 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Depths Attention
Mar 16, 2026Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
Hierarchical Testing of a Hybrid Machine Learning-Physics Global Atmosphere Model
Feb 11, 2026Machine learning (ML)-based models have demonstrated high skill and computational efficiency, often outperforming conventional physics-based models in weather and subseasonal predictions. While prior studies have assessed their fidelity in capturing synoptic-scale atmospheric dynamics, their performance across timescales and under out-of-distribution forcing, such as +3K or +4K uniform-warming forcings, and the sources of biases remain elusive, to establish the model reliability for Earth science. Here, we design three sets of experiments targeting synoptic-scale phenomena, interannual variability, and out-of-distribution uniform-warming forcings. We evaluate the Neural General Circulation Model (NeuralGCM), a hybrid model integrating a dynamical core with ML-based component, against observations and physics-based Earth system models (ESMs). At the synoptic scale, NeuralGCM captures the evolution and propagation of extratropical cyclones with performance comparable to ESMs. At the interannual scale, when forced by El Niño-Southern Oscillation sea surface temperature (SST) anomalies, NeuralGCM successfully reproduces associated teleconnection patterns but exhibits deficiencies in capturing nonlinear response. Under out-of-distribution uniform-warming forcings, NeuralGCM simulates similar responses in global-average temperature and precipitation and reproduces large-scale tropospheric circulation features similar to those in ESMs. Notable weaknesses include overestimating the tracks and spatial extent of extratropical cyclones, biases in the teleconnected wave train triggered by tropical SST anomalies, and differences in upper-level warming and stratospheric circulation responses to SST warming compared to physics-based ESMs. The causes of these weaknesses were explored.
Searth Transformer: A Transformer Architecture Incorporating Earth's Geospheric Physical Priors for Global Mid-Range Weather Forecasting
Jan 14, 2026Accurate global medium-range weather forecasting is fundamental to Earth system science. Most existing Transformer-based forecasting models adopt vision-centric architectures that neglect the Earth's spherical geometry and zonal periodicity. In addition, conventional autoregressive training is computationally expensive and limits forecast horizons due to error accumulation. To address these challenges, we propose the Shifted Earth Transformer (Searth Transformer), a physics-informed architecture that incorporates zonal periodicity and meridional boundaries into window-based self-attention for physically consistent global information exchange. We further introduce a Relay Autoregressive (RAR) fine-tuning strategy that enables learning long-range atmospheric evolution under constrained memory and computational budgets. Based on these methods, we develop YanTian, a global medium-range weather forecasting model. YanTian achieves higher accuracy than the high-resolution forecast of the European Centre for Medium-Range Weather Forecasts and performs competitively with state-of-the-art AI models at one-degree resolution, while requiring roughly 200 times lower computational cost than standard autoregressive fine-tuning. Furthermore, YanTian attains a longer skillful forecast lead time for Z500 (10.3 days) than HRES (9 days). Beyond weather forecasting, this work establishes a robust algorithmic foundation for predictive modeling of complex global-scale geophysical circulation systems, offering new pathways for Earth system science.
Acquiring Common Chinese Emotional Events Using Large Language Model
Nov 07, 2025Knowledge about emotional events is an important kind of knowledge which has been applied to improve the effectiveness of different applications. However, emotional events cannot be easily acquired, especially common or generalized emotional events that are context-independent. The goal of this paper is to obtain common emotional events in Chinese language such as "win a prize" and "be criticized". Our approach begins by collecting a comprehensive list of Chinese emotional event indicators. Then, we generate emotional events by prompting a Chinese large language model (LLM) using these indicators. To ensure the quality of these emotional events, we train a filter to discard invalid generated results. We also classify these emotional events as being positive events and negative events using different techniques. Finally, we harvest a total of 102,218 high-quality common emotional events with sentiment polarity labels, which is the only large-scale commonsense knowledge base of emotional events in Chinese language. Intrinsic evaluation results show that the proposed method in this paper can be effectively used to acquire common Chinese emotional events. An extrinsic use case also demonstrates the strong potential of common emotional events in the field of emotion cause extraction (ECE). Related resources including emotional event indicators and emotional events will be released after the publication of this paper.
