 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Unified Multimodal Models: Enhancing Generation via Reflective Rectification with Inherent Understanding
Apr 15, 2026Unified Multimodal Models (UMMs) aim to integrate visual understanding and generation within a single structure. However, these models exhibit a notable capability mismatch, where their understanding capability significantly outperforms their generation. This mismatch indicates that the model's rich internal knowledge, while effective for understanding tasks, remains underactivated during generation. To address this, we draw inspiration from the human ``Thinking-While-Drawing'' paradigm, where humans continuously reflect to activate their knowledge and rectify intermediate results. In this paper, we propose UniRect-CoT, a training-free unified rectification chain-of-thought framework. Our approach unlocks the ``free lunch'' hidden in the UMM's powerful inherent understanding to continuously reflect, activating its internal knowledge and rectifying intermediate results during generation.We regard the diffusion denoising process in UMMs as an intrinsic visual reasoning process and align the intermediate results with the target instruction understood by the model, serving as a self-supervisory signal to rectify UMM generation.Extensive experiments demonstrate that UniRect-CoT can be easily integrated into existing UMMs, significantly enhancing generation quality across diverse complex tasks.
Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
Jul 23, 2025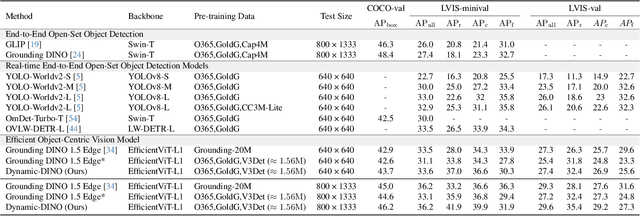
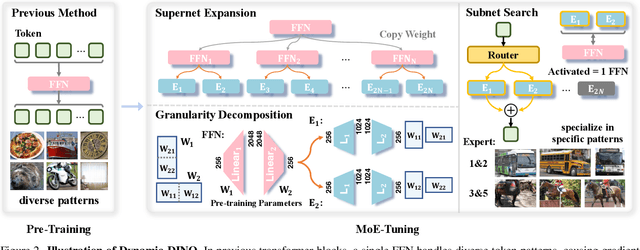

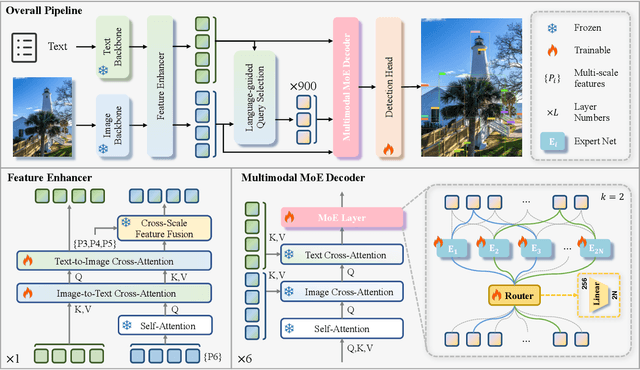
The Mixture of Experts (MoE) architecture has excelled in Large Vision-Language Models (LVLMs), yet its potential in real-time open-vocabulary object detectors, which also leverage large-scale vision-language datasets but smaller models, remains unexplored. This work investigates this domain, revealing intriguing insights. In the shallow layers, experts tend to cooperate with diverse peers to expand the search space. While in the deeper layers, fixed collaborative structures emerge, where each expert maintains 2-3 fixed partners and distinct expert combinations are specialized in processing specific patterns. Concretely, we propose Dynamic-DINO, which extends Grounding DINO 1.5 Edge from a dense model to a dynamic inference framework via an efficient MoE-Tuning strategy. Additionally, we design a granularity decomposition mechanism to decompose the Feed-Forward Network (FFN) of base model into multiple smaller expert networks, expanding the subnet search space. To prevent performance degradation at the start of fine-tuning, we further propose a pre-trained weight allocation strategy for the experts, coupled with a specific router initialization. During inference, only the input-relevant experts are activated to form a compact subnet. Experiments show that, pretrained with merely 1.56M open-source data, Dynamic-DINO outperforms Grounding DINO 1.5 Edge, pretrained on the private Grounding20M dataset.
