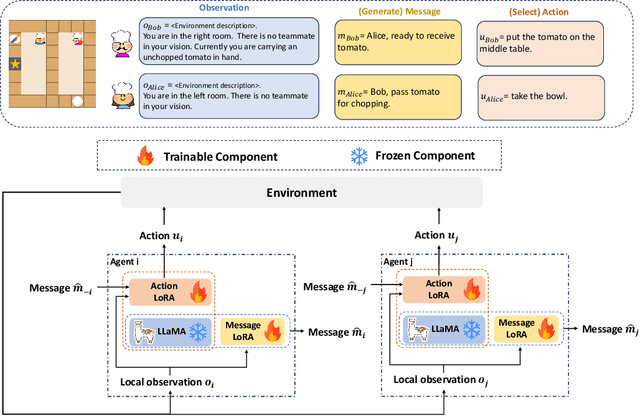
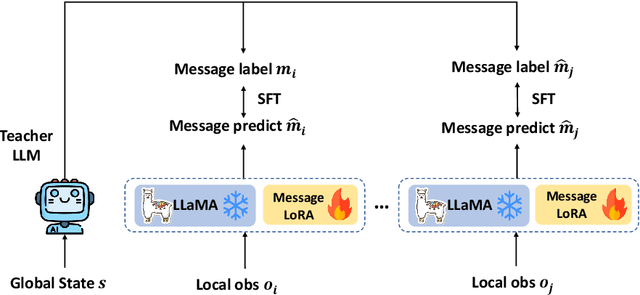
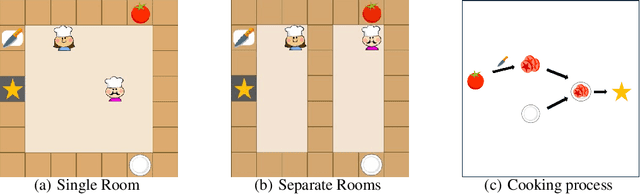
In recent years, multi-agent reinforcement learning algorithms have made significant advancements in diverse gaming environments, leading to increased interest in the broader application of such techniques. To address the prevalent challenge of partial observability, communication-based algorithms have improved cooperative performance through the sharing of numerical embedding between agents. However, the understanding of the formation of collaborative mechanisms is still very limited, making designing a human-understandable communication mechanism a valuable problem to address. In this paper, we propose a novel multi-agent reinforcement learning algorithm that embeds large language models into agents, endowing them with the ability to generate human-understandable verbal communication. The entire framework has a message module and an action module. The message module is responsible for generating and sending verbal messages to other agents, effectively enhancing information sharing among agents. To further enhance the message module, we employ a teacher model to generate message labels from the global view and update the student model through Supervised Fine-Tuning (SFT). The action module receives messages from other agents and selects actions based on current local observations and received messages. Experiments conducted on the Overcooked game demonstrate our method significantly enhances the learning efficiency and performance of existing methods, while also providing an interpretable tool for humans to understand the process of multi-agent cooperation.
KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph
Dec 26, 2023Large language model (LLM) has achieved outstanding performance on various downstream tasks with its powerful natural language understanding and zero-shot capability, but LLM still suffers from knowledge limitation. Especially in scenarios that require long logical chains or complex reasoning, the hallucination and knowledge limitation of LLM limit its performance in question answering (QA). In this paper, we propose a novel framework KnowledgeNavigator to address these challenges by efficiently and accurately retrieving external knowledge from knowledge graph and using it as a key factor to enhance LLM reasoning. Specifically, KnowledgeNavigator first mines and enhances the potential constraints of the given question to guide the reasoning. Then it retrieves and filters external knowledge that supports answering through iterative reasoning on knowledge graph with the guidance of LLM and the question. Finally, KnowledgeNavigator constructs the structured knowledge into effective prompts that are friendly to LLM to help its reasoning. We evaluate KnowledgeNavigator on multiple public KGQA benchmarks, the experiments show the framework has great effectiveness and generalization, outperforming previous knowledge graph enhanced LLM methods and is comparable to the fully supervised models.