VGR: Visual Grounded Reasoning
Jun 16, 2025In the field of multimodal chain-of-thought (CoT) reasoning, existing approaches predominantly rely on reasoning on pure language space, which inherently suffers from language bias and is largely confined to math or science domains. This narrow focus limits their ability to handle complex visual reasoning tasks that demand comprehensive understanding of image details. To address these limitations, this paper introduces VGR, a novel reasoning multimodal large language model (MLLM) with enhanced fine-grained visual perception capabilities. Unlike traditional MLLMs that answer the question or reasoning solely on the language space, our VGR first detects relevant regions that may help to solve problems, and then provides precise answers based on replayed image regions. To achieve this, we conduct a large-scale SFT dataset called VGR -SFT that contains reasoning data with mixed vision grounding and language deduction. The inference pipeline of VGR allows the model to choose bounding boxes for visual reference and a replay stage is introduced to integrates the corresponding regions into the reasoning process, enhancing multimodel comprehension. Experiments on the LLaVA-NeXT-7B baseline show that VGR achieves superior performance on multi-modal benchmarks requiring comprehensive image detail understanding. Compared to the baseline, VGR uses only 30\% of the image token count while delivering scores of +4.1 on MMStar, +7.1 on AI2D, and a +12.9 improvement on ChartQA.
Visual Perturbation and Adaptive Hard Negative Contrastive Learning for Compositional Reasoning in Vision-Language Models
May 21, 2025Vision-Language Models (VLMs) are essential for multimodal tasks, especially compositional reasoning (CR) tasks, which require distinguishing fine-grained semantic differences between visual and textual embeddings. However, existing methods primarily fine-tune the model by generating text-based hard negative samples, neglecting the importance of image-based negative samples, which results in insufficient training of the visual encoder and ultimately impacts the overall performance of the model. Moreover, negative samples are typically treated uniformly, without considering their difficulty levels, and the alignment of positive samples is insufficient, which leads to challenges in aligning difficult sample pairs. To address these issues, we propose Adaptive Hard Negative Perturbation Learning (AHNPL). AHNPL translates text-based hard negatives into the visual domain to generate semantically disturbed image-based negatives for training the model, thereby enhancing its overall performance. AHNPL also introduces a contrastive learning approach using a multimodal hard negative loss to improve the model's discrimination of hard negatives within each modality and a dynamic margin loss that adjusts the contrastive margin according to sample difficulty to enhance the distinction of challenging sample pairs. Experiments on three public datasets demonstrate that our method effectively boosts VLMs' performance on complex CR tasks. The source code is available at https://github.com/nynu-BDAI/AHNPL.
Efficient Pretraining Length Scaling
Apr 21, 2025Recent advances in large language models have demonstrated the effectiveness of length scaling during post-training, yet its potential in pre-training remains underexplored. We present the Parallel Hidden Decoding Transformer (\textit{PHD}-Transformer), a novel framework that enables efficient length scaling during pre-training while maintaining inference efficiency. \textit{PHD}-Transformer achieves this through an innovative KV cache management strategy that distinguishes between original tokens and hidden decoding tokens. By retaining only the KV cache of original tokens for long-range dependencies while immediately discarding hidden decoding tokens after use, our approach maintains the same KV cache size as the vanilla transformer while enabling effective length scaling. To further enhance performance, we introduce two optimized variants: \textit{PHD-SWA} employs sliding window attention to preserve local dependencies, while \textit{PHD-CSWA} implements chunk-wise sliding window attention to eliminate linear growth in pre-filling time. Extensive experiments demonstrate consistent improvements across multiple benchmarks.
