 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025



Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
AIR: Unifying Individual and Collective Exploration in Cooperative Multi-Agent Reinforcement Learning
Dec 30, 2024Exploration in cooperative multi-agent reinforcement learning (MARL) remains challenging for value-based agents due to the absence of an explicit policy. Existing approaches include individual exploration based on uncertainty towards the system and collective exploration through behavioral diversity among agents. However, the introduction of additional structures often leads to reduced training efficiency and infeasible integration of these methods. In this paper, we propose Adaptive exploration via Identity Recognition~(AIR), which consists of two adversarial components: a classifier that recognizes agent identities from their trajectories, and an action selector that adaptively adjusts the mode and degree of exploration. We theoretically prove that AIR can facilitate both individual and collective exploration during training, and experiments also demonstrate the efficiency and effectiveness of AIR across various tasks.
AIR: Unifying Individual and Cooperative Exploration in Collective Multi-Agent Reinforcement Learning
Dec 20, 2024Exploration in cooperative multi-agent reinforcement learning (MARL) remains challenging for value-based agents due to the absence of an explicit policy. Existing approaches include individual exploration based on uncertainty towards the system and collective exploration through behavioral diversity among agents. However, the introduction of additional structures often leads to reduced training efficiency and infeasible integration of these methods. In this paper, we propose Adaptive exploration via Identity Recognition~(AIR), which consists of two adversarial components: a classifier that recognizes agent identities from their trajectories, and an action selector that adaptively adjusts the mode and degree of exploration. We theoretically prove that AIR can facilitate both individual and collective exploration during training, and experiments also demonstrate the efficiency and effectiveness of AIR across various tasks.
Beyond Local Views: Global State Inference with Diffusion Models for Cooperative Multi-Agent Reinforcement Learning
Aug 18, 2024



In partially observable multi-agent systems, agents typically only have access to local observations. This severely hinders their ability to make precise decisions, particularly during decentralized execution. To alleviate this problem and inspired by image outpainting, we propose State Inference with Diffusion Models (SIDIFF), which uses diffusion models to reconstruct the original global state based solely on local observations. SIDIFF consists of a state generator and a state extractor, which allow agents to choose suitable actions by considering both the reconstructed global state and local observations. In addition, SIDIFF can be effortlessly incorporated into current multi-agent reinforcement learning algorithms to improve their performance. Finally, we evaluated SIDIFF on different experimental platforms, including Multi-Agent Battle City (MABC), a novel and flexible multi-agent reinforcement learning environment we developed. SIDIFF achieved desirable results and outperformed other popular algorithms.
