 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
Energy-Guided Optimization for Personalized Image Editing with Pretrained Text-to-Image Diffusion Models
Mar 06, 2025The rapid advancement of pretrained text-driven diffusion models has significantly enriched applications in image generation and editing. However, as the demand for personalized content editing increases, new challenges emerge especially when dealing with arbitrary objects and complex scenes. Existing methods usually mistakes mask as the object shape prior, which struggle to achieve a seamless integration result. The mostly used inversion noise initialization also hinders the identity consistency towards the target object. To address these challenges, we propose a novel training-free framework that formulates personalized content editing as the optimization of edited images in the latent space, using diffusion models as the energy function guidance conditioned by reference text-image pairs. A coarse-to-fine strategy is proposed that employs text energy guidance at the early stage to achieve a natural transition toward the target class and uses point-to-point feature-level image energy guidance to perform fine-grained appearance alignment with the target object. Additionally, we introduce the latent space content composition to enhance overall identity consistency with the target. Extensive experiments demonstrate that our method excels in object replacement even with a large domain gap, highlighting its potential for high-quality, personalized image editing.
Exploring Unbiased Deepfake Detection via Token-Level Shuffling and Mixing
Jan 08, 2025



The generalization problem is broadly recognized as a critical challenge in detecting deepfakes. Most previous work believes that the generalization gap is caused by the differences among various forgery methods. However, our investigation reveals that the generalization issue can still occur when forgery-irrelevant factors shift. In this work, we identify two biases that detectors may also be prone to overfitting: position bias and content bias, as depicted in Fig. 1. For the position bias, we observe that detectors are prone to lazily depending on the specific positions within an image (e.g., central regions even no forgery). As for content bias, we argue that detectors may potentially and mistakenly utilize forgery-unrelated information for detection (e.g., background, and hair). To intervene these biases, we propose two branches for shuffling and mixing with tokens in the latent space of transformers. For the shuffling branch, we rearrange the tokens and corresponding position embedding for each image while maintaining the local correlation. For the mixing branch, we randomly select and mix the tokens in the latent space between two images with the same label within the mini-batch to recombine the content information. During the learning process, we align the outputs of detectors from different branches in both feature space and logit space. Contrastive losses for features and divergence losses for logits are applied to obtain unbiased feature representation and classifiers. We demonstrate and verify the effectiveness of our method through extensive experiments on widely used evaluation datasets.
Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning
Aug 30, 2024
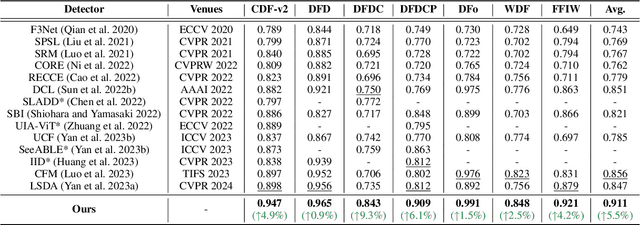
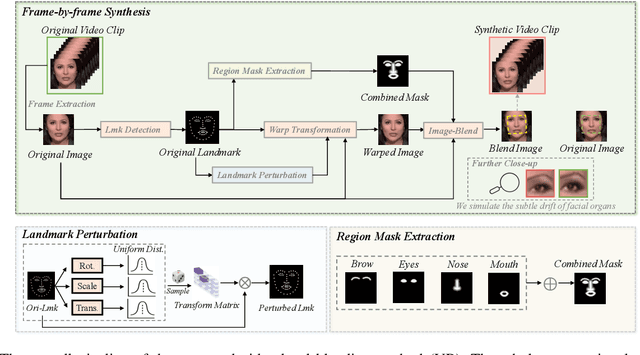

