 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOAEsV2-7B/72B: Full-Pipeline Optimization for State-Owned Enterprise LLMs via Continual Pre-Training, Domain-Progressive SFT and Distillation-Enhanced Speculative Decoding
May 07, 2025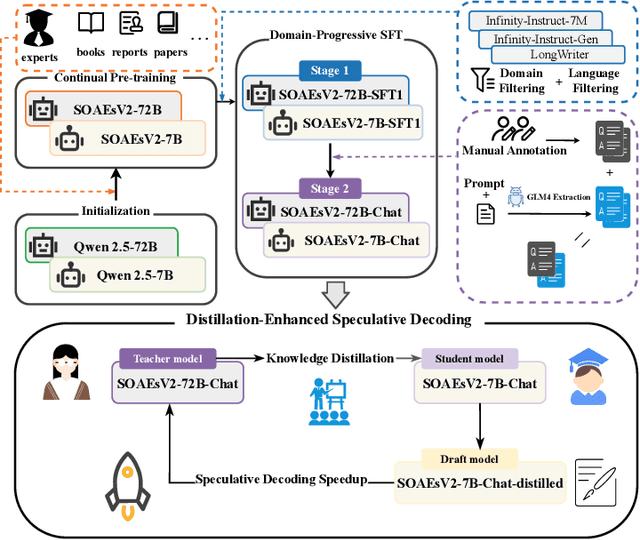
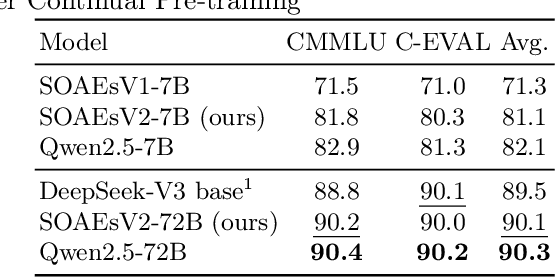
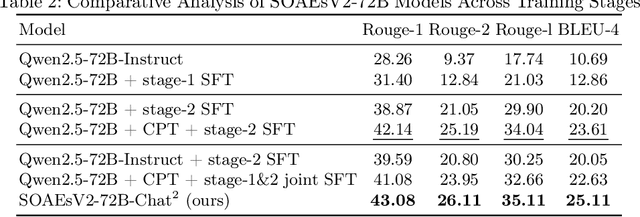
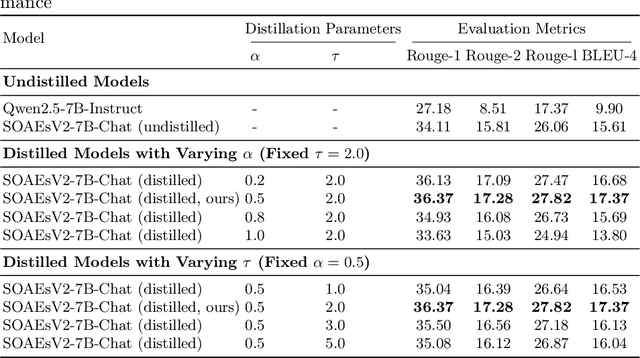
This study addresses key challenges in developing domain-specific large language models (LLMs) for Chinese state-owned assets and enterprises (SOAEs), where current approaches face three limitations: 1) constrained model capacity that limits knowledge integration and cross-task adaptability; 2) excessive reliance on domain-specific supervised fine-tuning (SFT) data, which neglects the broader applicability of general language patterns; and 3) inefficient inference acceleration for large models processing long contexts. In this work, we propose SOAEsV2-7B/72B, a specialized LLM series developed via a three-phase framework: 1) continual pre-training integrates domain knowledge while retaining base capabilities; 2) domain-progressive SFT employs curriculum-based learning strategy, transitioning from weakly relevant conversational data to expert-annotated SOAEs datasets to optimize domain-specific tasks; 3) distillation-enhanced speculative decoding accelerates inference via logit distillation between 72B target and 7B draft models, achieving 1.39-1.52$\times$ speedup without quality loss. Experimental results demonstrate that our domain-specific pre-training phase maintains 99.8% of original general language capabilities while significantly improving domain performance, resulting in a 1.08$\times$ improvement in Rouge-1 score and a 1.17$\times$ enhancement in BLEU-4 score. Ablation studies further show that domain-progressive SFT outperforms single-stage training, achieving 1.02$\times$ improvement in Rouge-1 and 1.06$\times$ in BLEU-4. Our work introduces a comprehensive, full-pipeline approach for optimizing SOAEs LLMs, bridging the gap between general language capabilities and domain-specific expertise.
GeoUni: A Unified Model for Generating Geometry Diagrams, Problems and Problem Solutions
Apr 14, 2025
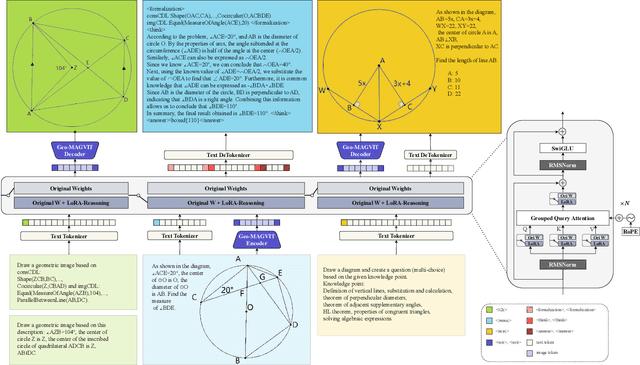

