 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA: A Spatially Explicit Architecture for Multi-Agent Reinforcement Learning
Paper and Code
Apr 25, 2023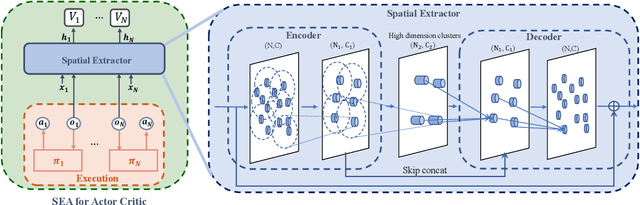
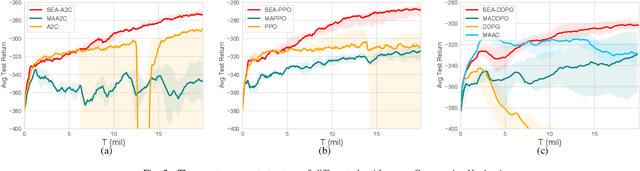
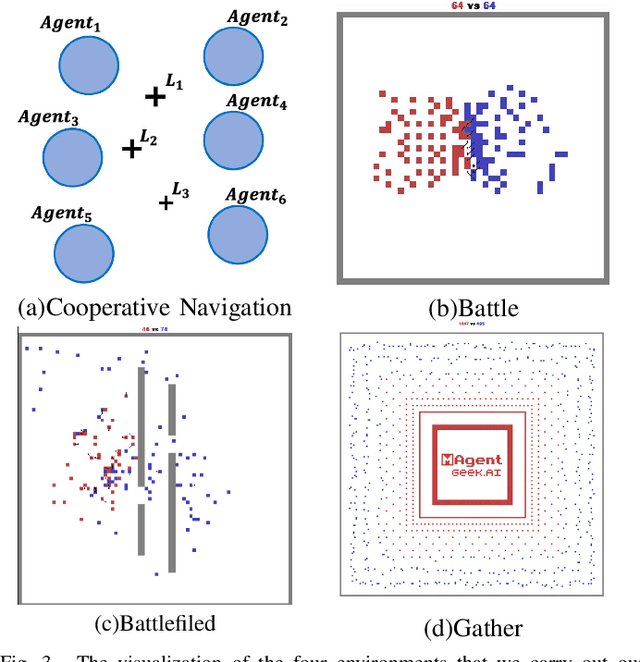
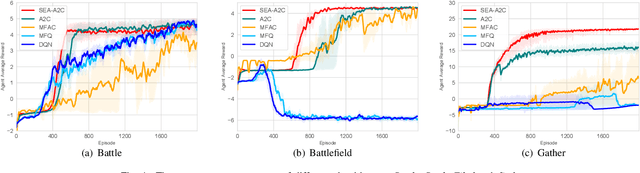
Spatial information is essential in various fields. How to explicitly model according to the spatial location of agents is also very important for the multi-agent problem, especially when the number of agents is changing and the scale is enormous. Inspired by the point cloud task in computer vision, we propose a spatial information extraction structure for multi-agent reinforcement learning in this paper. Agents can effectively share the neighborhood and global information through a spatially encoder-decoder structure. Our method follows the centralized training with decentralized execution (CTDE) paradigm. In addition, our structure can be applied to various existing mainstream reinforcement learning algorithms with minor modifications and can deal with the problem with a variable number of agents. The experiments in several multi-agent scenarios show that the existing methods can get convincing results by adding our spatially explicit architecture.