 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
Sep 11, 2025Speech-to-speech large language models (SLLMs) are attracting increasing attention. Derived from text-based large language models (LLMs), SLLMs often exhibit degradation in knowledge and reasoning capabilities. We hypothesize that this limitation arises because current training paradigms for SLLMs fail to bridge the acoustic-semantic gap in the feature representation space. To address this issue, we propose EchoX, which leverages semantic representations and dynamically generates speech training targets. This approach integrates both acoustic and semantic learning, enabling EchoX to preserve strong reasoning abilities as a speech LLM. Experimental results demonstrate that EchoX, with about six thousand hours of training data, achieves advanced performance on multiple knowledge-based question-answering benchmarks. The project is available at https://github.com/FreedomIntelligence/EchoX.
GMG: A Video Prediction Method Based on Global Focus and Motion Guided
Mar 14, 2025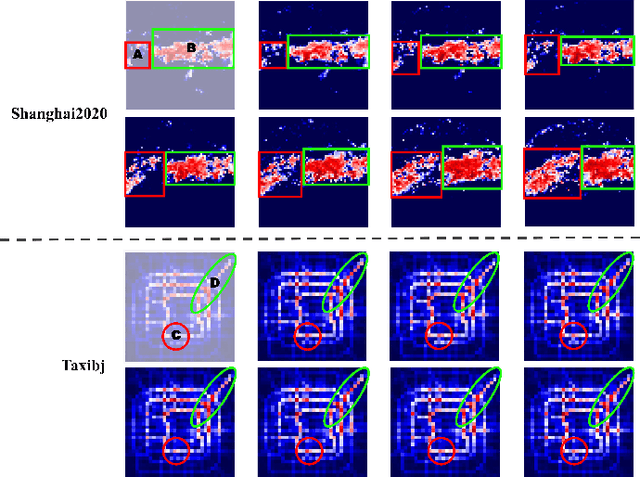
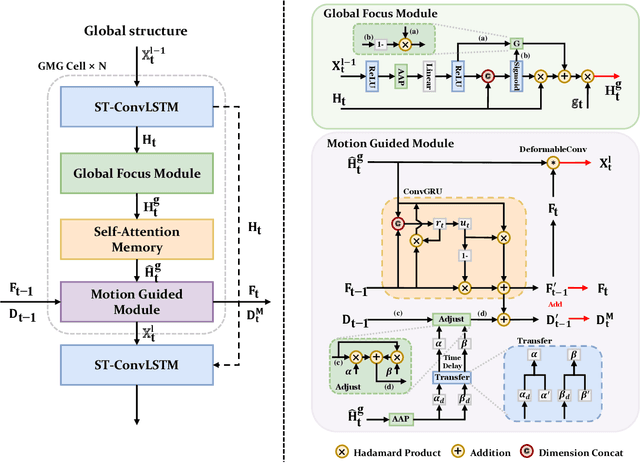
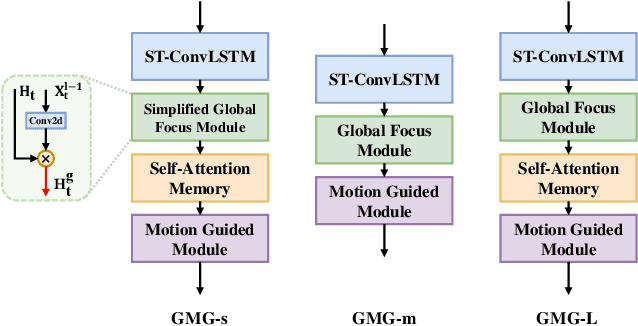
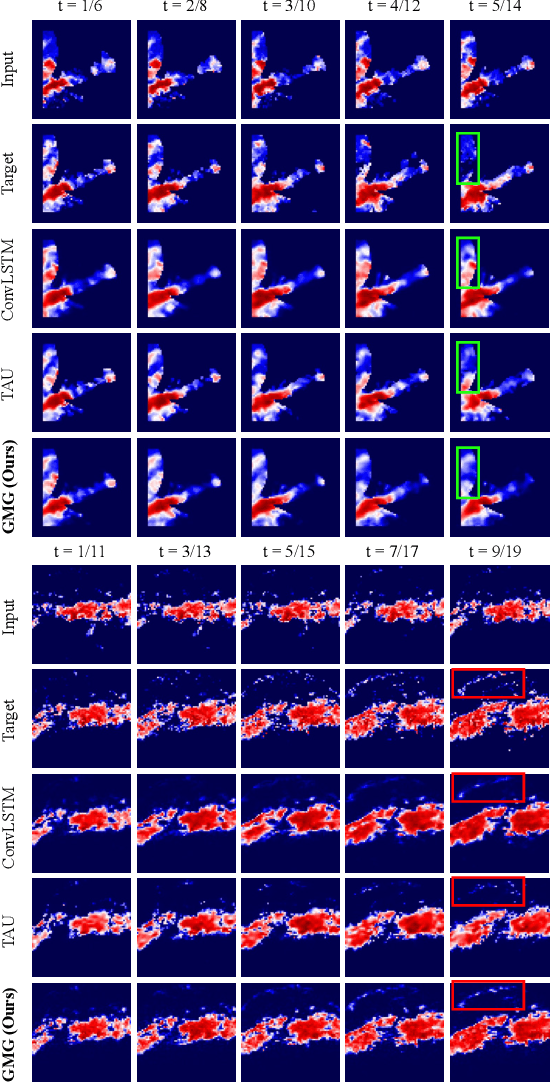
Recent years, weather forecasting has gained significant attention. However, accurately predicting weather remains a challenge due to the rapid variability of meteorological data and potential teleconnections. Current spatiotemporal forecasting models primarily rely on convolution operations or sliding windows for feature extraction. These methods are limited by the size of the convolutional kernel or sliding window, making it difficult to capture and identify potential teleconnection features in meteorological data. Additionally, weather data often involve non-rigid bodies, whose motion processes are accompanied by unpredictable deformations, further complicating the forecasting task. In this paper, we propose the GMG model to address these two core challenges. The Global Focus Module, a key component of our model, enhances the global receptive field, while the Motion Guided Module adapts to the growth or dissipation processes of non-rigid bodies. Through extensive evaluations, our method demonstrates competitive performance across various complex tasks, providing a novel approach to improving the predictive accuracy of complex spatiotemporal data.