Adaptive parameter sharing for multi-agent reinforcement learning
Dec 14, 2023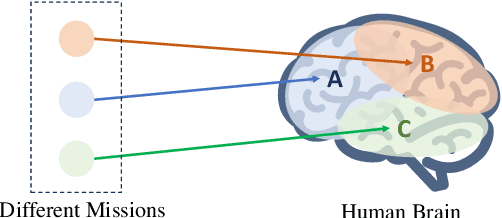
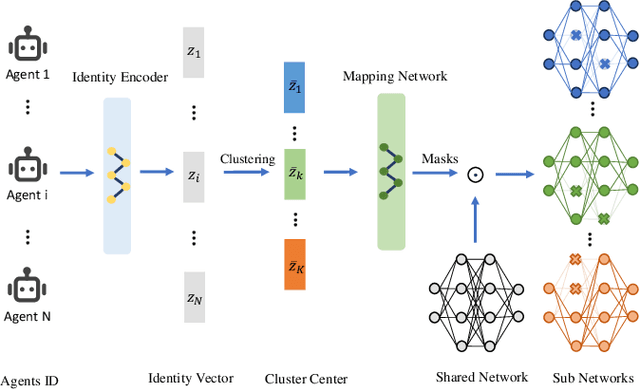
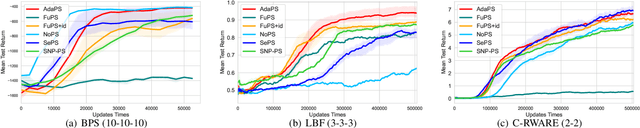
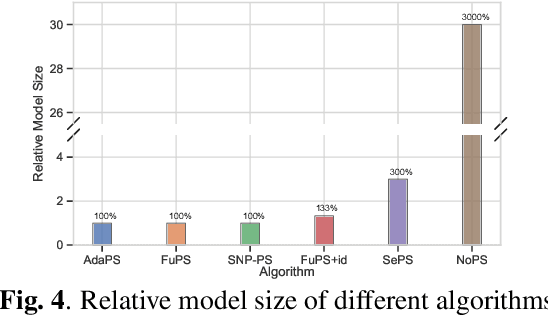
Parameter sharing, as an important technique in multi-agent systems, can effectively solve the scalability issue in large-scale agent problems. However, the effectiveness of parameter sharing largely depends on the environment setting. When agents have different identities or tasks, naive parameter sharing makes it difficult to generate sufficiently differentiated strategies for agents. Inspired by research pertaining to the brain in biology, we propose a novel parameter sharing method. It maps each type of agent to different regions within a shared network based on their identity, resulting in distinct subnetworks. Therefore, our method can increase the diversity of strategies among different agents without introducing additional training parameters. Through experiments conducted in multiple environments, our method has shown better performance than other parameter sharing methods.
Controlling Large Language Model-based Agents for Large-Scale Decision-Making: An Actor-Critic Approach
Nov 23, 2023



The significant advancements in large language models (LLMs) have presented novel opportunities for tackling planning and decision-making within multi-agent systems. However, as the number of agents increases, the issues of hallucination in LLMs and coordination in multi-agent systems (MAS) have become increasingly pronounced. Additionally, the efficient utilization of tokens becomes a critical consideration when employing LLMs to facilitate the interactions of large numbers of agents. In this paper, we present a novel framework aimed at enhancing coordination and decision-making capabilities of LLMs within large-scale multi-agent environments. Our approach draws inspiration from the actor-critic framework employed in multi-agent reinforcement learning, and we develop a modular and token-efficient solution that effectively addresses challenges presented by LLMs and MAS. Through evaluations conducted in experiments involving system resource allocation and robot grid transportation, we demonstrate the considerable advantages afforded by our proposed approach.