 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Noise Robustness of Parkinson's Disease Telemonitoring via Contrastive Feature Augmentation
Oct 02, 2025Parkinson's disease (PD) is one of the most common neurodegenerative disorder. PD telemonitoring emerges as a novel assessment modality enabling self-administered at-home tests of Unified Parkinson's Disease Rating Scale (UPDRS) scores, enhancing accessibility for PD patients. However, three types of noise would occur during measurements: (1) patient-induced measurement inaccuracies, (2) environmental noise, and (3) data packet loss during transmission, resulting in higher prediction errors. To address these challenges, NoRo, a noise-robust UPDRS prediction framework is proposed. First, the original speech features are grouped into ordered bins, based on the continuous values of a selected feature, to construct contrastive pairs. Second, the contrastive pairs are employed to train a multilayer perceptron encoder for generating noise-robust features. Finally, these features are concatenated with the original features as the augmented features, which are then fed into the UPDRS prediction models. Notably, we further introduces a novel evaluation approach with customizable noise injection module, and extensive experiments show that NoRo can successfully enhance the noise robustness of UPDRS prediction across various downstream prediction models under different noisy environments.
Personalize Anything for Free with Diffusion Transformer
Mar 16, 2025



Personalized image generation aims to produce images of user-specified concepts while enabling flexible editing. Recent training-free approaches, while exhibit higher computational efficiency than training-based methods, struggle with identity preservation, applicability, and compatibility with diffusion transformers (DiTs). In this paper, we uncover the untapped potential of DiT, where simply replacing denoising tokens with those of a reference subject achieves zero-shot subject reconstruction. This simple yet effective feature injection technique unlocks diverse scenarios, from personalization to image editing. Building upon this observation, we propose \textbf{Personalize Anything}, a training-free framework that achieves personalized image generation in DiT through: 1) timestep-adaptive token replacement that enforces subject consistency via early-stage injection and enhances flexibility through late-stage regularization, and 2) patch perturbation strategies to boost structural diversity. Our method seamlessly supports layout-guided generation, multi-subject personalization, and mask-controlled editing. Evaluations demonstrate state-of-the-art performance in identity preservation and versatility. Our work establishes new insights into DiTs while delivering a practical paradigm for efficient personalization.
Node Importance Estimation Leveraging LLMs for Semantic Augmentation in Knowledge Graphs
Nov 30, 2024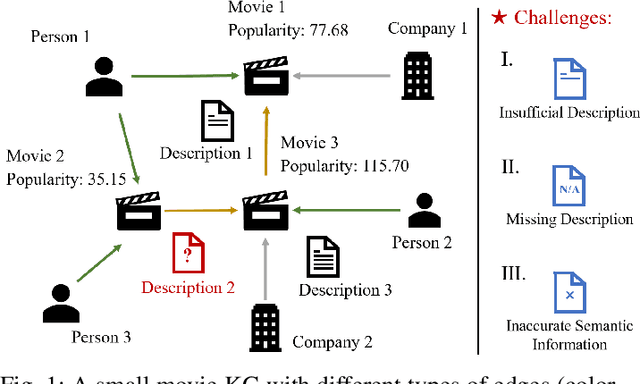
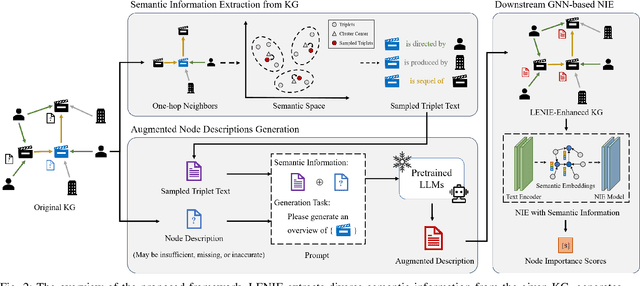


Node Importance Estimation (NIE) is a task that quantifies the importance of node in a graph. Recent research has investigated to exploit various information from Knowledge Graphs (KGs) to estimate node importance scores. However, the semantic information in KGs could be insufficient, missing, and inaccurate, which would limit the performance of existing NIE models. To address these issues, we leverage Large Language Models (LLMs) for semantic augmentation thanks to the LLMs' extra knowledge and ability of integrating knowledge from both LLMs and KGs. To this end, we propose the LLMs Empowered Node Importance Estimation (LENIE) method to enhance the semantic information in KGs for better supporting NIE tasks. To our best knowledge, this is the first work incorporating LLMs into NIE. Specifically, LENIE employs a novel clustering-based triplet sampling strategy to extract diverse knowledge of a node sampled from the given KG. After that, LENIE adopts the node-specific adaptive prompts to integrate the sampled triplets and the original node descriptions, which are then fed into LLMs for generating richer and more precise augmented node descriptions. These augmented descriptions finally initialize node embeddings for boosting the downstream NIE model performance. Extensive experiments demonstrate LENIE's effectiveness in addressing semantic deficiencies in KGs, enabling more informative semantic augmentation and enhancing existing NIE models to achieve the state-of-the-art performance. The source code of LENIE is freely available at \url{https://github.com/XinyuLin-FZ/LENIE}.