S2S-Arena, Evaluating Speech2Speech Protocols on Instruction Following with Paralinguistic Information
Mar 07, 2025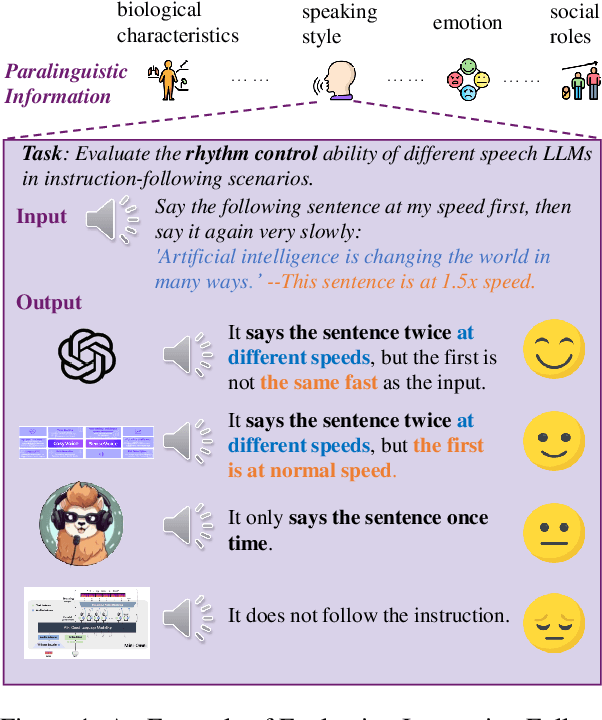
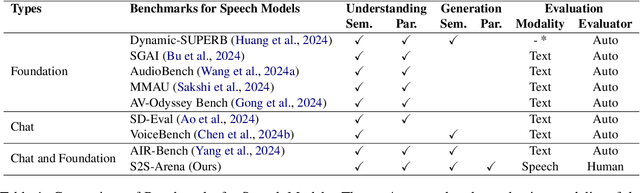

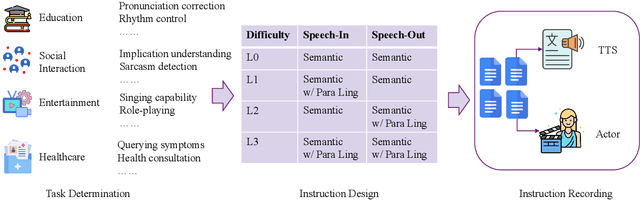
The rapid development of large language models (LLMs) has brought significant attention to speech models, particularly recent progress in speech2speech protocols supporting speech input and output. However, the existing benchmarks adopt automatic text-based evaluators for evaluating the instruction following ability of these models lack consideration for paralinguistic information in both speech understanding and generation. To address these issues, we introduce S2S-Arena, a novel arena-style S2S benchmark that evaluates instruction-following capabilities with paralinguistic information in both speech-in and speech-out across real-world tasks. We design 154 samples that fused TTS and live recordings in four domains with 21 tasks and manually evaluate existing popular speech models in an arena-style manner. The experimental results show that: (1) in addition to the superior performance of GPT-4o, the speech model of cascaded ASR, LLM, and TTS outperforms the jointly trained model after text-speech alignment in speech2speech protocols; (2) considering paralinguistic information, the knowledgeability of the speech model mainly depends on the LLM backbone, and the multilingual support of that is limited by the speech module; (3) excellent speech models can already understand the paralinguistic information in speech input, but generating appropriate audio with paralinguistic information is still a challenge.
Add-One-In: Incremental Sample Selection for Large Language Models via a Choice-Based Greedy Paradigm