Energy-Guided Optimization for Personalized Image Editing with Pretrained Text-to-Image Diffusion Models
Mar 06, 2025The rapid advancement of pretrained text-driven diffusion models has significantly enriched applications in image generation and editing. However, as the demand for personalized content editing increases, new challenges emerge especially when dealing with arbitrary objects and complex scenes. Existing methods usually mistakes mask as the object shape prior, which struggle to achieve a seamless integration result. The mostly used inversion noise initialization also hinders the identity consistency towards the target object. To address these challenges, we propose a novel training-free framework that formulates personalized content editing as the optimization of edited images in the latent space, using diffusion models as the energy function guidance conditioned by reference text-image pairs. A coarse-to-fine strategy is proposed that employs text energy guidance at the early stage to achieve a natural transition toward the target class and uses point-to-point feature-level image energy guidance to perform fine-grained appearance alignment with the target object. Additionally, we introduce the latent space content composition to enhance overall identity consistency with the target. Extensive experiments demonstrate that our method excels in object replacement even with a large domain gap, highlighting its potential for high-quality, personalized image editing.
Benchmarking Multimodal RAG through a Chart-based Document Question-Answering Generation Framework
Feb 20, 2025Multimodal Retrieval-Augmented Generation (MRAG) enhances reasoning capabilities by integrating external knowledge. However, existing benchmarks primarily focus on simple image-text interactions, overlooking complex visual formats like charts that are prevalent in real-world applications. In this work, we introduce a novel task, Chart-based MRAG, to address this limitation. To semi-automatically generate high-quality evaluation samples, we propose CHARt-based document question-answering GEneration (CHARGE), a framework that produces evaluation data through structured keypoint extraction, crossmodal verification, and keypoint-based generation. By combining CHARGE with expert validation, we construct Chart-MRAG Bench, a comprehensive benchmark for chart-based MRAG evaluation, featuring 4,738 question-answering pairs across 8 domains from real-world documents. Our evaluation reveals three critical limitations in current approaches: (1) unified multimodal embedding retrieval methods struggles in chart-based scenarios, (2) even with ground-truth retrieval, state-of-the-art MLLMs achieve only 58.19% Correctness and 73.87% Coverage scores, and (3) MLLMs demonstrate consistent text-over-visual modality bias during Chart-based MRAG reasoning. The CHARGE and Chart-MRAG Bench are released at https://github.com/Nomothings/CHARGE.git.
Joint Beamforming for Multi-target Detection and Multi-user Communication in ISAC Systems
Nov 01, 2024



Detecting weak targets is one of the main challenges for integrated sensing and communication (ISAC) systems. Sensing and communication suffer from a performance trade-off in ISAC systems. As the communication demand increases, sensing ability, especially weak target detection performance, will inevitably reduce. Traditional approaches fail to address this issue. In this paper, we develop a joint beamforming scheme and formulate it as a max-min problem to maximize the detection probability of the weakest target under the constraint of the signal-to-interference-plus-noise ratio (SINR) of multi-user communication. An alternating optimization (AO) algorithm is developed for solving the complicated non-convex problem to obtain the joint beamformer. The proposed scheme can direct the transmit energy toward the multiple targets properly to ensure robust multi-target detection performance. Numerical results show that the proposed beamforming scheme can effectively increase the detection probability of the weakest target compared to baseline approaches while ensuring communication performance.
CamI2V: Camera-Controlled Image-to-Video Diffusion Model
Oct 21, 2024



Recently, camera pose, as a user-friendly and physics-related condition, has been introduced into text-to-video diffusion model for camera control. However, existing methods simply inject camera conditions through a side input. These approaches neglect the inherent physical knowledge of camera pose, resulting in imprecise camera control, inconsistencies, and also poor interpretability. In this paper, we emphasize the necessity of integrating explicit physical constraints into model design. Epipolar attention is proposed for modeling all cross-frame relationships from a novel perspective of noised condition. This ensures that features are aggregated from corresponding epipolar lines in all noised frames, overcoming the limitations of current attention mechanisms in tracking displaced features across frames, especially when features move significantly with the camera and become obscured by noise. Additionally, we introduce register tokens to handle cases without intersections between frames, commonly caused by rapid camera movements, dynamic objects, or occlusions. To support image-to-video, we propose the multiple guidance scale to allow for precise control for image, text, and camera, respectively. Furthermore, we establish a more robust and reproducible evaluation pipeline to solve the inaccuracy and instability of existing camera control measurement. We achieve a 25.5\% improvement in camera controllability on RealEstate10K while maintaining strong generalization to out-of-domain images. Only 24GB and 12GB are required for training and inference, respectively. We plan to release checkpoints, along with training and evaluation codes. Dynamic videos are best viewed at \url{https://zgctroy.github.io/CamI2V}.
