 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoUni: A Unified Model for Generating Geometry Diagrams, Problems and Problem Solutions
Apr 14, 2025
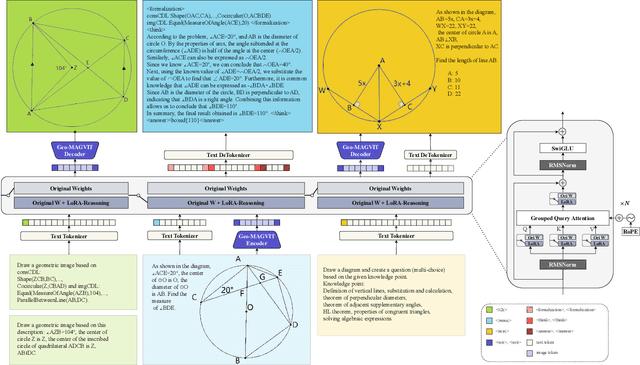

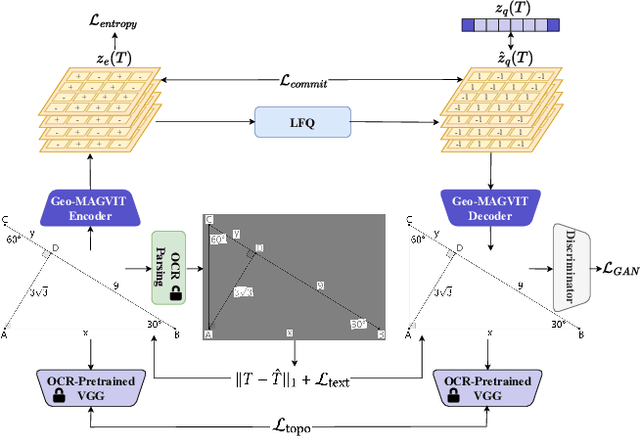
We propose GeoUni, the first unified geometry expert model capable of generating problem solutions and diagrams within a single framework in a way that enables the creation of unique and individualized geometry problems. Traditionally, solving geometry problems and generating diagrams have been treated as separate tasks in machine learning, with no models successfully integrating both to support problem creation. However, we believe that mastery in geometry requires frictionless integration of all of these skills, from solving problems to visualizing geometric relationships, and finally, crafting tailored problems. Our extensive experiments demonstrate that GeoUni, with only 1.5B parameters, achieves performance comparable to larger models such as DeepSeek-R1 with 671B parameters in geometric reasoning tasks. GeoUni also excels in generating precise geometric diagrams, surpassing both text-to-image models and unified models, including the GPT-4o image generation. Most importantly, GeoUni is the only model capable of successfully generating textual problems with matching diagrams based on specific knowledge points, thus offering a wider range of capabilities that extend beyond current models.
Head-Aware KV Cache Compression for Efficient Visual Autoregressive Modeling
Apr 12, 2025Visual Autoregressive (VAR) models have emerged as a powerful approach for multi-modal content creation, offering high efficiency and quality across diverse multimedia applications. However, they face significant memory bottlenecks due to extensive KV cache accumulation during inference. Existing KV cache compression techniques for large language models are suboptimal for VAR models due to, as we identify in this paper, two distinct categories of attention heads in VAR models: Structural Heads, which preserve spatial coherence through diagonal attention patterns, and Contextual Heads, which maintain semantic consistency through vertical attention patterns. These differences render single-strategy KV compression techniques ineffective for VAR models. To address this, we propose HACK, a training-free Head-Aware Compression method for KV cache. HACK allocates asymmetric cache budgets and employs pattern-specific compression strategies tailored to the essential characteristics of each head category. Experiments on Infinity-2B, Infinity-8B, and VAR-d30 demonstrate its effectiveness in text-to-image and class-conditional generation tasks. HACK can hack down up to 50\% and 70\% of cache with minimal performance degradation for VAR-d30 and Infinity-8B, respectively. Even with 70\% and 90\% KV cache compression in VAR-d30 and Infinity-8B, HACK still maintains high-quality generation while reducing memory usage by 44.2\% and 58.9\%, respectively.
AIR: Unifying Individual and Collective Exploration in Cooperative Multi-Agent Reinforcement Learning
Dec 30, 2024Exploration in cooperative multi-agent reinforcement learning (MARL) remains challenging for value-based agents due to the absence of an explicit policy. Existing approaches include individual exploration based on uncertainty towards the system and collective exploration through behavioral diversity among agents. However, the introduction of additional structures often leads to reduced training efficiency and infeasible integration of these methods. In this paper, we propose Adaptive exploration via Identity Recognition~(AIR), which consists of two adversarial components: a classifier that recognizes agent identities from their trajectories, and an action selector that adaptively adjusts the mode and degree of exploration. We theoretically prove that AIR can facilitate both individual and collective exploration during training, and experiments also demonstrate the efficiency and effectiveness of AIR across various tasks.
AIR: Unifying Individual and Cooperative Exploration in Collective Multi-Agent Reinforcement Learning
Dec 20, 2024Exploration in cooperative multi-agent reinforcement learning (MARL) remains challenging for value-based agents due to the absence of an explicit policy. Existing approaches include individual exploration based on uncertainty towards the system and collective exploration through behavioral diversity among agents. However, the introduction of additional structures often leads to reduced training efficiency and infeasible integration of these methods. In this paper, we propose Adaptive exploration via Identity Recognition~(AIR), which consists of two adversarial components: a classifier that recognizes agent identities from their trajectories, and an action selector that adaptively adjusts the mode and degree of exploration. We theoretically prove that AIR can facilitate both individual and collective exploration during training, and experiments also demonstrate the efficiency and effectiveness of AIR across various tasks.
Diagram Formalization Enhanced Multi-Modal Geometry Problem Solver
Sep 09, 2024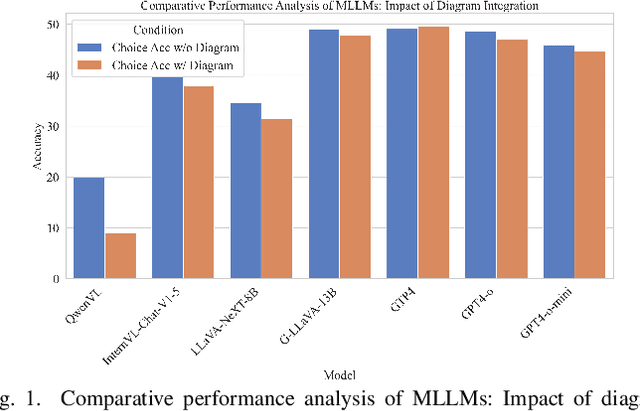

