 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCA: Mixture-of-Components Attention for Scalable Compositional 3D Generation
Dec 08, 2025Compositionality is critical for 3D object and scene generation, but existing part-aware 3D generation methods suffer from poor scalability due to quadratic global attention costs when increasing the number of components. In this work, we present MoCA, a compositional 3D generative model with two key designs: (1) importance-based component routing that selects top-k relevant components for sparse global attention, and (2) unimportant components compression that preserve contextual priors of unselected components while reducing computational complexity of global attention. With these designs, MoCA enables efficient, fine-grained compositional 3D asset creation with scalable number of components. Extensive experiments show MoCA outperforms baselines on both compositional object and scene generation tasks. Project page: https://lizhiqi49.github.io/MoCA
InterMoE: Individual-Specific 3D Human Interaction Generation via Dynamic Temporal-Selective MoE
Nov 17, 2025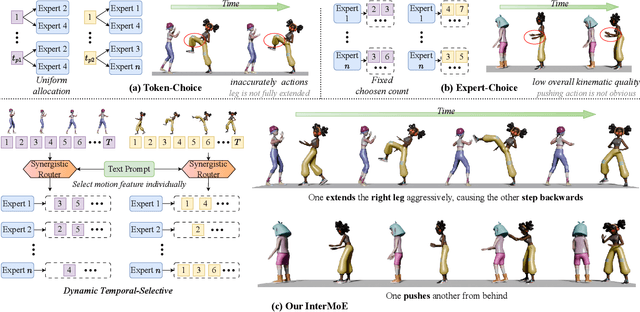
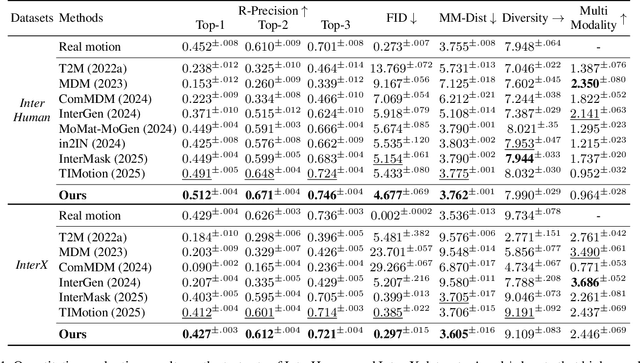
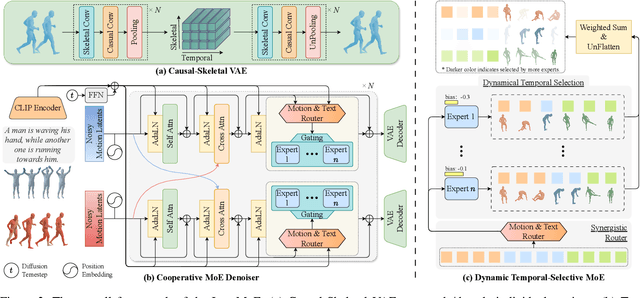
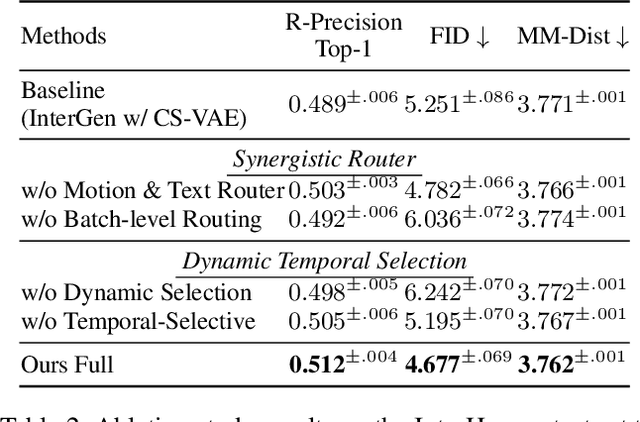
Generating high-quality human interactions holds significant value for applications like virtual reality and robotics. However, existing methods often fail to preserve unique individual characteristics or fully adhere to textual descriptions. To address these challenges, we introduce InterMoE, a novel framework built on a Dynamic Temporal-Selective Mixture of Experts. The core of InterMoE is a routing mechanism that synergistically uses both high-level text semantics and low-level motion context to dispatch temporal motion features to specialized experts. This allows experts to dynamically determine the selection capacity and focus on critical temporal features, thereby preserving specific individual characteristic identities while ensuring high semantic fidelity. Extensive experiments show that InterMoE achieves state-of-the-art performance in individual-specific high-fidelity 3D human interaction generation, reducing FID scores by 9% on the InterHuman dataset and 22% on InterX.
VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space
Aug 26, 2025



