 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableVLA: Towards Robust Vision-Language-Action Models without Extra Data
May 18, 2026It is infeasible to encompass all possible disturbances within the training dataset. This raises a critical question regarding the robustness of Vision-Language-Action (VLA) models when encountering unseen real-world visual disturbances, particularly under imperfect visual conditions. In this work, we conduct a systematic study based on recent state-of-the-art VLA models and reveal a significant performance drop when visual disturbances absent from the training data are introduced. To mitigate this issue, we propose a lightweight adapter module grounded in information theory, termed the Information Bottleneck Adapter (IB-Adapter), which selectively filters potential noise from visual inputs. Without requiring any extra data or augmentation strategies, IB-Adapter consistently improves over the baseline by an average of 30%, while adding fewer than 10M parameters, demonstrating notable efficiency and effectiveness. Furthermore, even with a 14x smaller backbone (0.5B parameters) and no pre-training on the Open X-Embodiment dataset, our model StableVLA achieves robustness competitive with 7B-scale state-of-the-art VLAs. With negligible parameter overhead (<10M), our approach maintains accuracy on long-horizon tasks and surpasses OpenPi under both synthetic and physical visual corruptions.
ConceptMoE: Adaptive Token-to-Concept Compression for Implicit Compute Allocation
Jan 29, 2026Large language models allocate uniform computation across all tokens, ignoring that some sequences are trivially predictable while others require deep reasoning. We introduce ConceptMoE, which dynamically merges semantically similar tokens into concept representations, performing implicit token-level compute allocation. A learnable chunk module identifies optimal boundaries by measuring inter-token similarity, compressing sequences by a target ratio $R$ before they enter the compute-intensive concept model. Crucially, the MoE architecture enables controlled evaluation: we reallocate saved computation to match baseline activated FLOPs (excluding attention map computation) and total parameters, isolating genuine architectural benefits. Under these conditions, ConceptMoE consistently outperforms standard MoE across language and vision-language tasks, achieving +0.9 points on language pretraining, +2.3 points on long context understanding, and +0.6 points on multimodal benchmarks. When converting pretrained MoE during continual training with layer looping, gains reach +5.5 points, demonstrating practical applicability. Beyond performance, ConceptMoE reduces attention computation by up to $R^2\times$ and KV cache by $R\times$. At $R=2$, empirical measurements show prefill speedups reaching 175\% and decoding speedups up to 117\% on long sequences. The minimal architectural modifications enable straightforward integration into existing MoE, demonstrating that adaptive concept-level processing fundamentally improves both effectiveness and efficiency of large language models.
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Dec 31, 2025Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025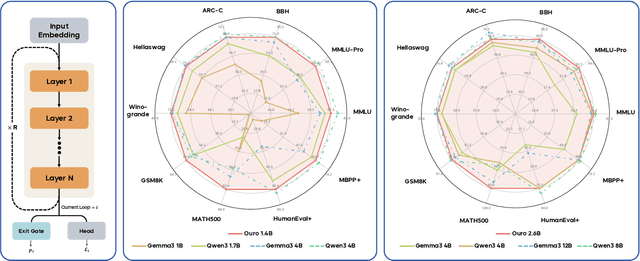
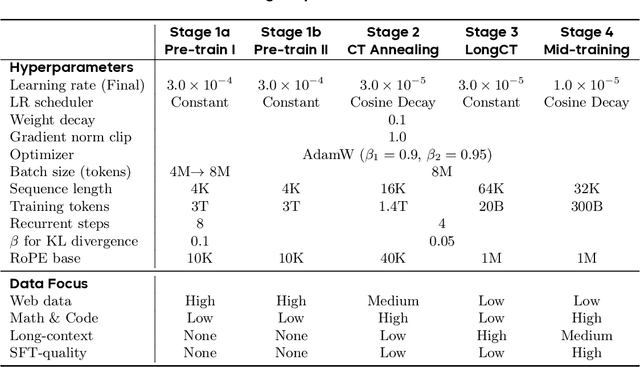
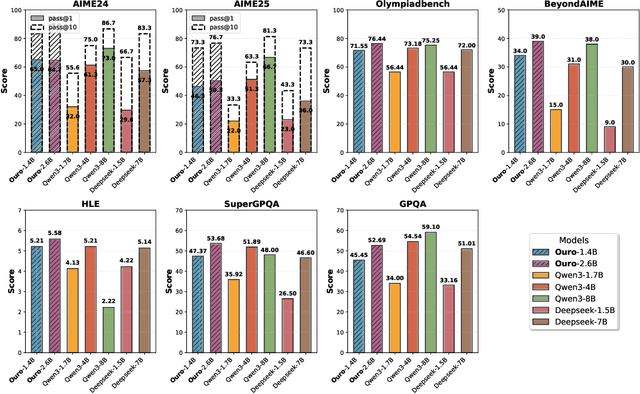