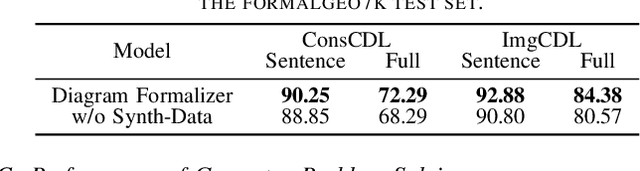

Mathematical reasoning remains an ongoing challenge for AI models, especially for geometry problems that require both linguistic and visual signals. As the vision encoders of most MLLMs are trained on natural scenes, they often struggle to understand geometric diagrams, performing no better in geometry problem solving than LLMs that only process text. This limitation is amplified by the lack of effective methods for representing geometric relationships. To address these issues, we introduce the Diagram Formalization Enhanced Geometry Problem Solver (DFE-GPS), a new framework that integrates visual features, geometric formal language, and natural language representations. We propose a novel synthetic data approach and create a large-scale geometric dataset, SynthGeo228K, annotated with both formal and natural language captions, designed to enhance the vision encoder for a better understanding of geometric structures. Our framework improves MLLMs' ability to process geometric diagrams and extends their application to open-ended tasks on the formalgeo7k dataset.
Seismic Fault SAM: Adapting SAM with Lightweight Modules and 2.5D Strategy for Fault Detection
Jul 19, 2024