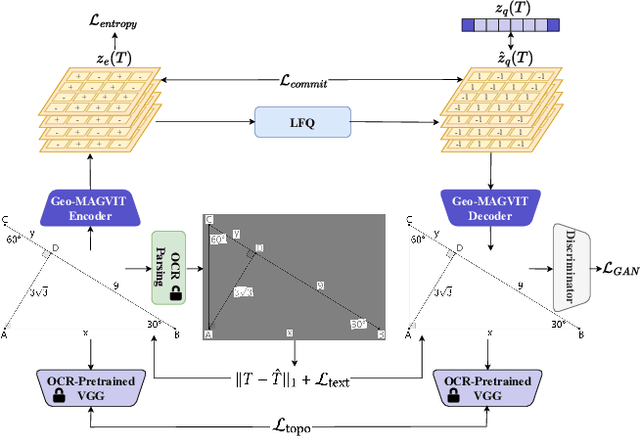
We propose GeoUni, the first unified geometry expert model capable of generating problem solutions and diagrams within a single framework in a way that enables the creation of unique and individualized geometry problems. Traditionally, solving geometry problems and generating diagrams have been treated as separate tasks in machine learning, with no models successfully integrating both to support problem creation. However, we believe that mastery in geometry requires frictionless integration of all of these skills, from solving problems to visualizing geometric relationships, and finally, crafting tailored problems. Our extensive experiments demonstrate that GeoUni, with only 1.5B parameters, achieves performance comparable to larger models such as DeepSeek-R1 with 671B parameters in geometric reasoning tasks. GeoUni also excels in generating precise geometric diagrams, surpassing both text-to-image models and unified models, including the GPT-4o image generation. Most importantly, GeoUni is the only model capable of successfully generating textual problems with matching diagrams based on specific knowledge points, thus offering a wider range of capabilities that extend beyond current models.
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
Mar 06, 2025Transformers have become the de facto architecture for a wide range of machine learning tasks, particularly in large language models (LLMs). Despite their remarkable performance, challenges remain in training deep transformer networks, especially regarding the location of layer normalization. While Pre-Norm structures facilitate easier training due to their more prominent identity path, they often yield suboptimal performance compared to Post-Norm. In this paper, we propose $\textbf{HybridNorm}$, a straightforward yet effective hybrid normalization strategy that integrates the advantages of both Pre-Norm and Post-Norm approaches. Specifically, HybridNorm employs QKV normalization within the attention mechanism and Post-Norm in the feed-forward network (FFN) of each transformer block. This design not only stabilizes training but also enhances performance, particularly in the context of LLMs. Comprehensive experiments in both dense and sparse architectures show that HybridNorm consistently outperforms both Pre-Norm and Post-Norm approaches, achieving state-of-the-art results across various benchmarks. These findings highlight the potential of HybridNorm as a more stable and effective technique for improving the training and performance of deep transformer models. %Code will be made publicly available. Code is available at https://github.com/BryceZhuo/HybridNorm.
Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models
Nov 06, 2024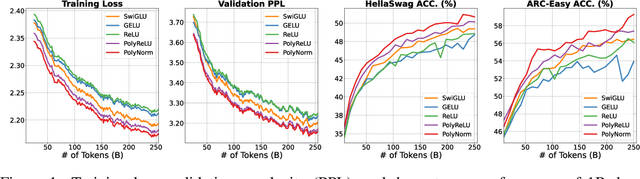
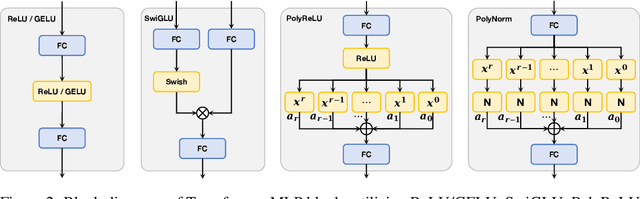

