 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusive Interactive Collisions for Multi-View Consistent Compositional 3D Generation
Jun 23, 2026Recent breakthroughs in 3D generation have advanced notably with the development of text-to-image diffusion model. However, existing methods remain two practical challenges: (1) They primarily generate single 3D object, but struggle to generate multi-object compositional 3D assets due to the lack of the modeling for Gaussian primitives in reasonable interactions. (2) They often suffer from cross-view inconsistency during 3D optimization, as Score Distillation Sampling inherently performs on each single view, inevitably resulting in cross-view hallucinations. To solve above issues, we propose I2C-3D, a novel optimization-based method to generate multi-view consistent compositional 3D assets with reasonable interactions. Specifically, we propose an Inclusive Interactive Collisions strategy to guide Gaussian primitives appearing in reasonable interaction regions naturally, thereby ensuring objects in the compositional scene interact in a physically plausible and visually coherent way. Additionally, to enhance multi-view consistency, Multi-View Adaptive Score Distillation Sampling is devised to distill multi-view consistency prior and layout prior from pre-trained diffusion model by modulating attention map of instance token and spatial token across viewpoints. Benefiting from above elaborate designs, I2C-3D not only generates high-fidelity multi-view consistent compositional 3D assets but also supports 3D editing flexibly, facilitating complex scene generation. Extensive experiments demonstrate our I2C-3D outperforms existing methods in generation quality and multi-view consistency.
Policy-as-Data: Learning Generalizable HOI Diffusion Models from Simulated Physics
Jun 22, 2026Synthesizing realistic Human-Object Interactions (HOI) is critical for creating embodied avatars and functional virtual environments. However, current data-driven approaches primarily rely on motion capture datasets, which are expensive to scale and limited in functional diversity. Models trained with these datasets fail to generalize to unseen objects and maintain physical consistency over long horizons. In this paper, we propose a novel framework that leverages a physics simulator to overcome the data-scarcity bottleneck in HOI generation. Specifically, we propose a scalable pipeline, called \ours, which leverages policies trained with reinforcement learning in a physics simulator for task-oriented data generation and trains a generative model on the augmented dataset for generalizable HOI generation. To seamlessly utilize the synthetic data, we introduce a coarse-to-fine retargeting process that bridges the representation gap between the simplified model used in physics simulator and the standard parametric body models required for generative training. Validated through comprehensive experiments, our method demonstrates enhanced generalization to unseen objects and the capability of long-horizon generation, while exhibiting greater dynamic diversity and physical plausibility.
CausalMotion: Structured Physical Reasoning as Keyframe and Trajectory Guidance for Training-Free Video Generation
Jun 12, 2026Recent advances in diffusion-based video generation have significantly improved visual quality and short-term temporal coherence. However, existing methods still struggle to produce videos with physically consistent and causally plausible dynamics, especially in scenarios involving long-horizon interactions. This limitation arises from the fact that video diffusion models primarily learn physical consistency implicitly, while vision-language models can directly model physical laws. Based on this idea, in this work, we propose \textbf{CausalMotion}, a training-free framework that injects explicit physical reasoning into video generation through structured intermediate representations. Our key idea is to decouple reasoning from generation by leveraging a vision-language model to decompose a text prompt into a sequence of causally consistent keyframes and object-centric motion trajectories. These representations are then aligned and integrated as soft constraints to guide a pretrained video diffusion model during inference. This design enables explicit modeling of object dynamics and causal transitions without requiring additional training or supervision. Extensive experiments show that our method consistently improves physical plausibility and temporal coherence, particularly in dynamics-intensive scenarios, while maintaining high perceptual video quality.
BEAT: Rhythm-Elastic Alignment for Agentic Music-guided Movie Trailer Generation
May 26, 2026Automatic movie trailer generation must select shots from a full-length film and synchronize them with background music. Existing methods either relegate music alignment to post-processing or enforce rigid one-to-one shot-music mappings, overlooking that professional editing rhythm is elastic: rapid cuts accompany high-energy passages while sustained shots span quieter bars. We introduce BEAT, a framework that addresses this gap with two core components: MuVA, a compact music-visual alignment encoder trained with Sinkhorn-regularized two-stage learning, and Bar-DP, an energy-adaptive dynamic programming algorithm that produces elastic many-to-one alignments following musical dynamics. These components are integrated into a five-phase agentic pipeline that grounds the core alignment in learned cross-modal features while coordinating higher-level creative decisions through structured text signals. To support comprehensive evaluation, we also introduce TrailerArena, a benchmark with 20+ metrics across four complementary dimensions. On TrailerArena, BEAT achieves state-of-the-art performance across shot selection, ordering, and perceptual quality, while producing fully composed trailers end-to-end.