Seismic fault detection holds significant geographical and practical application value, aiding experts in subsurface structure interpretation and resource exploration. Despite some progress made by automated methods based on deep learning, research in the seismic domain faces significant challenges, particularly because it is difficult to obtain high-quality, large-scale, open-source, and diverse datasets, which hinders the development of general foundation models. Therefore, this paper proposes Seismic Fault SAM, which, for the first time, applies the general pre-training foundation model-Segment Anything Model (SAM)-to seismic fault interpretation. This method aligns the universal knowledge learned from a vast amount of images with the seismic domain tasks through an Adapter design. Specifically, our innovative points include designing lightweight Adapter modules, freezing most of the pre-training weights, and only updating a small number of parameters to allow the model to converge quickly and effectively learn fault features; combining 2.5D input strategy to capture 3D spatial patterns with 2D models; integrating geological constraints into the model through prior-based data augmentation techniques to enhance the model's generalization capability. Experimental results on the largest publicly available seismic dataset, Thebe, show that our method surpasses existing 3D models on both OIS and ODS metrics, achieving state-of-the-art performance and providing an effective extension scheme for other seismic domain downstream tasks that lack labeled data.
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
May 09, 2024



Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
Mastering Complex Coordination through Attention-based Dynamic Graph
Dec 07, 2023The coordination between agents in multi-agent systems has become a popular topic in many fields. To catch the inner relationship between agents, the graph structure is combined with existing methods and improves the results. But in large-scale tasks with numerous agents, an overly complex graph would lead to a boost in computational cost and a decline in performance. Here we present DAGMIX, a novel graph-based value factorization method. Instead of a complete graph, DAGMIX generates a dynamic graph at each time step during training, on which it realizes a more interpretable and effective combining process through the attention mechanism. Experiments show that DAGMIX significantly outperforms previous SOTA methods in large-scale scenarios, as well as achieving promising results on other tasks.
FaultSeg Swin-UNETR: Transformer-Based Self-Supervised Pretraining Model for Fault Recognition
Oct 27, 2023This paper introduces an approach to enhance seismic fault recognition through self-supervised pretraining. Seismic fault interpretation holds great significance in the fields of geophysics and geology. However, conventional methods for seismic fault recognition encounter various issues, including dependence on data quality and quantity, as well as susceptibility to interpreter subjectivity. Currently, automated fault recognition methods proposed based on small synthetic datasets experience performance degradation when applied to actual seismic data. To address these challenges, we have introduced the concept of self-supervised learning, utilizing a substantial amount of relatively easily obtainable unlabeled seismic data for pretraining. Specifically, we have employed the Swin Transformer model as the core network and employed the SimMIM pretraining task to capture unique features related to discontinuities in seismic data. During the fine-tuning phase, inspired by edge detection techniques, we have also refined the structure of the Swin-UNETR model, enabling multiscale decoding and fusion for more effective fault detection. Experimental results demonstrate that our proposed method attains state-of-the-art performance on the Thebe dataset, as measured by the OIS and ODS metrics.
DenseMP: Unsupervised Dense Pre-training for Few-shot Medical Image Segmentation
Jul 13, 2023Few-shot medical image semantic segmentation is of paramount importance in the domain of medical image analysis. However, existing methodologies grapple with the challenge of data scarcity during the training phase, leading to over-fitting. To mitigate this issue, we introduce a novel Unsupervised Dense Few-shot Medical Image Segmentation Model Training Pipeline (DenseMP) that capitalizes on unsupervised dense pre-training. DenseMP is composed of two distinct stages: (1) segmentation-aware dense contrastive pre-training, and (2) few-shot-aware superpixel guided dense pre-training. These stages collaboratively yield a pre-trained initial model specifically designed for few-shot medical image segmentation, which can subsequently be fine-tuned on the target dataset. Our proposed pipeline significantly enhances the performance of the widely recognized few-shot segmentation model, PA-Net, achieving state-of-the-art results on the Abd-CT and Abd-MRI datasets. Code will be released after acceptance.