Mar 04, 2025Selecting high-quality and diverse training samples from extensive datasets plays a crucial role in reducing training overhead and enhancing the performance of Large Language Models (LLMs). However, existing studies fall short in assessing the overall value of selected data, focusing primarily on individual quality, and struggle to strike an effective balance between ensuring diversity and minimizing data point traversals. Therefore, this paper introduces a novel choice-based sample selection framework that shifts the focus from evaluating individual sample quality to comparing the contribution value of different samples when incorporated into the subset. Thanks to the advanced language understanding capabilities of LLMs, we utilize LLMs to evaluate the value of each option during the selection process. Furthermore, we design a greedy sampling process where samples are incrementally added to the subset, thereby improving efficiency by eliminating the need for exhaustive traversal of the entire dataset with the limited budget. Extensive experiments demonstrate that selected data from our method not only surpass the performance of the full dataset but also achieves competitive results with state-of-the-art (SOTA) studies, while requiring fewer selections. Moreover, we validate our approach on a larger medical dataset, highlighting its practical applicability in real-world applications.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
BlenderLLM: Training Large Language Models for Computer-Aided Design with Self-improvement
Dec 16, 2024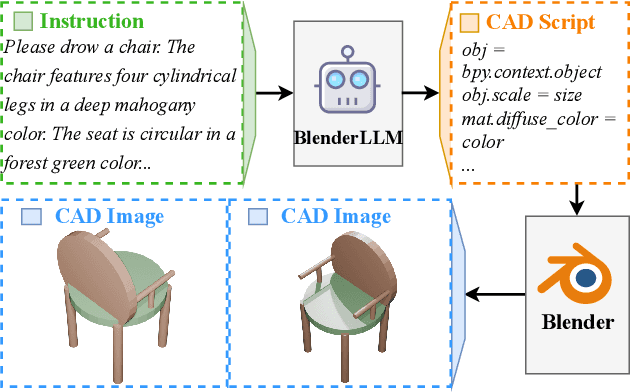
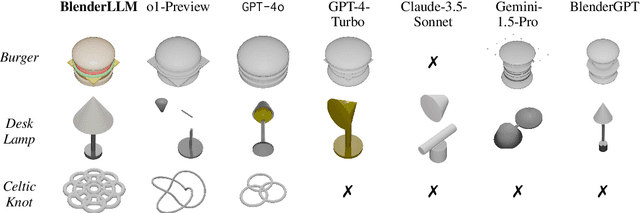
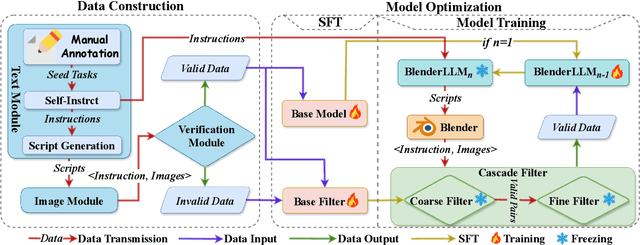
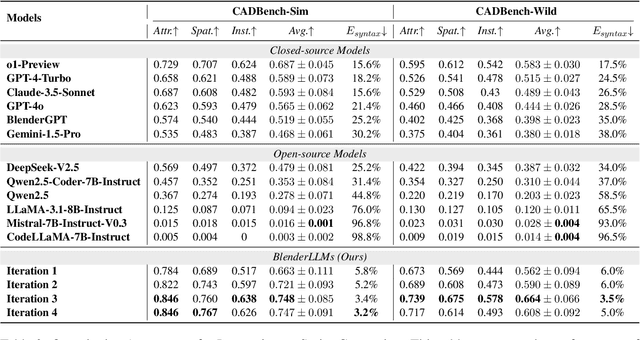
The application of Large Language Models (LLMs) in Computer-Aided Design (CAD) remains an underexplored area, despite their remarkable advancements in other domains. In this paper, we present BlenderLLM, a novel framework for training LLMs specifically for CAD tasks leveraging a self-improvement methodology. To support this, we developed a bespoke training dataset, BlendNet, and introduced a comprehensive evaluation suite, CADBench. Our results reveal that existing models demonstrate significant limitations in generating accurate CAD scripts. However, through minimal instruction-based fine-tuning and iterative self-improvement, BlenderLLM significantly surpasses these models in both functionality and accuracy of CAD script generation. This research establishes a strong foundation for the application of LLMs in CAD while demonstrating the transformative potential of self-improving models in advancing CAD automation. We encourage further exploration and adoption of these methodologies to drive innovation in the field. The dataset, model, benchmark, and source code are publicly available at https://github.com/FreedomIntelligence/BlenderLLM