Three key challenges hinder the development of current deepfake video detection: (1) Temporal features can be complex and diverse: how can we identify general temporal artifacts to enhance model generalization? (2) Spatiotemporal models often lean heavily on one type of artifact and ignore the other: how can we ensure balanced learning from both? (3) Videos are naturally resource-intensive: how can we tackle efficiency without compromising accuracy? This paper attempts to tackle the three challenges jointly. First, inspired by the notable generality of using image-level blending data for image forgery detection, we investigate whether and how video-level blending can be effective in video. We then perform a thorough analysis and identify a previously underexplored temporal forgery artifact: Facial Feature Drift (FFD), which commonly exists across different forgeries. To reproduce FFD, we then propose a novel Video-level Blending data (VB), where VB is implemented by blending the original image and its warped version frame-by-frame, serving as a hard negative sample to mine more general artifacts. Second, we carefully design a lightweight Spatiotemporal Adapter (StA) to equip a pretrained image model (both ViTs and CNNs) with the ability to capture both spatial and temporal features jointly and efficiently. StA is designed with two-stream 3D-Conv with varying kernel sizes, allowing it to process spatial and temporal features separately. Extensive experiments validate the effectiveness of the proposed methods; and show our approach can generalize well to previously unseen forgery videos, even the just-released (in 2024) SoTAs. We release our code and pretrained weights at \url{https://github.com/YZY-stack/StA4Deepfake}.
DF40: Toward Next-Generation Deepfake Detection
Jun 19, 2024


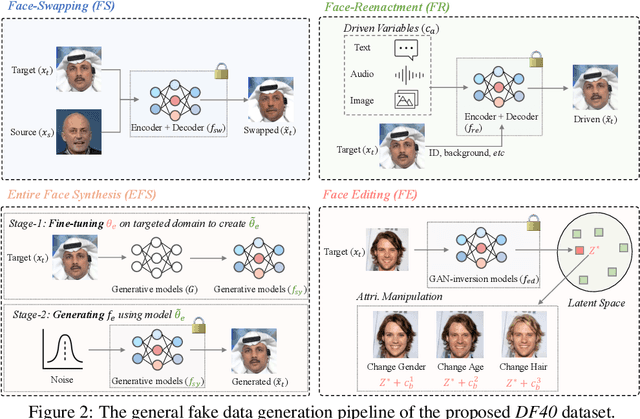
We propose a new comprehensive benchmark to revolutionize the current deepfake detection field to the next generation. Predominantly, existing works identify top-notch detection algorithms and models by adhering to the common practice: training detectors on one specific dataset (e.g., FF++) and testing them on other prevalent deepfake datasets. This protocol is often regarded as a "golden compass" for navigating SoTA detectors. But can these stand-out "winners" be truly applied to tackle the myriad of realistic and diverse deepfakes lurking in the real world? If not, what underlying factors contribute to this gap? In this work, we found the dataset (both train and test) can be the "primary culprit" due to: (1) forgery diversity: Deepfake techniques are commonly referred to as both face forgery (face-swapping and face-reenactment) and entire image synthesis (AIGC). Most existing datasets only contain partial types, with limited forgery methods implemented; (2) forgery realism: The dominant training dataset, FF++, contains old forgery techniques from the past five years. "Honing skills" on these forgeries makes it difficult to guarantee effective detection of nowadays' SoTA deepfakes; (3) evaluation protocol: Most detection works perform evaluations on one type, e.g., train and test on face-swapping only, which hinders the development of universal deepfake detectors. To address this dilemma, we construct a highly diverse and large-scale deepfake dataset called DF40, which comprises 40 distinct deepfake techniques. We then conduct comprehensive evaluations using 4 standard evaluation protocols and 7 representative detectors, resulting in over 2,000 evaluations. Through these evaluations, we analyze from various perspectives, leading to 12 new insightful findings contributing to the field. We also open up 5 valuable yet previously underexplored research questions to inspire future works.
DenseDINO: Boosting Dense Self-Supervised Learning with Token-Based Point-Level Consistency
Jun 06, 2023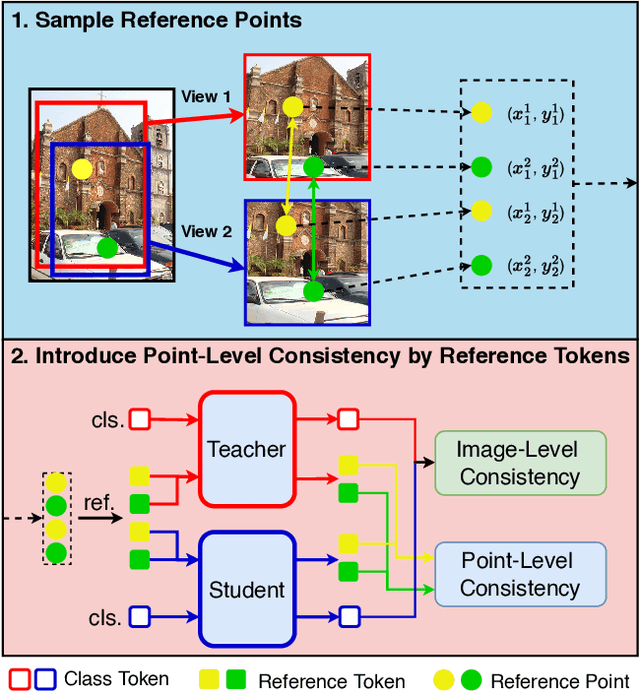
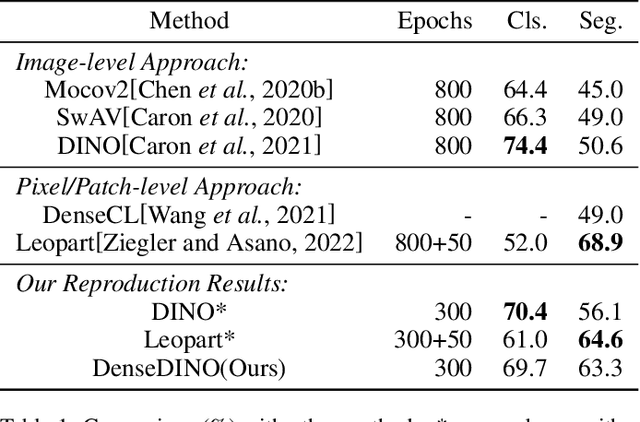
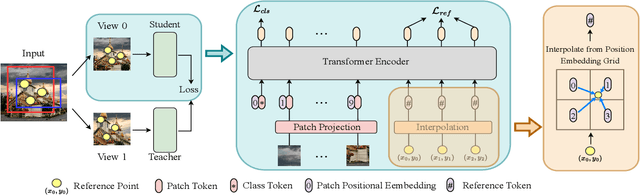