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
SeeDNorm: Self-Rescaled Dynamic Normalization
Oct 26, 2025Normalization layer constitutes an essential component in neural networks. In transformers, the predominantly used RMSNorm constrains vectors to a unit hypersphere, followed by dimension-wise rescaling through a learnable scaling coefficient $\gamma$ to maintain the representational capacity of the model. However, RMSNorm discards the input norm information in forward pass and a static scaling factor $\gamma$ may be insufficient to accommodate the wide variability of input data and distributional shifts, thereby limiting further performance improvements, particularly in zero-shot scenarios that large language models routinely encounter. To address this limitation, we propose SeeDNorm, which enhances the representational capability of the model by dynamically adjusting the scaling coefficient based on the current input, thereby preserving the input norm information and enabling data-dependent, self-rescaled dynamic normalization. During backpropagation, SeeDNorm retains the ability of RMSNorm to dynamically adjust gradient according to the input norm. We provide a detailed analysis of the training optimization for SeedNorm and proposed corresponding solutions to address potential instability issues that may arise when applying SeeDNorm. We validate the effectiveness of SeeDNorm across models of varying sizes in large language model pre-training as well as supervised and unsupervised computer vision tasks. By introducing a minimal number of parameters and with neglligible impact on model efficiency, SeeDNorm achieves consistently superior performance compared to previously commonly used normalization layers such as RMSNorm and LayerNorm, as well as element-wise activation alternatives to normalization layers like DyT.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
Expert Race: A Flexible Routing Strategy for Scaling Diffusion Transformer with Mixture of Experts
Mar 20, 2025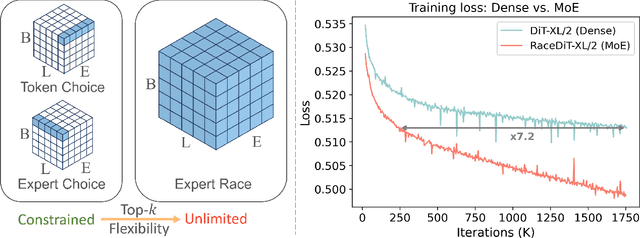



Diffusion models have emerged as mainstream framework in visual generation. Building upon this success, the integration of Mixture of Experts (MoE) methods has shown promise in enhancing model scalability and performance. In this paper, we introduce Race-DiT, a novel MoE model for diffusion transformers with a flexible routing strategy, Expert Race. By allowing tokens and experts to compete together and select the top candidates, the model learns to dynamically assign experts to critical tokens. Additionally, we propose per-layer regularization to address challenges in shallow layer learning, and router similarity loss to prevent mode collapse, ensuring better expert utilization. Extensive experiments on ImageNet validate the effectiveness of our approach, showcasing significant performance gains while promising scaling properties.
Frac-Connections: Fractional Extension of Hyper-Connections
Mar 18, 2025



Residual connections are central to modern deep learning architectures, enabling the training of very deep networks by mitigating gradient vanishing. Hyper-Connections recently generalized residual connections by introducing multiple connection strengths at different depths, thereby addressing the seesaw effect between gradient vanishing and representation collapse. However, Hyper-Connections increase memory access costs by expanding the width of hidden states. In this paper, we propose Frac-Connections, a novel approach that divides hidden states into multiple parts rather than expanding their width. Frac-Connections retain partial benefits of Hyper-Connections while reducing memory consumption. To validate their effectiveness, we conduct large-scale experiments on language tasks, with the largest being a 7B MoE model trained on up to 3T tokens, demonstrating that Frac-Connections significantly outperform residual connections.
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
Jan 28, 2025



Tokenization is a fundamental component of large language models (LLMs), yet its influence on model scaling and performance is not fully explored. In this paper, we introduce Over-Tokenized Transformers, a novel framework that decouples input and output vocabularies to improve language modeling performance. Specifically, our approach scales up input vocabularies to leverage multi-gram tokens. Through extensive experiments, we uncover a log-linear relationship between input vocabulary size and training loss, demonstrating that larger input vocabularies consistently enhance model performance, regardless of model size. Using a large input vocabulary, we achieve performance comparable to double-sized baselines with no additional cost. Our findings highlight the importance of tokenization in scaling laws and provide practical insight for tokenizer design, paving the way for more efficient and powerful LLMs.