PARE: Pruning and Adaptive Routing for Efficient Video Generation
May 26, 2026Video Diffusion Transformers (DiTs) generate high-quality videos but demand substantial compute due to wide blocks, deep architectures, and iterative sampling. Recent methods reduce cost by compressing width, depth, or sampling steps, but typically commit to a fixed architecture that cannot adapt to individual inputs or denoising stages. We propose PARE (Pruning and Adaptive Routing for Efficient video generation), which jointly compresses width and depth with structure-aware pruning and input-adaptive routing. For width, we observe that attention heads specialize into spatial and temporal roles, and design importance scoring that accounts for this distinction to prevent motion-critical temporal heads from being pruned prematurely. For depth, we train a lightweight router conditioned on denoising timestep and visual content to dynamically select which blocks to execute at each step, enabling per-input compute adaptation rather than static block removal. A progressive pipeline first recovers width-pruned quality via distillation, then jointly optimizes the student and router to decouple the two learning objectives. Experiments on Wan2.1-14B for both image-to-video and text-to-video generation show that PARE substantially reduces per-step computation while preserving quality across VBench dimensions, and composes with step distillation for further acceleration.
LamPO: A Lambda Style Policy Optimization for Reasoning Language Models
May 20, 2026Reinforcement learning with verifiable rewards (RLVR) has become an effective paradigm for improving reasoning language models on tasks such as mathematics, coding, and scientific question answering. However, widely used group-relative objectives, such as GRPO, summarize each sampled group with scalar statistics and therefore discard fine-grained relational information among candidate responses. This weakens credit assignment under sparse outcome rewards, especially when multiple generated solutions differ only subtly in reasoning quality. We propose \textbf{LamPO}, a \textbf{Lambda-Style Policy Optimization} method that replaces scalar group advantages with a \emph{Pairwise Decomposed Advantage}. LamPO aggregates pairwise reward gaps within each response group and modulates each comparison by a confidence-aware weight computed from sequence log-probability differences, while retaining the critic-free and clipped-update structure of PPO-style optimization. When reference solutions are available, we further add a lightweight ROUGE-L-based dense auxiliary reward to reduce reward sparsity. Experiments on AIME24, AIME25, MATH-500, and GPQA-Diamond with Qwen3-1.7B, Qwen3-4B, and Phi-4-mini show that LamPO consistently improves over GRPO and recent RLVR variants, with more stable training dynamics and better sample efficiency.
LambdaPO: A Lambda Style Policy Optimization for Reasoning Language Models
May 19, 2026Group Relative Policy Optimization(GRPO) has become a cornerstone of modern reinforcement learning alignment, prized for its efficacy in foregoing an explicit value-critic by leveraging reward normalization across sampled trajectory cohorts. However, the method's reliance on a monolithic statistical baseline, such as the group mean, collapses the relational topology of the trajectory space into a single scalar, thereby erasing the fine-grained preference information essential for navigating complex, rank-sensitive reward landscapes. To address this issue, we introduce a novel framework, Lambda Policy Optimization (LambdaPO), that addresses this information-theoretic bottleneck by re-conceptualizing advantage estimation from a scalar value to a decomposed, pairwise preference structure. Specifically, the advantage for any given trajectory is formulated as the integrated sum of reward differentials against all peers in its cohort, where each pairwise comparison is dynamically attenuated by the policy's own probabilistic confidence in the established preference. To further mitigate the sparsity of binary outcome supervision, we augment the objective with a semantic density reward, derived from the precision-recall alignment between generated reasoning traces and ground-truth solutions. As a result, our method can mine more fine-grained optimization signals from a group of rollouts, guiding the LLM to a better optima. Experimental results across challenging math reasoning and question-answering tasks demonstrates that LambdaPO improves performance compared to the baseline methods.