In this paper, we propose a simple yet effective transformer framework for self-supervised learning called DenseDINO to learn dense visual representations. To exploit the spatial information that the dense prediction tasks require but neglected by the existing self-supervised transformers, we introduce point-level supervision across views in a novel token-based way. Specifically, DenseDINO introduces some extra input tokens called reference tokens to match the point-level features with the position prior. With the reference token, the model could maintain spatial consistency and deal with multi-object complex scene images, thus generalizing better on dense prediction tasks. Compared with the vanilla DINO, our approach obtains competitive performance when evaluated on classification in ImageNet and achieves a large margin (+7.2% mIoU) improvement in semantic segmentation on PascalVOC under the linear probing protocol for segmentation.
RBC: Rectifying the Biased Context in Continual Semantic Segmentation
Mar 16, 2022


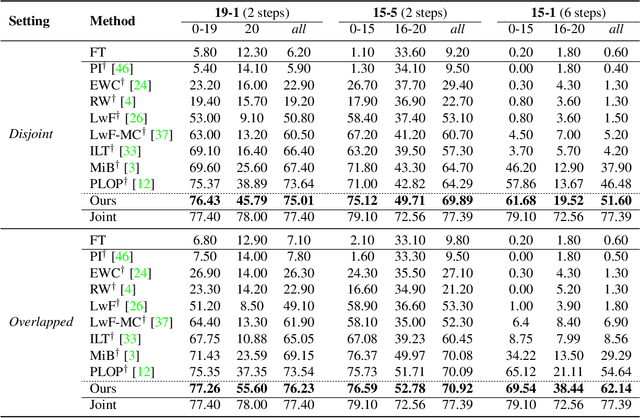
Recent years have witnessed a great development of Convolutional Neural Networks in semantic segmentation, where all classes of training images are simultaneously available. In practice, new images are usually made available in a consecutive manner, leading to a problem called Continual Semantic Segmentation (CSS). Typically, CSS faces the forgetting problem since previous training images are unavailable, and the semantic shift problem of the background class. Considering the semantic segmentation as a context-dependent pixel-level classification task, we explore CSS from a new perspective of context analysis in this paper. We observe that the context of old-class pixels in the new images is much more biased on new classes than that in the old images, which can sharply aggravate the old-class forgetting and new-class overfitting. To tackle the obstacle, we propose a biased-context-rectified CSS framework with a context-rectified image-duplet learning scheme and a biased-context-insensitive consistency loss. Furthermore, we propose an adaptive re-weighting class-balanced learning strategy for the biased class distribution. Our approach outperforms state-of-the-art methods by a large margin in existing CSS scenarios.