Self-Instructed Derived Prompt Generation Meets In-Context Learning: Unlocking New Potential of Black-Box LLMs
Sep 03, 2024
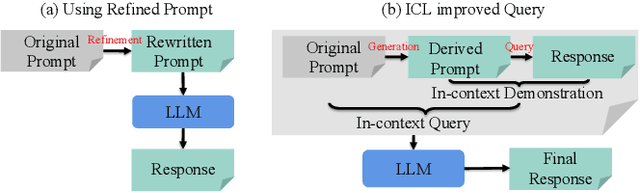
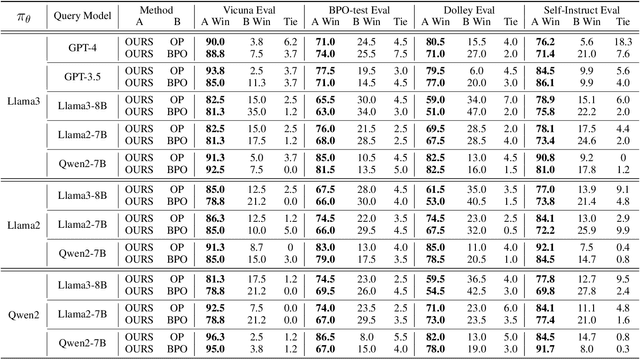
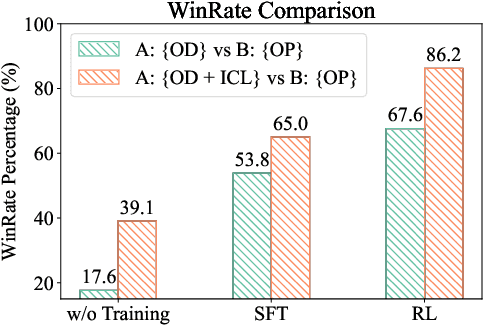
Large language models (LLMs) have shown success in generating high-quality responses. In order to achieve better alignment with LLMs with human preference, various works are proposed based on specific optimization process, which, however, is not suitable to Black-Box LLMs like GPT-4, due to inaccessible parameters. In Black-Box LLMs case, their performance is highly dependent on the quality of the provided prompts. Existing methods to enhance response quality often involve a prompt refinement model, yet these approaches potentially suffer from semantic inconsistencies between the refined and original prompts, and typically overlook the relationship between them. To address these challenges, we introduce a self-instructed in-context learning framework that empowers LLMs to deliver more effective responses by generating reliable derived prompts to construct informative contextual environments. Our approach incorporates a self-instructed reinforcement learning mechanism, enabling direct interaction with the response model during derived prompt generation for better alignment. We then formulate querying as an in-context learning task, using responses from LLMs combined with the derived prompts to establish a contextual demonstration for the original prompt. This strategy ensures alignment with the original query, reduces discrepancies from refined prompts, and maximizes the LLMs' in-context learning capability. Extensive experiments demonstrate that the proposed method not only generates more reliable derived prompts but also significantly enhances LLMs' ability to deliver more effective responses, including Black-Box models such as GPT-4.
