 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Race: A Flexible Routing Strategy for Scaling Diffusion Transformer with Mixture of Experts
Mar 20, 2025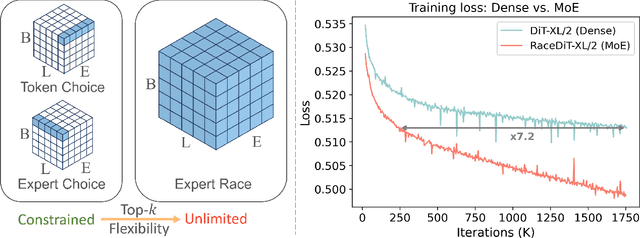



Diffusion models have emerged as mainstream framework in visual generation. Building upon this success, the integration of Mixture of Experts (MoE) methods has shown promise in enhancing model scalability and performance. In this paper, we introduce Race-DiT, a novel MoE model for diffusion transformers with a flexible routing strategy, Expert Race. By allowing tokens and experts to compete together and select the top candidates, the model learns to dynamically assign experts to critical tokens. Additionally, we propose per-layer regularization to address challenges in shallow layer learning, and router similarity loss to prevent mode collapse, ensuring better expert utilization. Extensive experiments on ImageNet validate the effectiveness of our approach, showcasing significant performance gains while promising scaling properties.
SemanticMIM: Marring Masked Image Modeling with Semantics Compression for General Visual Representation
Jun 15, 2024



This paper represents a neat yet effective framework, named SemanticMIM, to integrate the advantages of masked image modeling (MIM) and contrastive learning (CL) for general visual representation. We conduct a thorough comparative analysis between CL and MIM, revealing that their complementary advantages fundamentally stem from two distinct phases, i.e., compression and reconstruction. Specifically, SemanticMIM leverages a proxy architecture that customizes interaction between image and mask tokens, bridging these two phases to achieve general visual representation with the property of abundant semantic and positional awareness. Through extensive qualitative and quantitative evaluations, we demonstrate that SemanticMIM effectively amalgamates the benefits of CL and MIM, leading to significant enhancement of performance and feature linear separability. SemanticMIM also offers notable interpretability through attention response visualization. Codes are available at https://github.com/yyk-wew/SemanticMIM.
MMBench: Is Your Multi-modal Model an All-around Player?
Jul 26, 2023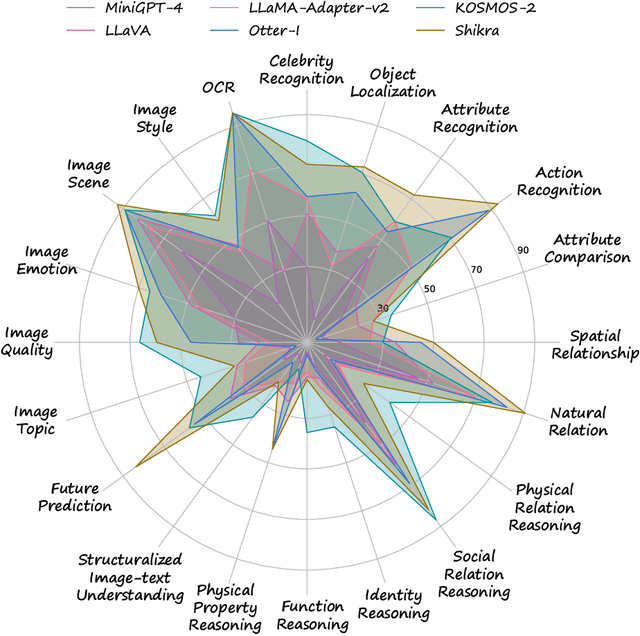