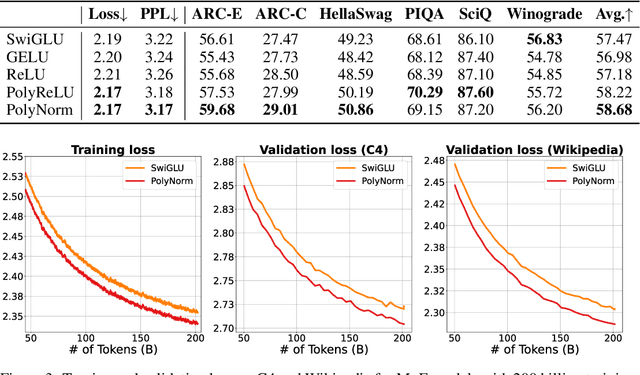
Transformers have found extensive applications across various domains due to the powerful fitting capabilities. This success can be partially attributed to their inherent nonlinearity. Thus, in addition to the ReLU function employed in the original transformer architecture, researchers have explored alternative modules such as GeLU and SwishGLU to enhance nonlinearity and thereby augment representational capacity. In this paper, we propose a novel category of polynomial composition activations (PolyCom), designed to optimize the dynamics of transformers. Theoretically, we provide a comprehensive mathematical analysis of PolyCom, highlighting its enhanced expressivity and efficacy relative to other activation functions. Notably, we demonstrate that networks incorporating PolyCom achieve the $\textbf{optimal approximation rate}$, indicating that PolyCom networks require minimal parameters to approximate general smooth functions in Sobolev spaces. We conduct empirical experiments on the pre-training configurations of large language models (LLMs), including both dense and sparse architectures. By substituting conventional activation functions with PolyCom, we enable LLMs to capture higher-order interactions within the data, thus improving performance metrics in terms of accuracy and convergence rates. Extensive experimental results demonstrate the effectiveness of our method, showing substantial improvements over other activation functions. Code is available at https://github.com/BryceZhuo/PolyCom.
FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
Oct 09, 2024
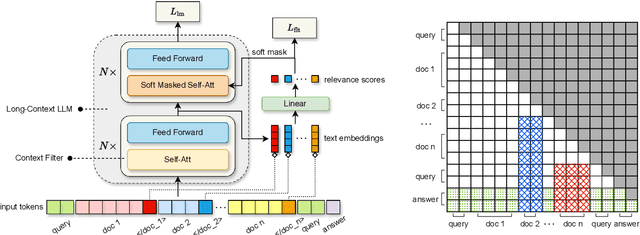

The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.
Diagram Formalization Enhanced Multi-Modal Geometry Problem Solver
Sep 09, 2024

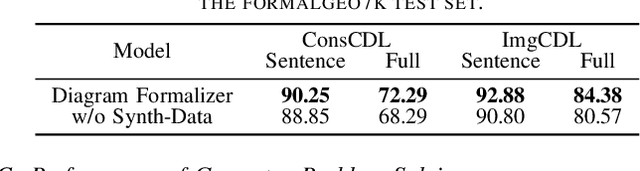

Mathematical reasoning remains an ongoing challenge for AI models, especially for geometry problems that require both linguistic and visual signals. As the vision encoders of most MLLMs are trained on natural scenes, they often struggle to understand geometric diagrams, performing no better in geometry problem solving than LLMs that only process text. This limitation is amplified by the lack of effective methods for representing geometric relationships. To address these issues, we introduce the Diagram Formalization Enhanced Geometry Problem Solver (DFE-GPS), a new framework that integrates visual features, geometric formal language, and natural language representations. We propose a novel synthetic data approach and create a large-scale geometric dataset, SynthGeo228K, annotated with both formal and natural language captions, designed to enhance the vision encoder for a better understanding of geometric structures. Our framework improves MLLMs' ability to process geometric diagrams and extends their application to open-ended tasks on the formalgeo7k dataset.
Seismic Fault SAM: Adapting SAM with Lightweight Modules and 2.5D Strategy for Fault Detection
Jul 19, 2024