3D local editing of specified regions is crucial for game industry and robot interaction. Recent methods typically edit rendered multi-view images and then reconstruct 3D models, but they face challenges in precisely preserving unedited regions and overall coherence. Inspired by structured 3D generative models, we propose VoxHammer, a novel training-free approach that performs precise and coherent editing in 3D latent space. Given a 3D model, VoxHammer first predicts its inversion trajectory and obtains its inverted latents and key-value tokens at each timestep. Subsequently, in the denoising and editing phase, we replace the denoising features of preserved regions with the corresponding inverted latents and cached key-value tokens. By retaining these contextual features, this approach ensures consistent reconstruction of preserved areas and coherent integration of edited parts. To evaluate the consistency of preserved regions, we constructed Edit3D-Bench, a human-annotated dataset comprising hundreds of samples, each with carefully labeled 3D editing regions. Experiments demonstrate that VoxHammer significantly outperforms existing methods in terms of both 3D consistency of preserved regions and overall quality. Our method holds promise for synthesizing high-quality edited paired data, thereby laying the data foundation for in-context 3D generation. See our project page at https://huanngzh.github.io/VoxHammer-Page/.
AnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
Jun 24, 2025We present AnimaX, a feed-forward 3D animation framework that bridges the motion priors of video diffusion models with the controllable structure of skeleton-based animation. Traditional motion synthesis methods are either restricted to fixed skeletal topologies or require costly optimization in high-dimensional deformation spaces. In contrast, AnimaX effectively transfers video-based motion knowledge to the 3D domain, supporting diverse articulated meshes with arbitrary skeletons. Our method represents 3D motion as multi-view, multi-frame 2D pose maps, and enables joint video-pose diffusion conditioned on template renderings and a textual motion prompt. We introduce shared positional encodings and modality-aware embeddings to ensure spatial-temporal alignment between video and pose sequences, effectively transferring video priors to motion generation task. The resulting multi-view pose sequences are triangulated into 3D joint positions and converted into mesh animation via inverse kinematics. Trained on a newly curated dataset of 160,000 rigged sequences, AnimaX achieves state-of-the-art results on VBench in generalization, motion fidelity, and efficiency, offering a scalable solution for category-agnostic 3D animation. Project page: \href{https://anima-x.github.io/}{https://anima-x.github.io/}.
UniGeo: Taming Video Diffusion for Unified Consistent Geometry Estimation
May 30, 2025Recently, methods leveraging diffusion model priors to assist monocular geometric estimation (e.g., depth and normal) have gained significant attention due to their strong generalization ability. However, most existing works focus on estimating geometric properties within the camera coordinate system of individual video frames, neglecting the inherent ability of diffusion models to determine inter-frame correspondence. In this work, we demonstrate that, through appropriate design and fine-tuning, the intrinsic consistency of video generation models can be effectively harnessed for consistent geometric estimation. Specifically, we 1) select geometric attributes in the global coordinate system that share the same correspondence with video frames as the prediction targets, 2) introduce a novel and efficient conditioning method by reusing positional encodings, and 3) enhance performance through joint training on multiple geometric attributes that share the same correspondence. Our results achieve superior performance in predicting global geometric attributes in videos and can be directly applied to reconstruction tasks. Even when trained solely on static video data, our approach exhibits the potential to generalize to dynamic video scenes.
Personalize Anything for Free with Diffusion Transformer
Mar 16, 2025Personalized image generation aims to produce images of user-specified concepts while enabling flexible editing. Recent training-free approaches, while exhibit higher computational efficiency than training-based methods, struggle with identity preservation, applicability, and compatibility with diffusion transformers (DiTs). In this paper, we uncover the untapped potential of DiT, where simply replacing denoising tokens with those of a reference subject achieves zero-shot subject reconstruction. This simple yet effective feature injection technique unlocks diverse scenarios, from personalization to image editing. Building upon this observation, we propose \textbf{Personalize Anything}, a training-free framework that achieves personalized image generation in DiT through: 1) timestep-adaptive token replacement that enforces subject consistency via early-stage injection and enhances flexibility through late-stage regularization, and 2) patch perturbation strategies to boost structural diversity. Our method seamlessly supports layout-guided generation, multi-subject personalization, and mask-controlled editing. Evaluations demonstrate state-of-the-art performance in identity preservation and versatility. Our work establishes new insights into DiTs while delivering a practical paradigm for efficient personalization.
MIDI: Multi-Instance Diffusion for Single Image to 3D Scene Generation
Dec 04, 2024This paper introduces MIDI, a novel paradigm for compositional 3D scene generation from a single image. Unlike existing methods that rely on reconstruction or retrieval techniques or recent approaches that employ multi-stage object-by-object generation, MIDI extends pre-trained image-to-3D object generation models to multi-instance diffusion models, enabling the simultaneous generation of multiple 3D instances with accurate spatial relationships and high generalizability. At its core, MIDI incorporates a novel multi-instance attention mechanism, that effectively captures inter-object interactions and spatial coherence directly within the generation process, without the need for complex multi-step processes. The method utilizes partial object images and global scene context as inputs, directly modeling object completion during 3D generation. During training, we effectively supervise the interactions between 3D instances using a limited amount of scene-level data, while incorporating single-object data for regularization, thereby maintaining the pre-trained generalization ability. MIDI demonstrates state-of-the-art performance in image-to-scene generation, validated through evaluations on synthetic data, real-world scene data, and stylized scene images generated by text-to-image diffusion models.
MV-Adapter: Multi-view Consistent Image Generation Made Easy
Dec 04, 2024