Molecular Graph Representation Learning Integrating Large Language Models with Domain-specific Small Models
Aug 19, 2024



Molecular property prediction is a crucial foundation for drug discovery. In recent years, pre-trained deep learning models have been widely applied to this task. Some approaches that incorporate prior biological domain knowledge into the pre-training framework have achieved impressive results. However, these methods heavily rely on biochemical experts, and retrieving and summarizing vast amounts of domain knowledge literature is both time-consuming and expensive. Large Language Models (LLMs) have demonstrated remarkable performance in understanding and efficiently providing general knowledge. Nevertheless, they occasionally exhibit hallucinations and lack precision in generating domain-specific knowledge. Conversely, Domain-specific Small Models (DSMs) possess rich domain knowledge and can accurately calculate molecular domain-related metrics. However, due to their limited model size and singular functionality, they lack the breadth of knowledge necessary for comprehensive representation learning. To leverage the advantages of both approaches in molecular property prediction, we propose a novel Molecular Graph representation learning framework that integrates Large language models and Domain-specific small models (MolGraph-LarDo). Technically, we design a two-stage prompt strategy where DSMs are introduced to calibrate the knowledge provided by LLMs, enhancing the accuracy of domain-specific information and thus enabling LLMs to generate more precise textual descriptions for molecular samples. Subsequently, we employ a multi-modal alignment method to coordinate various modalities, including molecular graphs and their corresponding descriptive texts, to guide the pre-training of molecular representations. Extensive experiments demonstrate the effectiveness of the proposed method.
Label Informed Contrastive Pretraining for Node Importance Estimation on Knowledge Graphs
Feb 26, 2024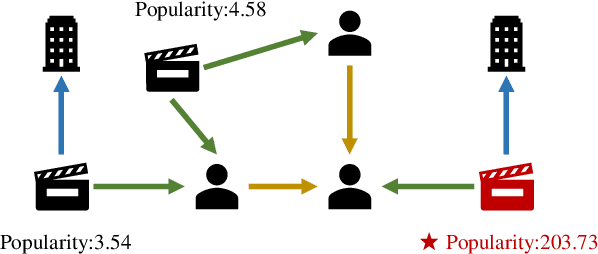
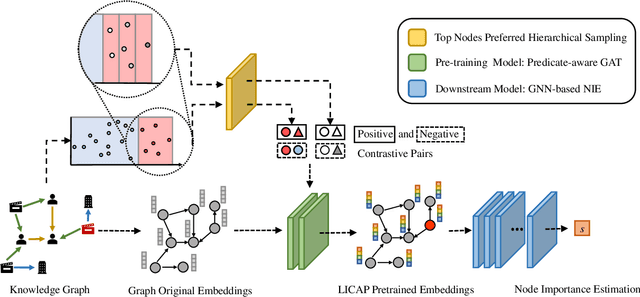
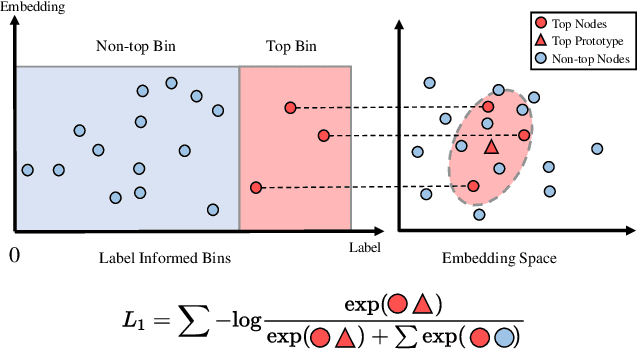
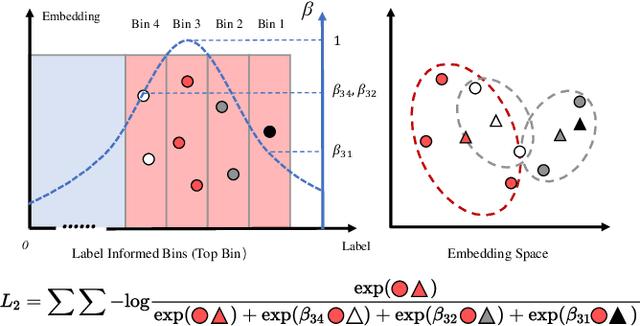
Node Importance Estimation (NIE) is a task of inferring importance scores of the nodes in a graph. Due to the availability of richer data and knowledge, recent research interests of NIE have been dedicating to knowledge graphs for predicting future or missing node importance scores. Existing state-of-the-art NIE methods train the model by available labels, and they consider every interested node equally before training. However, the nodes with higher importance often require or receive more attention in real-world scenarios, e.g., people may care more about the movies or webpages with higher importance. To this end, we introduce Label Informed ContrAstive Pretraining (LICAP) to the NIE problem for being better aware of the nodes with high importance scores. Specifically, LICAP is a novel type of contrastive learning framework that aims to fully utilize the continuous labels to generate contrastive samples for pretraining embeddings. Considering the NIE problem, LICAP adopts a novel sampling strategy called top nodes preferred hierarchical sampling to first group all interested nodes into a top bin and a non-top bin based on node importance scores, and then divide the nodes within top bin into several finer bins also based on the scores. The contrastive samples are generated from those bins, and are then used to pretrain