Seismic fault detection holds significant geographical and practical application value, aiding experts in subsurface structure interpretation and resource exploration. Despite some progress made by automated methods based on deep learning, research in the seismic domain faces significant challenges, particularly because it is difficult to obtain high-quality, large-scale, open-source, and diverse datasets, which hinders the development of general foundation models. Therefore, this paper proposes Seismic Fault SAM, which, for the first time, applies the general pre-training foundation model-Segment Anything Model (SAM)-to seismic fault interpretation. This method aligns the universal knowledge learned from a vast amount of images with the seismic domain tasks through an Adapter design. Specifically, our innovative points include designing lightweight Adapter modules, freezing most of the pre-training weights, and only updating a small number of parameters to allow the model to converge quickly and effectively learn fault features; combining 2.5D input strategy to capture 3D spatial patterns with 2D models; integrating geological constraints into the model through prior-based data augmentation techniques to enhance the model's generalization capability. Experimental results on the largest publicly available seismic dataset, Thebe, show that our method surpasses existing 3D models on both OIS and ODS metrics, achieving state-of-the-art performance and providing an effective extension scheme for other seismic domain downstream tasks that lack labeled data.
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
May 09, 2024



Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
FaultSeg Swin-UNETR: Transformer-Based Self-Supervised Pretraining Model for Fault Recognition
Oct 27, 2023This paper introduces an approach to enhance seismic fault recognition through self-supervised pretraining. Seismic fault interpretation holds great significance in the fields of geophysics and geology. However, conventional methods for seismic fault recognition encounter various issues, including dependence on data quality and quantity, as well as susceptibility to interpreter subjectivity. Currently, automated fault recognition methods proposed based on small synthetic datasets experience performance degradation when applied to actual seismic data. To address these challenges, we have introduced the concept of self-supervised learning, utilizing a substantial amount of relatively easily obtainable unlabeled seismic data for pretraining. Specifically, we have employed the Swin Transformer model as the core network and employed the SimMIM pretraining task to capture unique features related to discontinuities in seismic data. During the fine-tuning phase, inspired by edge detection techniques, we have also refined the structure of the Swin-UNETR model, enabling multiscale decoding and fusion for more effective fault detection. Experimental results demonstrate that our proposed method attains state-of-the-art performance on the Thebe dataset, as measured by the OIS and ODS metrics.
Towards a Unified Theoretical Understanding of Non-contrastive Learning via Rank Differential Mechanism
Mar 04, 2023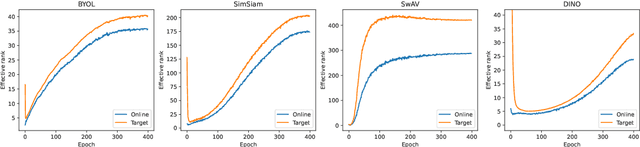
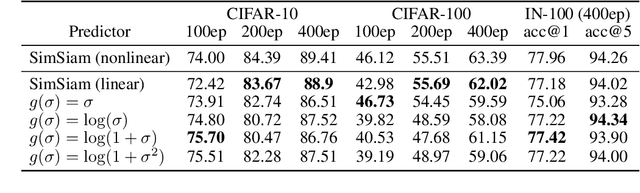
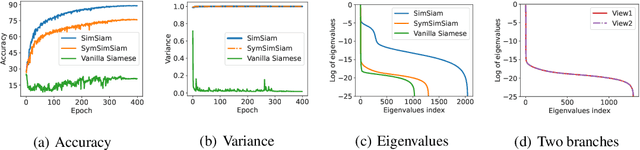
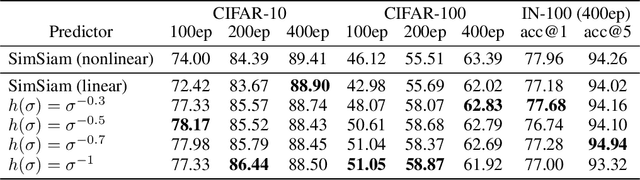
Recently, a variety of methods under the name of non-contrastive learning (like BYOL, SimSiam, SwAV, DINO) show that when equipped with some asymmetric architectural designs, aligning positive pairs alone is sufficient to attain good performance in self-supervised visual learning. Despite some understandings of some specific modules (like the predictor in BYOL), there is yet no unified theoretical understanding of how these seemingly different asymmetric designs can all avoid feature collapse, particularly considering methods that also work without the predictor (like DINO). In this work, we propose a unified theoretical understanding for existing variants of non-contrastive learning. Our theory named Rank Differential Mechanism (RDM) shows that all these asymmetric designs create a consistent rank difference in their dual-branch output features. This rank difference will provably lead to an improvement of effective dimensionality and alleviate either complete or dimensional feature collapse. Different from previous theories, our RDM theory is applicable to different asymmetric designs (with and without the predictor), and thus can serve as a unified understanding of existing non-contrastive learning methods. Besides, our RDM theory also provides practical guidelines for designing many new non-contrastive variants. We show that these variants indeed achieve comparable performance to existing methods on benchmark datasets, and some of them even outperform the baselines. Our code is available at \url{https://github.com/PKU-ML/Rank-Differential-Mechanism}.