RSAM-Seg: A SAM-based Approach with Prior Knowledge Integration for Remote Sensing Image Semantic Segmentation
Feb 29, 2024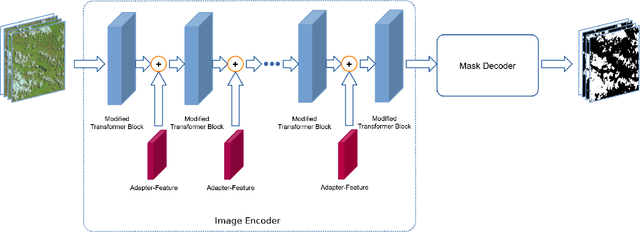


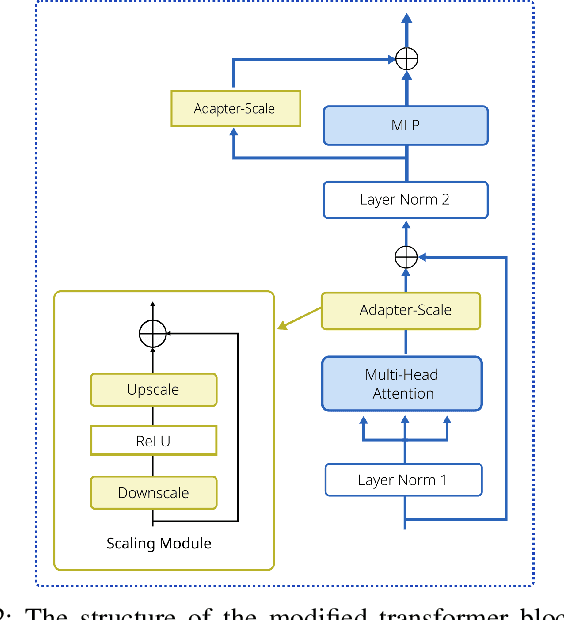
The development of high-resolution remote sensing satellites has provided great convenience for research work related to remote sensing. Segmentation and extraction of specific targets are essential tasks when facing the vast and complex remote sensing images. Recently, the introduction of Segment Anything Model (SAM) provides a universal pre-training model for image segmentation tasks. While the direct application of SAM to remote sensing image segmentation tasks does not yield satisfactory results, we propose RSAM-Seg, which stands for Remote Sensing SAM with Semantic Segmentation, as a tailored modification of SAM for the remote sensing field and eliminates the need for manual intervention to provide prompts. Adapter-Scale, a set of supplementary scaling modules, are proposed in the multi-head attention blocks of the encoder part of SAM. Furthermore, Adapter-Feature are inserted between the Vision Transformer (ViT) blocks. These modules aim to incorporate high-frequency image information and image embedding features to generate image-informed prompts. Experiments are conducted on four distinct remote sensing scenarios, encompassing cloud detection, field monitoring, building detection and road mapping tasks . The experimental results not only showcase the improvement over the original SAM and U-Net across cloud, buildings, fields and roads scenarios, but also highlight the capacity of RSAM-Seg to discern absent areas within the ground truth of certain datasets, affirming its potential as an auxiliary annotation method. In addition, the performance in few-shot scenarios is commendable, underscores its potential in dealing with limited datasets.
Label Informed Contrastive Pretraining for Node Importance Estimation on Knowledge Graphs
Feb 26, 2024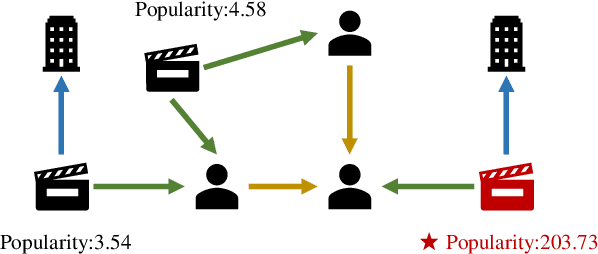
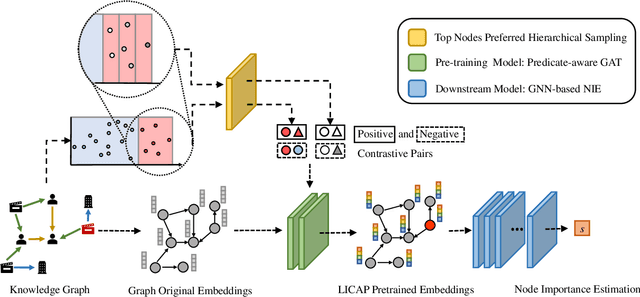
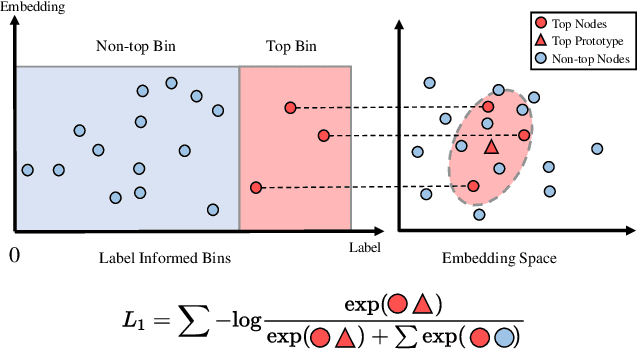
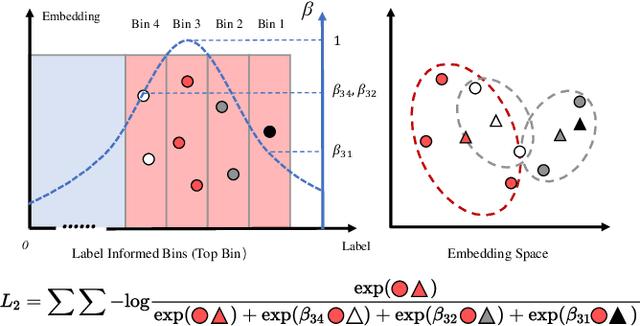
Node Importance Estimation (NIE) is a task of inferring importance scores of the nodes in a graph. Due to the availability of richer data and knowledge, recent research interests of NIE have been dedicating to knowledge graphs for predicting future or missing node importance scores. Existing state-of-the-art NIE methods train the model by available labels, and they consider every interested node equally before training. However, the nodes with higher importance often require or receive more attention in real-world scenarios, e.g., people may care more about the movies or webpages with higher importance. To this end, we introduce Label Informed ContrAstive Pretraining (LICAP) to the NIE problem for being better aware of the nodes with high importance scores. Specifically, LICAP is a novel type of contrastive learning framework that aims to fully utilize the continuous labels to generate contrastive samples for pretraining embeddings. Considering the NIE problem, LICAP adopts a novel sampling strategy called top nodes preferred hierarchical