 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025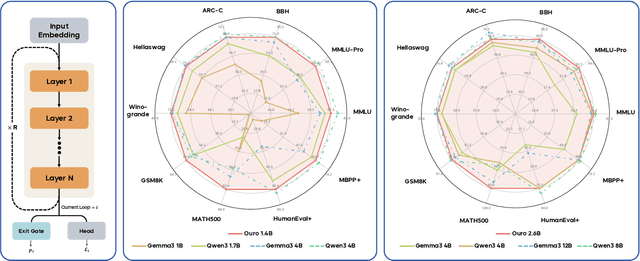
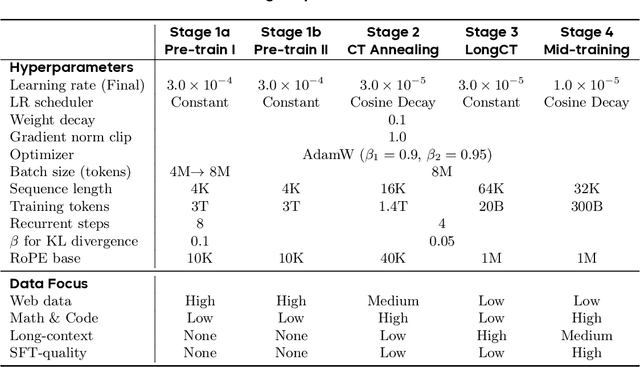
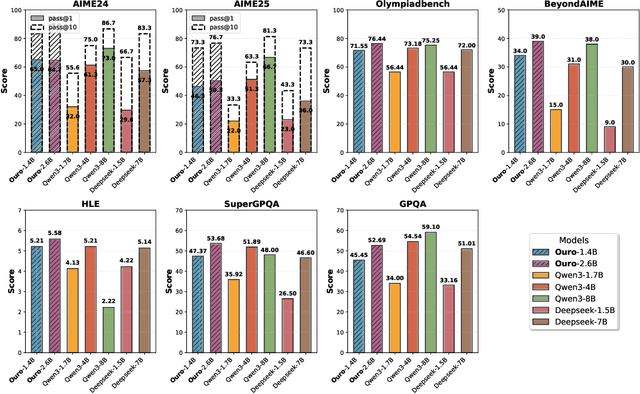

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
Frac-Connections: Fractional Extension of Hyper-Connections
Mar 18, 2025



Residual connections are central to modern deep learning architectures, enabling the training of very deep networks by mitigating gradient vanishing. Hyper-Connections recently generalized residual connections by introducing multiple connection strengths at different depths, thereby addressing the seesaw effect between gradient vanishing and representation collapse. However, Hyper-Connections increase memory access costs by expanding the width of hidden states. In this paper, we propose Frac-Connections, a novel approach that divides hidden states into multiple parts rather than expanding their width. Frac-Connections retain partial benefits of Hyper-Connections while reducing memory consumption. To validate their effectiveness, we conduct large-scale experiments on language tasks, with the largest being a 7B MoE model trained on up to 3T tokens, demonstrating that Frac-Connections significantly outperform residual connections.
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
Jan 28, 2025



Tokenization is a fundamental component of large language models (LLMs), yet its influence on model scaling and performance is not fully explored. In this paper, we introduce Over-Tokenized Transformers, a novel framework that decouples input and output vocabularies to improve language modeling performance. Specifically, our approach scales up input vocabularies to leverage multi-gram tokens. Through extensive experiments, we uncover a log-linear relationship between input vocabulary size and training loss, demonstrating that larger input vocabularies consistently enhance model performance, regardless of model size. Using a large input vocabulary, we achieve performance comparable to double-sized baselines with no additional cost. Our findings highlight the importance of tokenization in scaling laws and provide practical insight for tokenizer design, paving the way for more efficient and powerful LLMs.
Ultra-Sparse Memory Network
Nov 19, 2024



It is widely acknowledged that the performance of Transformer models is exponentially related to their number of parameters and computational complexity. While approaches like Mixture of Experts (MoE) decouple parameter count from computational complexity, they still face challenges in inference due to high memory access costs. This work introduces UltraMem, incorporating large-scale, ultra-sparse memory layer to address these limitations. Our approach significantly reduces inference latency while maintaining model performance. We also investigate the scaling laws of this new architecture, demonstrating that it not only exhibits favorable scaling properties but outperforms traditional models. In our experiments, we train networks with up to 20 million memory slots. The results show that our method achieves state-of-the-art inference speed and model performance within a given computational budget.
Hyper-Connections
Sep 29, 2024



We present hyper-connections, a simple yet effective method that can serve as an alternative to residual connections. This approach specifically addresses common drawbacks observed in residual connection variants, such as the seesaw effect between gradient vanishing and representation collapse. Theoretically, hyper-connections allow the network to adjust the strength of connections between features at different depths and dynamically rearrange layers. We conduct experiments focusing on the pre-training of large language models, including dense and sparse models, where hyper-connections show significant performance improvements over residual connections. Additional experiments conducted on vision tasks also demonstrate similar improvements. We anticipate that this method will be broadly applicable and beneficial across a wide range of AI problems.
Class-Specific Semantic Reconstruction for Open Set Recognition
Jul 05, 2022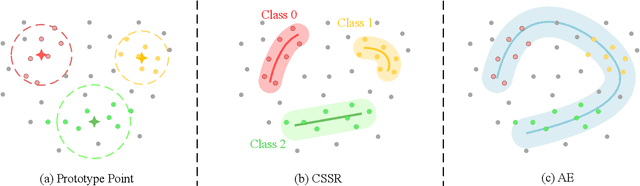
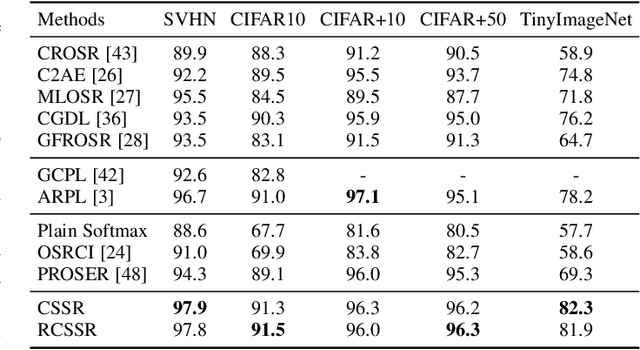


Open set recognition enables deep neural networks (DNNs) to identify samples of unknown classes, while maintaining high classification accuracy on samples of known classes. Existing methods basing on auto-encoder (AE) and prototype learning show great potential in handling this challenging task. In this study, we propose a novel method, called Class-Specific Semantic Reconstruction (CSSR), that integrates the power of AE and prototype learning. Specifically, CSSR replaces prototype points with manifolds represented by class-specific AEs. Unlike conventional prototype-based methods, CSSR models each known class on an individual AE manifold, and measures class belongingness through AE's reconstruction error. Class-specific AEs are plugged into the top of the DNN backbone and reconstruct the semantic representations learned by the DNN instead of the raw image. Through end-to-end learning, the DNN and the AEs boost each other to learn both discriminative and representative information. The results of experiments conducted on multiple datasets show that the proposed method achieves outstanding performance in both close and open set recognition and is sufficiently simple and flexible to incorporate into existing frameworks.