 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Informed Contrastive Pretraining for Node Importance Estimation on Knowledge Graphs
Paper and Code
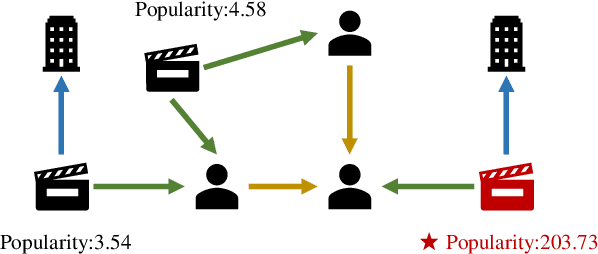
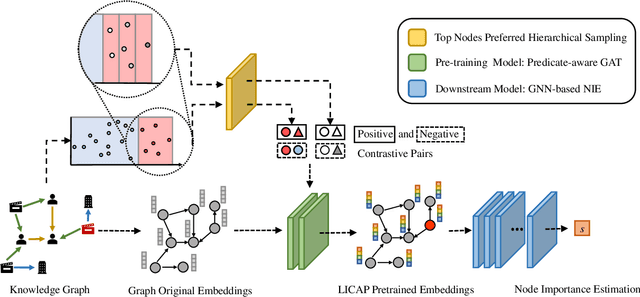
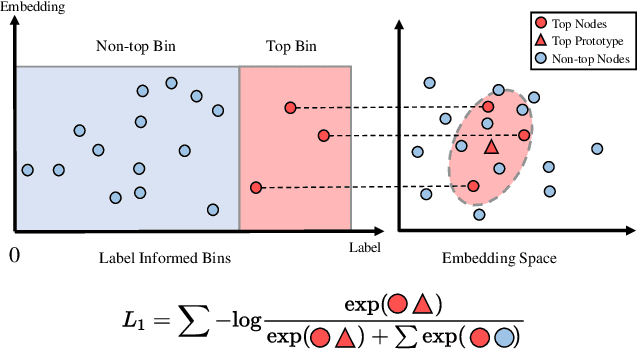
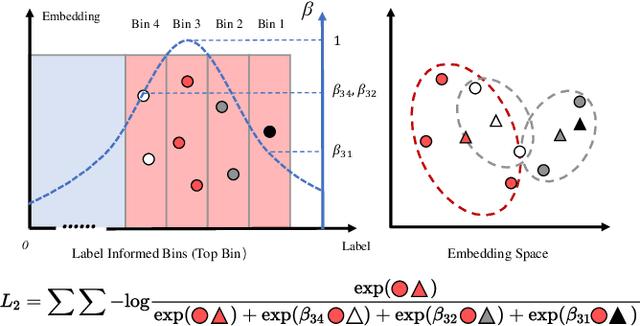
Node Importance Estimation (NIE) is a task of inferring importance scores of the nodes in a graph. Due to the availability of richer data and knowledge, recent research interests of NIE have been dedicating to knowledge graphs for predicting future or missing node importance scores. Existing state-of-the-art NIE methods train the model by available labels, and they consider every interested node equally before training. However, the nodes with higher importance often require or receive more attention in real-world scenarios, e.g., people may care more about the movies or webpages with higher importance. To this end, we introduce Label Informed ContrAstive Pretraining (LICAP) to the NIE problem for being better aware of the nodes with high importance scores. Specifically, LICAP is a novel type of contrastive learning framework that aims to fully utilize the continuous labels to generate contrastive samples for pretraining embeddings. Considering the NIE problem, LICAP adopts a novel sampling strategy called top nodes preferred hierarchical sampling to first group all interested nodes into a top bin and a non-top bin based on node importance scores, and then divide the nodes within top bin into several finer bins also based on the scores. The contrastive samples are generated from those bins, and are then used to pretrain node embeddings of knowledge graphs via a newly proposed Predicate-aware Graph Attention Networks (PreGAT), so as to better separate the top nodes from non-top nodes, and distinguish the top nodes within top bin by keeping the relative order among finer bins. Extensive experiments demonstrate that the LICAP pretrained embeddings can further boost the performance of existing NIE methods and achieve the new state-of-the-art performance regarding both regression and ranking metrics. The source code for reproducibility is available at https://github.com/zhangtia16/LICAP