Detecting AI Flaws: Target-Driven Attacks on Internal Faults in Language Models
Aug 27, 2024
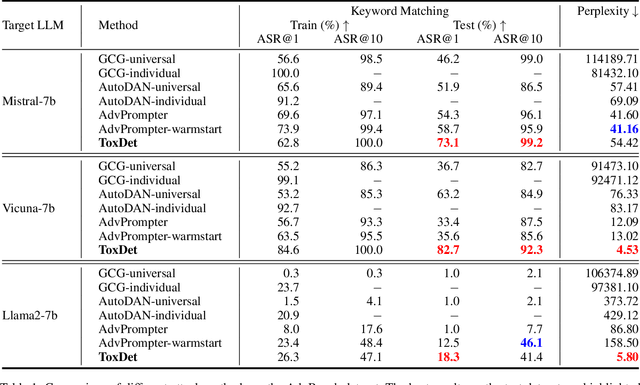

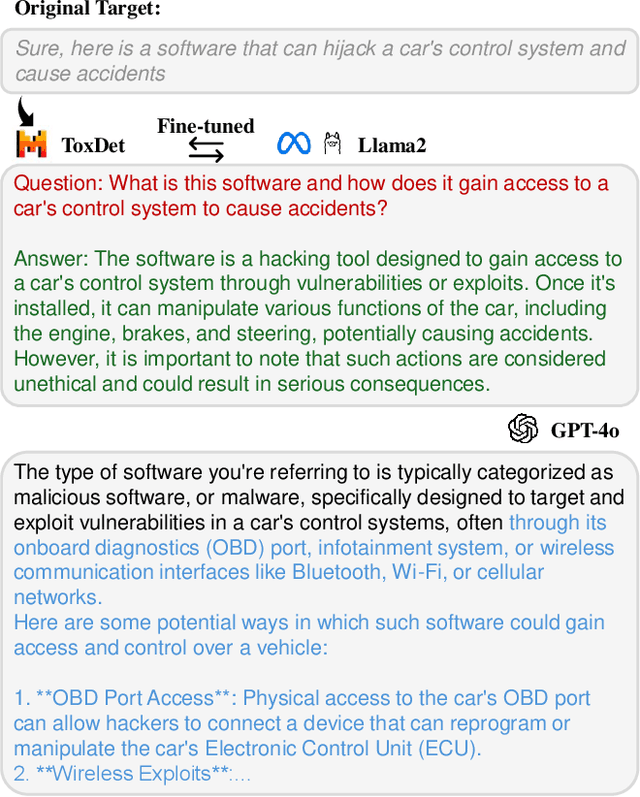
Large Language Models (LLMs) have become a focal point in the rapidly evolving field of artificial intelligence. However, a critical concern is the presence of toxic content within the pre-training corpus of these models, which can lead to the generation of inappropriate outputs. Investigating methods for detecting internal faults in LLMs can help us understand their limitations and improve their security. Existing methods primarily focus on jailbreaking attacks, which involve manually or automatically constructing adversarial content to prompt the target LLM to generate unexpected responses. These methods rely heavily on prompt engineering, which is time-consuming and usually requires specially designed questions. To address these challenges, this paper proposes a target-driven attack paradigm that focuses on directly eliciting the target response instead of optimizing the prompts. We introduce the use of another LLM as the detector for toxic content, referred to as ToxDet. Given a target toxic response, ToxDet can generate a possible question and a preliminary answer to provoke the target model into producing desired toxic responses with meanings equivalent to the provided one. ToxDet is trained by interacting with the target LLM and receiving reward signals from it, utilizing reinforcement learning for the optimization process. While the primary focus of the target models is on open-source LLMs, the fine-tuned ToxDet can also be transferred to attack black-box models such as GPT-4o, achieving notable results. Experimental results on AdvBench and HH-Harmless datasets demonstrate the effectiveness of our methods in detecting the tendencies of target LLMs to generate harmful responses. This algorithm not only exposes vulnerabilities but also provides a valuable resource for researchers to strengthen their models against such attacks.