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
Mar 06, 2025Transformers have become the de facto architecture for a wide range of machine learning tasks, particularly in large language models (LLMs). Despite their remarkable performance, challenges remain in training deep transformer networks, especially regarding the location of layer normalization. While Pre-Norm structures facilitate easier training due to their more prominent identity path, they often yield suboptimal performance compared to Post-Norm. In this paper, we propose $\textbf{HybridNorm}$, a straightforward yet effective hybrid normalization strategy that integrates the advantages of both Pre-Norm and Post-Norm approaches. Specifically, HybridNorm employs QKV normalization within the attention mechanism and Post-Norm in the feed-forward network (FFN) of each transformer block. This design not only stabilizes training but also enhances performance, particularly in the context of LLMs. Comprehensive experiments in both dense and sparse architectures show that HybridNorm consistently outperforms both Pre-Norm and Post-Norm approaches, achieving state-of-the-art results across various benchmarks. These findings highlight the potential of HybridNorm as a more stable and effective technique for improving the training and performance of deep transformer models. %Code will be made publicly available. Code is available at https://github.com/BryceZhuo/HybridNorm.
FwNet-ECA: Facilitating Window Attention with Global Receptive Fields through Fourier Filtering Operations
Feb 25, 2025Windowed attention mechanisms were introduced to mitigate the issue of excessive computation inherent in global attention mechanisms. However, In this paper, we present FwNet-ECA, a novel method that utilizes Fourier transforms paired with learnable weight matrices to enhance the spectral features of images. This strategy facilitates inter-window connectivity, thereby maximizing the receptive field. Additionally, we incorporate the Efficient Channel Attention (ECA) module to improve communication between different