node embeddings of knowledge graphs via a newly proposed Predicate-aware Graph Attention Networks (PreGAT), so as to better separate the top nodes from non-top nodes, and distinguish the top nodes within top bin by keeping the relative order among finer bins. Extensive experiments demonstrate that the LICAP pretrained embeddings can further boost the performance of existing NIE methods and achieve the new state-of-the-art performance regarding both regression and ranking metrics. The source code for reproducibility is available at https://github.com/zhangtia16/LICAP
Federated Learning with Classifier Shift for Class Imbalance
Apr 11, 2023Federated learning aims to learn a global model collaboratively while the training data belongs to different clients and is not allowed to be exchanged. However, the statistical heterogeneity challenge on non-IID data, such as class imbalance in classification, will cause client drift and significantly reduce the performance of the global model. This paper proposes a simple and effective approach named FedShift which adds the shift on the classifier output during the local training phase to alleviate the negative impact of class imbalance. We theoretically prove that the classifier shift in FedShift can make the local optimum consistent with the global optimum and ensure the convergence of the algorithm. Moreover, our experiments indicate that FedShift significantly outperforms the other state-of-the-art federated learning approaches on various datasets regarding accuracy and communication efficiency.
Fossil Image Identification using Deep Learning Ensembles of Data Augmented Multiviews
Feb 16, 2023Identification of fossil species is crucial to evolutionary studies. Recent advances from deep learning have shown promising prospects in fossil image identification. However, the quantity and quality of labeled fossil images are often limited due to fossil preservation, conditioned sampling, and expensive and inconsistent label annotation by domain experts, which pose great challenges to the training of deep learning based image classification models. To address these challenges, we follow the idea of the wisdom of crowds and propose a novel multiview ensemble framework, which collects multiple views of each fossil specimen image reflecting its different characteristics to train multiple base deep learning models and then makes final decisions via soft voting. We further develop OGS method that integrates original, gray, and skeleton views under this framework to demonstrate the effectiveness. Experimental results on the fusulinid fossil dataset over five deep learning based milestone models show that OGS using three base models consistently outperforms the baseline using a single base model, and the ablation study verifies the usefulness of each selected view. Besides, OGS obtains the superior or comparable performance compared to the method under well-known bagging framework. Moreover, as the available training data decreases, the proposed framework achieves more performance gains compared to the baseline. Furthermore, a consistency test with two human experts shows that OGS obtains the highest agreement with both the labels of dataset and the two experts. Notably, this methodology is designed for general fossil identification and it is expected to see applications on other fossil datasets. The results suggest the potential application when the quantity and quality of labeled data are particularly restricted, e.g., to identify rare fossil images.