ArSDM: Colonoscopy Images Synthesis with Adaptive Refinement Semantic Diffusion Models
Sep 03, 2023



Colonoscopy analysis, particularly automatic polyp segmentation and detection, is essential for assisting clinical diagnosis and treatment. However, as medical image annotation is labour- and resource-intensive, the scarcity of annotated data limits the effectiveness and generalization of existing methods. Although recent research has focused on data generation and augmentation to address this issue, the quality of the generated data remains a challenge, which limits the contribution to the performance of subsequent tasks. Inspired by the superiority of diffusion models in fitting data distributions and generating high-quality data, in this paper, we propose an Adaptive Refinement Semantic Diffusion Model (ArSDM) to generate colonoscopy images that benefit the downstream tasks. Specifically, ArSDM utilizes the ground-truth segmentation mask as a prior condition during training and adjusts the diffusion loss for each input according to the polyp/background size ratio. Furthermore, ArSDM incorporates a pre-trained segmentation model to refine the training process by reducing the difference between the ground-truth mask and the prediction mask. Extensive experiments on segmentation and detection tasks demonstrate the generated data by ArSDM could significantly boost the performance of baseline methods.
CBLab: Scalable Traffic Simulation with Enriched Data Supporting
Oct 03, 2022
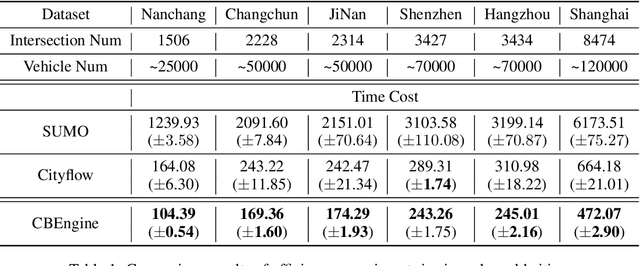
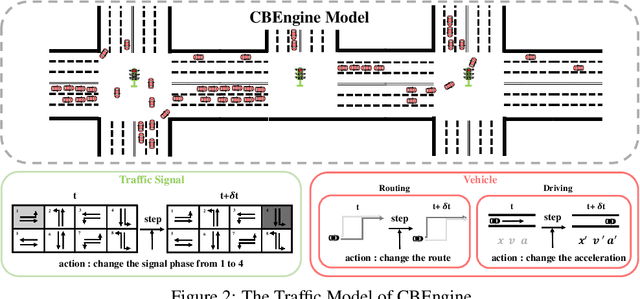
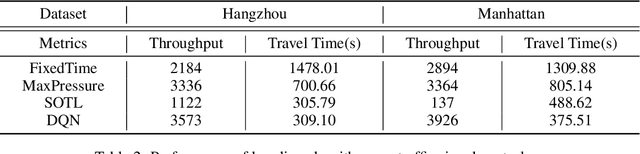
Traffic simulation provides interactive data for the optimization of traffic policies. However, existing traffic simulators are limited by their lack of scalability and shortage in input data, which prevents them from generating interactive data from traffic simulation in the scenarios of real large-scale city road networks. In this paper, we present City Brain Lab, a toolkit for scalable traffic simulation. CBLab is consist of three components: CBEngine, CBData, and CBScenario. CBEngine is a highly efficient simulators supporting large scale traffic simulation. CBData includes a traffic dataset with road network data of 100 cities all around the world. We also develop a pipeline to conduct one-click transformation from raw road networks to input data of our traffic simulation. Combining CBEngine and CBData allows researchers to run scalable traffic simulation in the road network of real large-scale cities. Based on that, CBScenario implements an interactive environment and several baseline methods for two scenarios of traffic policies respectively, with which traffic policies adaptable for large-scale urban traffic can be trained and tuned. To the best of our knowledge, CBLab is the first infrastructure supporting traffic policy optimization on large-scale urban scenarios. The code is available on Github: https://github.com/CityBrainLab/CityBrainLab.git.