sampling to first group all interested nodes into a top bin and a non-top bin based on node importance scores, and then divide the nodes within top bin into several finer bins also based on the scores. The contrastive samples are generated from those bins, and are then used to pretrain node embeddings of knowledge graphs via a newly proposed Predicate-aware Graph Attention Networks (PreGAT), so as to better separate the top nodes from non-top nodes, and distinguish the top nodes within top bin by keeping the relative order among finer bins. Extensive experiments demonstrate that the LICAP pretrained embeddings can further boost the performance of existing NIE methods and achieve the new state-of-the-art performance regarding both regression and ranking metrics. The source code for reproducibility is available at https://github.com/zhangtia16/LICAP
Adaptive Kalman-based hybrid car following strategy using TD3 and CACC
Dec 26, 2023In autonomous driving, the hybrid strategy of deep reinforcement learning and cooperative adaptive cruise control (CACC) can fully utilize the advantages of the two algorithms and significantly improve the performance of car following. However, it is challenging for the traditional hybrid strategy based on fixed coefficients to adapt to mixed traffic flow scenarios, which may decrease the performance and even lead to accidents. To address the above problems, a hybrid car following strategy based on an adaptive Kalman Filter is proposed by regarding CACC and Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithms. Different from traditional hybrid strategy based on fixed coefficients, the Kalman gain H, using as an adaptive coefficient, is derived from multi-timestep predictions and Monte Carlo Tree Search. At the end of study, simulation results with 4157745 timesteps indicate that, compared with the TD3 and HCFS algorithms, the proposed algorithm in this study can substantially enhance the safety of car following in mixed traffic flow without compromising the comfort and efficiency.
One-stop Training of Multiple Capacity Models
May 24, 2023



Training models with varying capacities can be advantageous for deploying them in different scenarios. While high-capacity models offer better performance, low-capacity models require fewer computing resources for training and inference. In this work, we propose a novel one-stop training framework to jointly train high-capacity and low-capactiy models. This framework consists of two composite model architectures and a joint training algorithm called Two-Stage Joint-Training (TSJT). Unlike knowledge distillation, where multiple capacity models are trained from scratch separately, our approach integrates supervisions from different capacity models simultaneously, leading to faster and more efficient convergence. Extensive experiments on the multilingual machine translation benchmark WMT10 show that our method outperforms low-capacity baseline models and achieves comparable or better performance on high-capacity models. Notably, the analysis demonstrates that our method significantly influences the initial training process, leading to more efficient convergence and superior solutions.