Learning to Decompose Visual Features with Latent Textual Prompts
Oct 09, 2022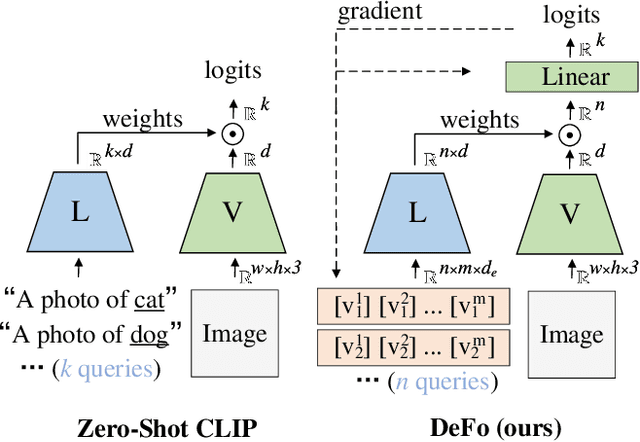
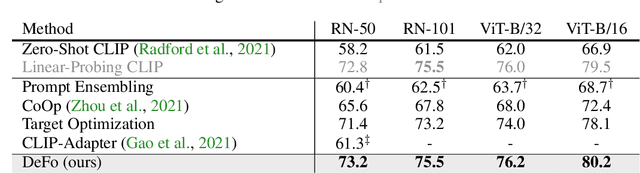

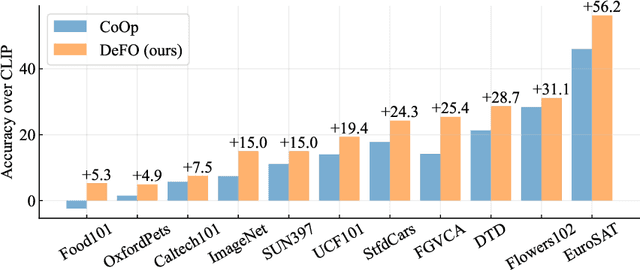
Recent advances in pre-training vision-language models like CLIP have shown great potential in learning transferable visual representations. Nonetheless, for downstream inference, CLIP-like models suffer from either 1) degraded accuracy and robustness in the case of inaccurate text descriptions during retrieval-based inference (the challenge for zero-shot protocol); or 2) breaking the well-established vision-language alignment (the challenge for linear probing). To address them, we propose Decomposed Feature Prompting (DeFo). DeFo leverages a flexible number of learnable embeddings as textual input while maintaining the vision-language dual-model architecture, which enables the model to learn decomposed visual features with the help of feature-level textual prompts. We further use an additional linear layer to perform classification, allowing a scalable size of language inputs. Our empirical study shows DeFo's significance in improving the vision-language models. For example, DeFo obtains 73.2% test accuracy on ImageNet with a ResNet-50 backbone without tuning any pretrained weights of both the vision and language encoder, outperforming zero-shot CLIP by a large margin of 15.0%, and outperforming state-of-the-art vision-language prompt tuning method by 7.6%.
Boost Neural Networks by Checkpoints
Oct 03, 2021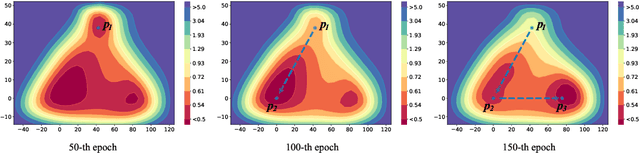
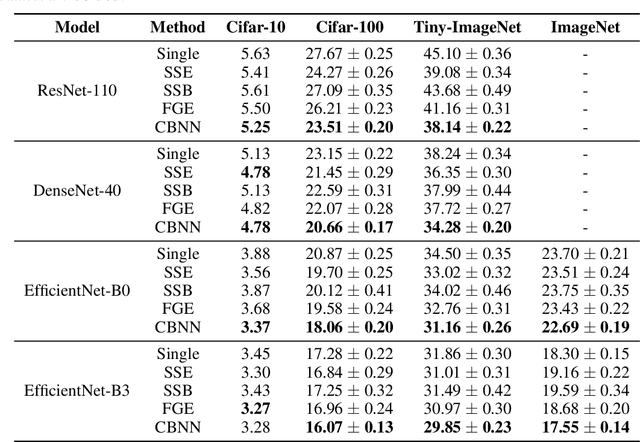
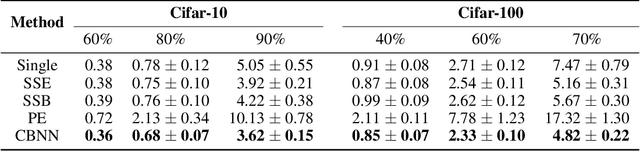
Training multiple deep neural networks (DNNs) and averaging their outputs is a simple way to improve the predictive performance. Nevertheless, the multiplied training cost prevents this ensemble method to be practical and efficient. Several recent works attempt to save and ensemble the checkpoints of DNNs, which only requires the same computational cost as training a single network. However, these methods suffer from either marginal accuracy improvements due to the low diversity of checkpoints or high risk of divergence due to the cyclical learning rates they adopted. In this paper, we propose a novel method to ensemble the checkpoints, where a boosting scheme is utilized to accelerate model convergence and maximize the checkpoint diversity. We theoretically prove that it converges by reducing exponential loss. The empirical evaluation also indicates our proposed ensemble outperforms single model and existing ensembles in terms of accuracy and efficiency. With the same training budget, our method achieves 4.16% lower error on Cifar-100 and 6.96% on Tiny-ImageNet with ResNet-110 architecture. Moreover, the adaptive sample weights in our method make it an effective solution to address the imbalanced class distribution. In the experiments, it yields up to 5.02% higher accuracy over single EfficientNet-B0 on the imbalanced datasets.