Uni-Animator: Towards Unified Visual Colorization
Feb 26, 2026We propose Uni-Animator, a novel Diffusion Transformer (DiT)-based framework for unified image and video sketch colorization. Existing sketch colorization methods struggle to unify image and video tasks, suffering from imprecise color transfer with single or multiple references, inadequate preservation of high-frequency physical details, and compromised temporal coherence with motion artifacts in large-motion scenes. To tackle imprecise color transfer, we introduce visual reference enhancement via instance patch embedding, enabling precise alignment and fusion of reference color information. To resolve insufficient physical detail preservation, we design physical detail reinforcement using physical features that effectively capture and retain high-frequency textures. To mitigate motion-induced temporal inconsistency, we propose sketch-based dynamic RoPE encoding that adaptively models motion-aware spatial-temporal dependencies. Extensive experimental results demonstrate that Uni-Animator achieves competitive performance on both image and video sketch colorization, matching that of task-specific methods while unlocking unified cross-domain capabilities with high detail fidelity and robust temporal consistency.
ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions
Dec 11, 2025
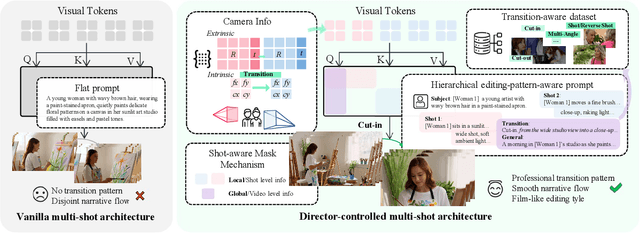

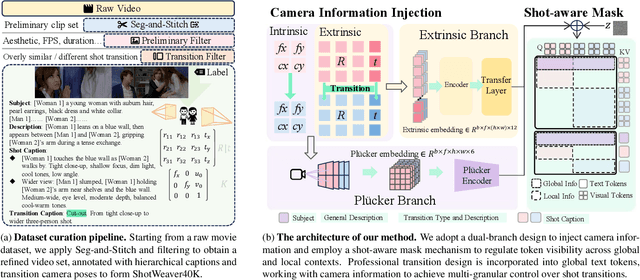
Shot transitions play a pivotal role in multi-shot video generation, as they determine the overall narrative expression and the directorial design of visual storytelling. However, recent progress has primarily focused on low-level visual consistency across shots, neglecting how transitions are designed and how cinematographic language contributes to coherent narrative expression. This often leads to mere sequential shot changes without intentional film-editing patterns. To address this limitation, we propose ShotDirector, an efficient framework that integrates parameter-level camera control and hierarchical editing-pattern-aware prompting. Specifically, we adopt a camera control module that incorporates 6-DoF poses and intrinsic settings to enable precise camera information injection. In addition, a shot-aware mask mechanism is employed to introduce hierarchical prompts aware of professional editing patterns, allowing fine-grained control over shot content. Through this design, our framework effectively combines parameter-level conditions with high-level semantic guidance, achieving film-like controllable shot transitions. To facilitate training and evaluation, we construct ShotWeaver40K, a dataset that captures the priors of film-like editing patterns, and develop a set of evaluation metrics for controllable multi-shot video generation. Extensive experiments demonstrate the effectiveness of our framework.
LIA-X: Interpretable Latent Portrait Animator
Aug 13, 2025We introduce LIA-X, a novel interpretable portrait animator designed to transfer facial dynamics from a driving video to a source portrait with fine-grained control. LIA-X is an autoencoder that models motion transfer as a linear navigation of motion codes in latent space. Crucially, it incorporates a novel Sparse Motion Dictionary that enables the model to disentangle facial dynamics into interpretable factors. Deviating from previous 'warp-render' approaches, the interpretability of the Sparse Motion Dictionary allows LIA-X to support a highly controllable 'edit-warp-render' strategy, enabling precise manipulation of fine-grained facial semantics in the source portrait. This helps to narrow initial differences with the driving video in terms of pose and expression. Moreover, we demonstrate the scalability of LIA-X by successfully training a large-scale model with approximately 1 billion parameters on extensive datasets. Experimental results show that our proposed method outperforms previous approaches in both self-reenactment and cross-reenactment tasks across several benchmarks. Additionally, the interpretable and controllable nature of LIA-X supports practical applications such as fine-grained, user-guided image and video editing, as well as 3D-aware portrait video manipulation.