channels. Instead of relying on physically shifted windows, our approach leverages frequency domain enhancement to implicitly bridge information across spatial regions. We validate our model on the iCartoonFace dataset and conduct downstream tasks on ImageNet, demonstrating that our model achieves lower parameter counts and computational overheads compared to shifted window approaches, while maintaining competitive accuracy. This work offers a more efficient and effective alternative for leveraging attention mechanisms in visual processing tasks, alleviating the challenges associated with windowed attention models. Code is available at https://github.com/qingxiaoli/FwNet-ECA.
Scale-Distribution Decoupling: Enabling Stable and Effective Training of Large Language Models
Feb 21, 2025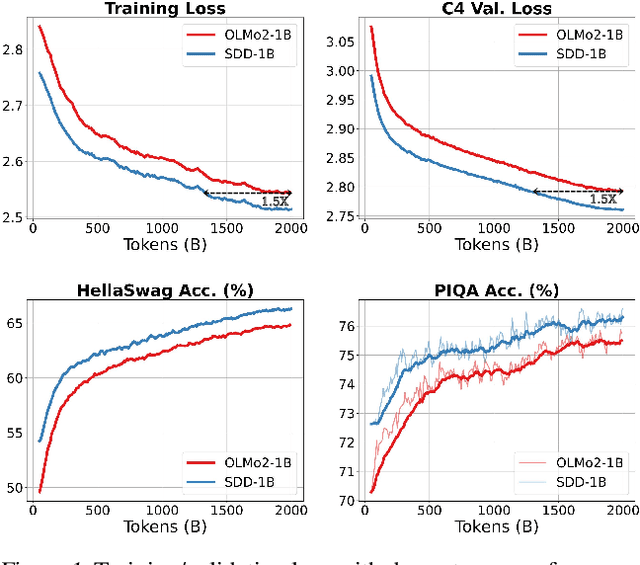
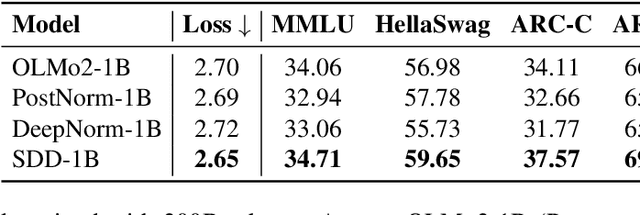
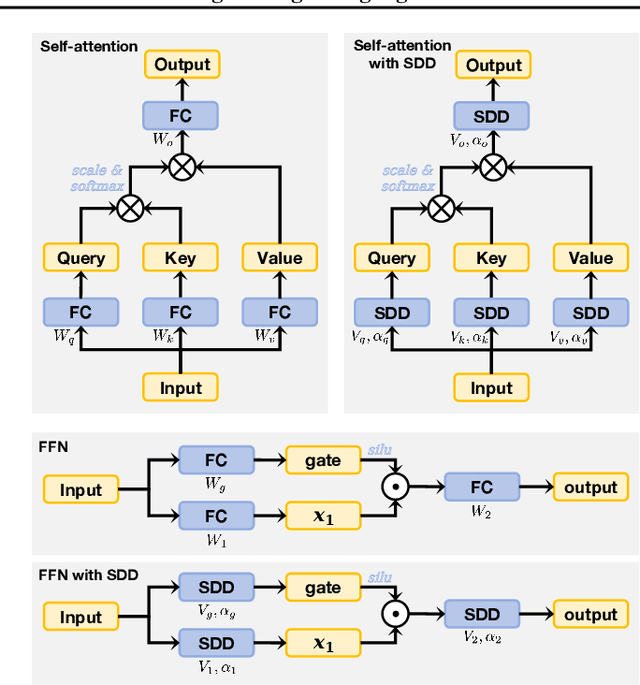
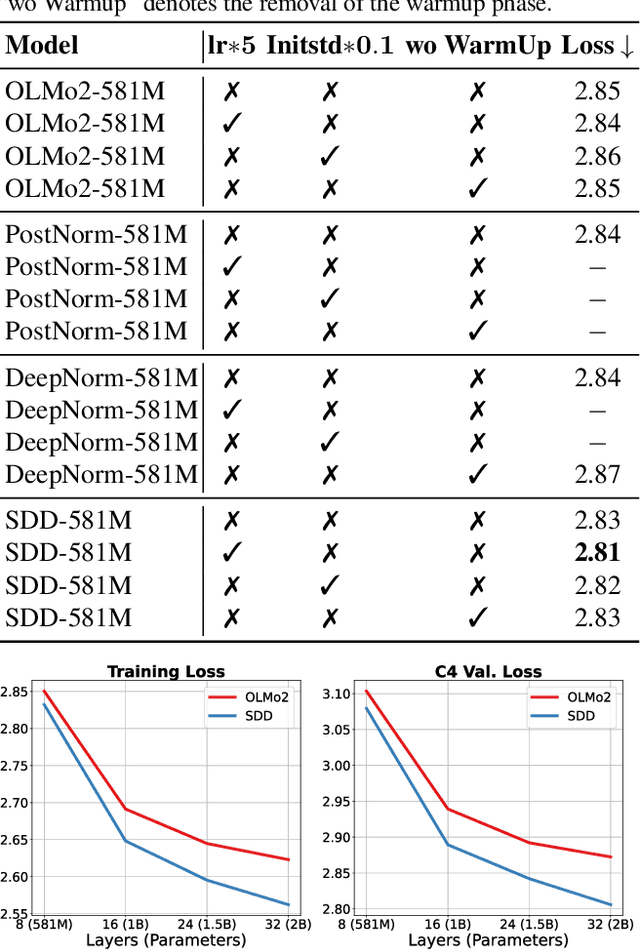
Training stability is a persistent challenge in the pre-training of large language models (LLMs), particularly for architectures such as Post-Norm Transformers, which are prone to gradient explosion and dissipation. In this paper, we propose Scale-Distribution Decoupling (SDD), a novel approach that stabilizes training by explicitly decoupling the scale and distribution of the weight matrix in fully-connected layers. SDD applies a normalization mechanism to regulate activations and a learnable scaling vector to maintain well-conditioned gradients, effectively preventing $\textbf{gradient explosion and dissipation}$. This separation improves optimization efficiency, particularly in deep networks, by ensuring stable gradient propagation. Experimental results demonstrate that our method stabilizes training across various LLM architectures and outperforms existing techniques in different normalization configurations. Furthermore, the proposed method is lightweight and compatible with existing frameworks, making it a practical solution for stabilizing LLM training. Code is available at https://github.com/kaihemo/SDD.