Verco: Learning Coordinated Verbal Communication for Multi-agent Reinforcement Learning
Apr 27, 2024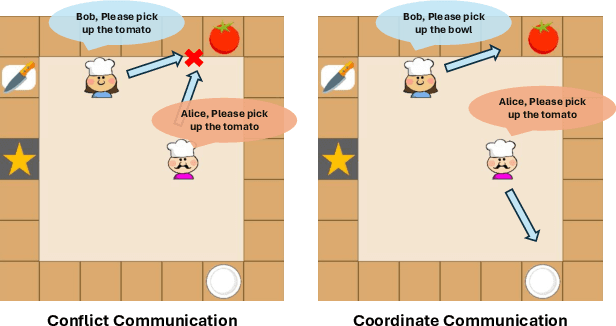
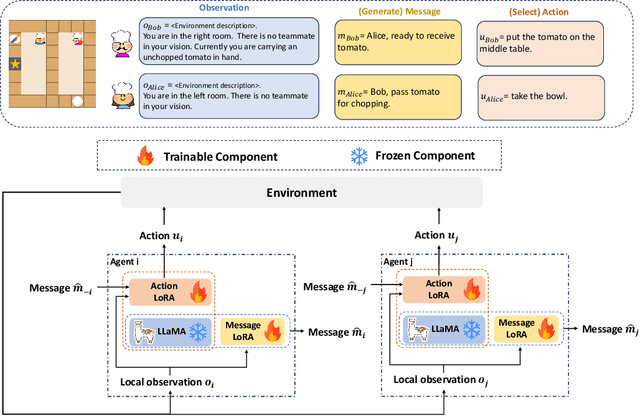
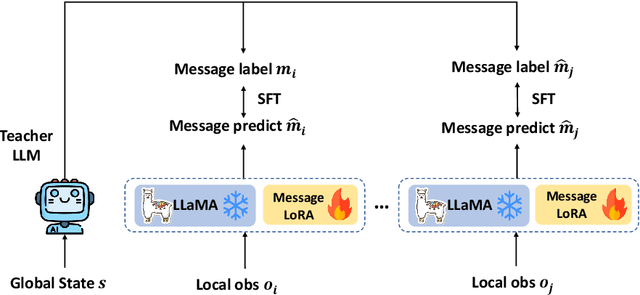
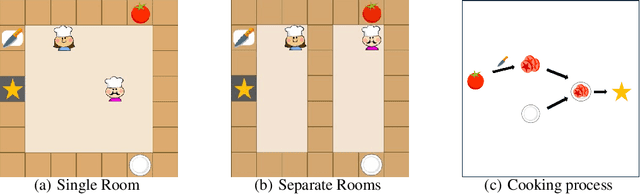
In recent years, multi-agent reinforcement learning algorithms have made significant advancements in diverse gaming environments, leading to increased interest in the broader application of such techniques. To address the prevalent challenge of partial observability, communication-based algorithms have improved cooperative performance through the sharing of numerical embedding between agents. However, the understanding of the formation of collaborative mechanisms is still very limited, making designing a human-understandable communication mechanism a valuable problem to address. In this paper, we propose a novel multi-agent reinforcement learning algorithm that embeds large language models into agents, endowing them with the ability to generate human-understandable verbal communication. The entire framework has a message module and an action module. The message module is responsible for generating and sending verbal messages to other agents, effectively enhancing information sharing among agents. To further enhance the message module, we employ a teacher model to generate message labels from the global view and update the student model through Supervised Fine-Tuning (SFT). The action module receives messages from other agents and selects actions based on current local observations and received messages. Experiments conducted on the Overcooked game demonstrate our method significantly enhances the learning efficiency and performance of existing methods, while also providing an interpretable tool for humans to understand the process of multi-agent cooperation.
Adaptive parameter sharing for multi-agent reinforcement learning
Dec 14, 2023
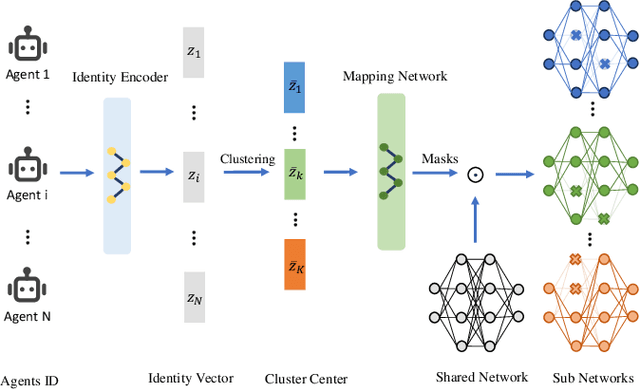
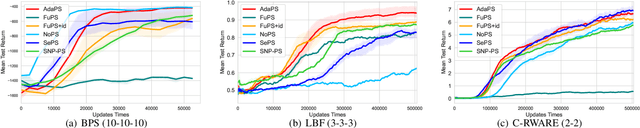
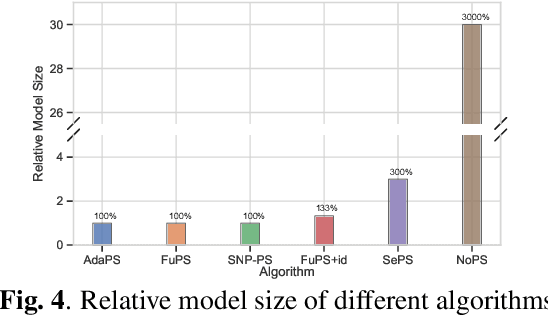
Parameter sharing, as an important technique in multi-agent systems, can effectively solve the scalability issue in large-scale agent problems. However, the effectiveness of parameter sharing largely depends on the environment setting. When agents have different identities or tasks, naive parameter sharing makes it difficult to generate sufficiently differentiated strategies for agents. Inspired by research pertaining to the brain in biology, we propose a novel parameter sharing method. It maps each type of agent to different regions within a shared network based on their identity, resulting in distinct subnetworks. Therefore, our method can increase the diversity of strategies among different agents without introducing additional training parameters. Through experiments conducted in multiple environments, our method has shown better performance than other parameter sharing methods.