Existing multi-view image generation methods often make invasive modifications to pre-trained text-to-image (T2I) models and require full fine-tuning, leading to (1) high computational costs, especially with large base models and high-resolution images, and (2) degradation in image quality due to optimization difficulties and scarce high-quality 3D data. In this paper, we propose the first adapter-based solution for multi-view image generation, and introduce MV-Adapter, a versatile plug-and-play adapter that enhances T2I models and their derivatives without altering the original network structure or feature space. By updating fewer parameters, MV-Adapter enables efficient training and preserves the prior knowledge embedded in pre-trained models, mitigating overfitting risks. To efficiently model the 3D geometric knowledge within the adapter, we introduce innovative designs that include duplicated self-attention layers and parallel attention architecture, enabling the adapter to inherit the powerful priors of the pre-trained models to model the novel 3D knowledge. Moreover, we present a unified condition encoder that seamlessly integrates camera parameters and geometric information, facilitating applications such as text- and image-based 3D generation and texturing. MV-Adapter achieves multi-view generation at 768 resolution on Stable Diffusion XL (SDXL), and demonstrates adaptability and versatility. It can also be extended to arbitrary view generation, enabling broader applications. We demonstrate that MV-Adapter sets a new quality standard for multi-view image generation, and opens up new possibilities due to its efficiency, adaptability and versatility.
Ouroboros3D: Image-to-3D Generation via 3D-aware Recursive Diffusion
Jun 05, 2024

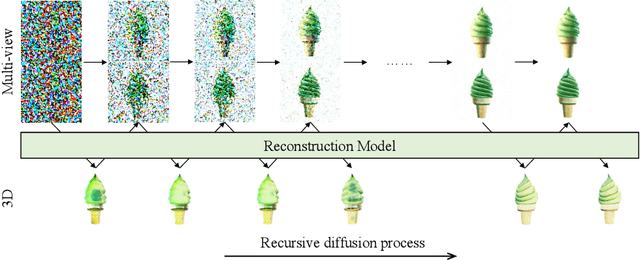

Existing single image-to-3D creation methods typically involve a two-stage process, first generating multi-view images, and then using these images for 3D reconstruction. However, training these two stages separately leads to significant data bias in the inference phase, thus affecting the quality of reconstructed results. We introduce a unified 3D generation framework, named Ouroboros3D, which integrates diffusion-based multi-view image generation and 3D reconstruction into a recursive diffusion process. In our framework, these two modules are jointly trained through a self-conditioning mechanism, allowing them to adapt to each other's characteristics for robust inference. During the multi-view denoising process, the multi-view diffusion model uses the 3D-aware maps rendered by the reconstruction module at the previous timestep as additional conditions. The recursive diffusion framework with 3D-aware feedback unites the entire process and improves geometric consistency.Experiments show that our framework outperforms separation of these two stages and existing methods that combine them at the inference phase. Project page: https://costwen.github.io/Ouroboros3D/
TELA: Text to Layer-wise 3D Clothed Human Generation
Apr 25, 2024



This paper addresses the task of 3D clothed human generation from textural descriptions. Previous works usually encode the human body and clothes as a holistic model and generate the whole model in a single-stage optimization, which makes them struggle for clothing editing and meanwhile lose fine-grained control over the whole generation process. To solve this, we propose a layer-wise clothed human representation combined with a progressive optimization strategy, which produces clothing-disentangled 3D human models while providing control capacity for the generation process. The basic idea is progressively generating a minimal-clothed human body and layer-wise clothes. During clothing generation, a novel stratified compositional rendering method is proposed to fuse multi-layer human models, and a new loss function is utilized to help decouple the clothing model from the human body. The proposed method achieves high-quality disentanglement, which thereby provides an effective way for 3D garment generation. Extensive experiments demonstrate that our approach achieves state-of-the-art 3D clothed human generation while also supporting cloth editing applications such as virtual try-on. Project page: http://jtdong.com/tela_layer/