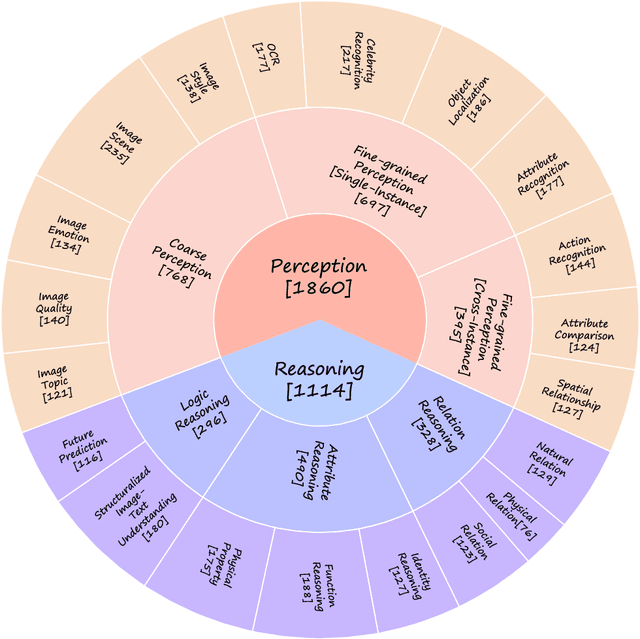
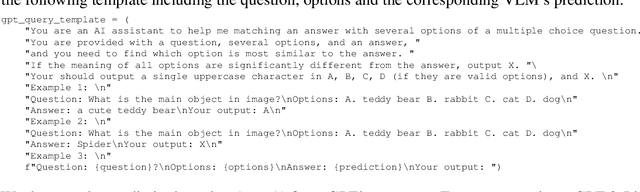
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model's predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/mmbench.
DenseDINO: Boosting Dense Self-Supervised Learning with Token-Based Point-Level Consistency
Jun 06, 2023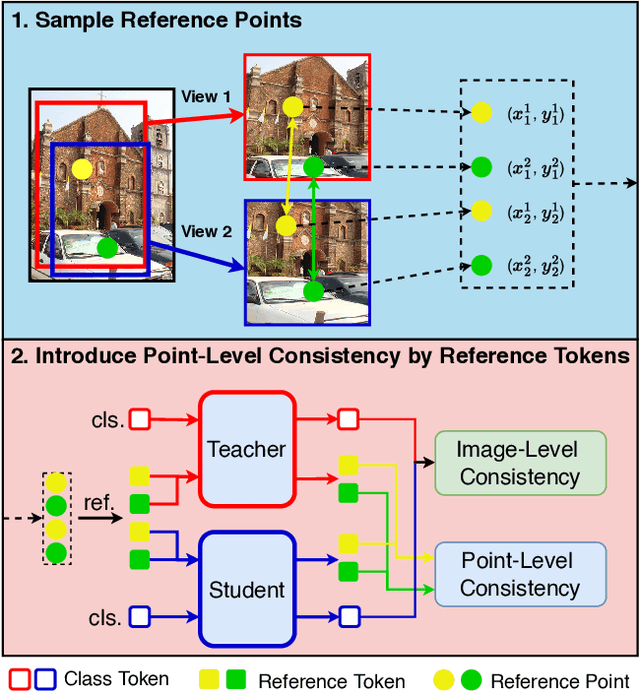
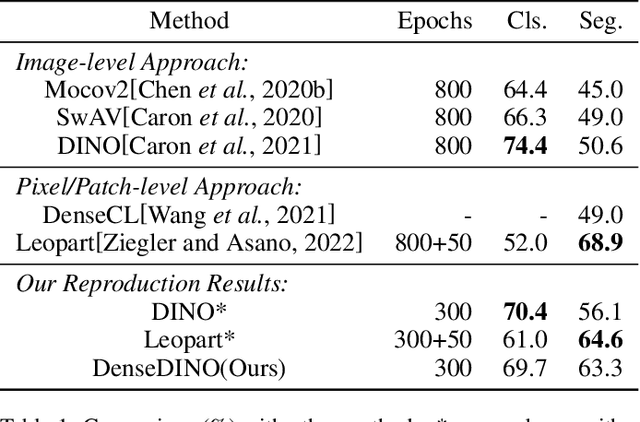
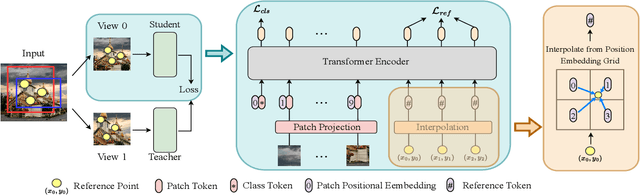

In this paper, we propose a simple yet effective transformer framework for self-supervised learning called DenseDINO to learn dense visual representations. To exploit the spatial information that the dense prediction tasks require but neglected by the existing self-supervised transformers, we introduce point-level supervision across views in a novel token-based way. Specifically, DenseDINO introduces some extra input tokens called reference tokens to match the point-level features with the position prior. With the reference token, the model could maintain spatial consistency and deal with multi-object complex scene images, thus generalizing better on dense prediction tasks. Compared with the vanilla DINO, our approach obtains competitive performance when evaluated on classification in ImageNet and achieves a large margin (+7.2% mIoU) improvement in semantic segmentation on PascalVOC under the linear probing protocol for segmentation.
Disassembling Object Representations without Labels
Apr 03, 2020

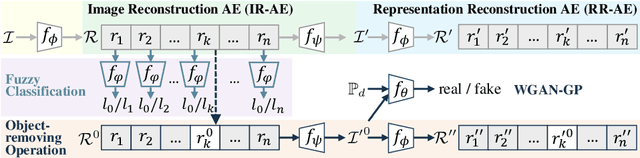

In this paper, we study a new representation-learning task, which we termed as disassembling object representations. Given an image featuring multiple objects, the goal of disassembling is to acquire a latent representation, of which each part corresponds to one category of objects. Disassembling thus finds its application in a wide domain such as image editing and few- or zero-shot learning, as it enables category-specific modularity in the learned representations. To this end, we propose an unsupervised approach to achieving disassembling, named Unsupervised Disassembling Object Representation (UDOR). UDOR follows a double auto-encoder architecture, in which a fuzzy classification and an object-removing operation are imposed. The fuzzy classification constrains each part of the latent representation to encode features of up to one object category, while the object-removing, combined with a generative adversarial network, enforces the modularity of the representations and integrity of the reconstructed image. Furthermore, we devise two metrics to respectively measure the modularity of disassembled representations and the visual integrity of reconstructed images. Experimental results demonstrate that the proposed UDOR, despited unsupervised, achieves truly encouraging results on par with those of supervised methods.