Mastering Complex Coordination through Attention-based Dynamic Graph
Dec 07, 2023The coordination between agents in multi-agent systems has become a popular topic in many fields. To catch the inner relationship between agents, the graph structure is combined with existing methods and improves the results. But in large-scale tasks with numerous agents, an overly complex graph would lead to a boost in computational cost and a decline in performance. Here we present DAGMIX, a novel graph-based value factorization method. Instead of a complete graph, DAGMIX generates a dynamic graph at each time step during training, on which it realizes a more interpretable and effective combining process through the attention mechanism. Experiments show that DAGMIX significantly outperforms previous SOTA methods in large-scale scenarios, as well as achieving promising results on other tasks.
Controlling Large Language Model-based Agents for Large-Scale Decision-Making: An Actor-Critic Approach
Nov 23, 2023



The significant advancements in large language models (LLMs) have presented novel opportunities for tackling planning and decision-making within multi-agent systems. However, as the number of agents increases, the issues of hallucination in LLMs and coordination in multi-agent systems (MAS) have become increasingly pronounced. Additionally, the efficient utilization of tokens becomes a critical consideration when employing LLMs to facilitate the interactions of large numbers of agents. In this paper, we present a novel framework aimed at enhancing coordination and decision-making capabilities of LLMs within large-scale multi-agent environments. Our approach draws inspiration from the actor-critic framework employed in multi-agent reinforcement learning, and we develop a modular and token-efficient solution that effectively addresses challenges presented by LLMs and MAS. Through evaluations conducted in experiments involving system resource allocation and robot grid transportation, we demonstrate the considerable advantages afforded by our proposed approach.
Stackelberg Decision Transformer for Asynchronous Action Coordination in Multi-Agent Systems
May 13, 2023Asynchronous action coordination presents a pervasive challenge in Multi-Agent Systems (MAS), which can be represented as a Stackelberg game (SG). However, the scalability of existing Multi-Agent Reinforcement Learning (MARL) methods based on SG is severely constrained by network structures or environmental limitations. To address this issue, we propose the Stackelberg Decision Transformer (STEER), a heuristic approach that resolves the difficulties of hierarchical coordination among agents. STEER efficiently manages decision-making processes in both spatial and temporal contexts by incorporating the hierarchical decision structure of SG, the modeling capability of autoregressive sequence models, and the exploratory learning methodology of MARL. Our research contributes to the development of an effective and adaptable asynchronous action coordination method that can be widely applied to various task types and environmental configurations in MAS. Experimental results demonstrate that our method can converge to Stackelberg equilibrium solutions and outperforms other existing methods in complex scenarios.
From Explicit Communication to Tacit Cooperation:A Novel Paradigm for Cooperative MARL
Apr 28, 2023
Centralized training with decentralized execution (CTDE) is a widely-used learning paradigm that has achieved significant success in complex tasks. However, partial observability issues and the absence of effectively shared signals between agents often limit its effectiveness in fostering cooperation. While communication can address this challenge, it simultaneously reduces the algorithm's practicality. Drawing inspiration from human team cooperative learning, we propose a novel paradigm that facilitates a gradual shift from explicit communication to tacit cooperation. In the initial training stage, we promote cooperation by sharing relevant information among agents and concurrently reconstructing this information using each agent's local trajectory. We then combine the explicitly communicated information with the reconstructed information to obtain mixed information. Throughout the training process, we progressively reduce the proportion of explicitly communicated information, facilitating a seamless transition to fully decentralized execution without communication. Experimental results in various scenarios demonstrate that the performance of our method without communication can approaches or even surpasses that of QMIX and communication-based methods.