 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebugging Tabular Log as Dynamic Graphs
Dec 28, 2025Tabular log abstracts objects and events in the real-world system and reports their updates to reflect the change of the system, where one can detect real-world inconsistencies efficiently by debugging corresponding log entries. However, recent advances in processing text-enriched tabular log data overly depend on large language models (LLMs) and other heavy-load models, thus suffering from limited flexibility and scalability. This paper proposes a new framework, GraphLogDebugger, to debug tabular log based on dynamic graphs. By constructing heterogeneous nodes for objects and events and connecting node-wise edges, the framework recovers the system behind the tabular log as an evolving dynamic graph. With the help of our dynamic graph modeling, a simple dynamic Graph Neural Network (GNN) is representative enough to outperform LLMs in debugging tabular log, which is validated by experimental results on real-world log datasets of computer systems and academic papers.
DiagramEval: Evaluating LLM-Generated Diagrams via Graphs
Oct 29, 2025



Diagrams play a central role in research papers for conveying ideas, yet they are often notoriously complex and labor-intensive to create. Although diagrams are presented as images, standard image generative models struggle to produce clear diagrams with well-defined structure. We argue that a promising direction is to generate demonstration diagrams directly in textual form as SVGs, which can leverage recent advances in large language models (LLMs). However, due to the complexity of components and the multimodal nature of diagrams, sufficiently discriminative and explainable metrics for evaluating the quality of LLM-generated diagrams remain lacking. In this paper, we propose DiagramEval, a novel evaluation metric designed to assess demonstration diagrams generated by LLMs. Specifically, DiagramEval conceptualizes diagrams as graphs, treating text elements as nodes and their connections as directed edges, and evaluates diagram quality using two new groups of metrics: node alignment and path alignment. For the first time, we effectively evaluate diagrams produced by state-of-the-art LLMs on recent research literature, quantitatively demonstrating the validity of our metrics. Furthermore, we show how the enhanced explainability of our proposed metrics offers valuable insights into the characteristics of LLM-generated diagrams. Code: https://github.com/ulab-uiuc/diagram-eval.
Online Reward-Weighted Fine-Tuning of Flow Matching with Wasserstein Regularization
Feb 09, 2025



Recent advancements in reinforcement learning (RL) have achieved great success in fine-tuning diffusion-based generative models. However, fine-tuning continuous flow-based generative models to align with arbitrary user-defined reward functions remains challenging, particularly due to issues such as policy collapse from overoptimization and the prohibitively high computational cost of likelihoods in continuous-time flows. In this paper, we propose an easy-to-use and theoretically sound RL fine-tuning method, which we term Online Reward-Weighted Conditional Flow Matching with Wasserstein-2 Regularization (ORW-CFM-W2). Our method integrates RL into the flow matching framework to fine-tune generative models with arbitrary reward functions, without relying on gradients of rewards or filtered datasets. By introducing an online reward-weighting mechanism, our approach guides the model to prioritize high-reward regions in the data manifold. To prevent policy collapse and maintain diversity, we incorporate Wasserstein-2 (W2) distance regularization into our method and derive a tractable upper bound for it in flow matching, effectively balancing exploration and exploitation of policy optimization. We provide theoretical analyses to demonstrate the convergence properties and induced data distributions of our method, establishing connections with traditional RL algorithms featuring Kullback-Leibler (KL) regularization and offering a more comprehensive understanding of the underlying mechanisms and learning behavior of our approach. Extensive experiments on tasks including target image generation, image compression, and text-image alignment demonstrate the effectiveness of our method, where our method achieves optimal policy convergence while allowing controllable trade-offs between reward maximization and diversity preservation.
AMM: Adaptive Modularized Reinforcement Model for Multi-city Traffic Signal Control
Jan 05, 2025



Traffic signal control (TSC) is an important and widely studied direction. Recently, reinforcement learning (RL) methods have been used to solve TSC problems and achieve superior performance over conventional TSC methods. However, applying RL methods to the real world is challenging due to the huge cost of experiments in real-world traffic environments. One possible solution is TSC domain adaptation, which adapts trained models to target environments and reduces the number of interactions and the training cost. However, existing TSC domain adaptation methods still face two major issues: the lack of consideration for differences across cities and the low utilization of multi-city data. To solve aforementioned issues, we propose an approach named Adaptive Modularized Model (AMM). By modularizing TSC problems and network models, we overcome the challenge of possible changes in environmental observations. We also aggregate multi-city experience through meta-learning. We conduct extensive experiments on different cities and show that AMM can achieve excellent performance with limited interactions in target environments and outperform existing methods. We also demonstrate the feasibility and generalizability of our method.
Real-World Benchmarks Make Membership Inference Attacks Fail on Diffusion Models
Oct 04, 2024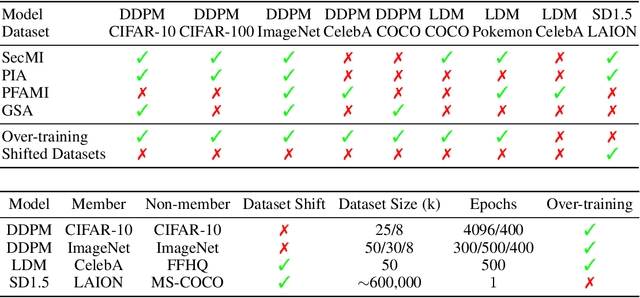
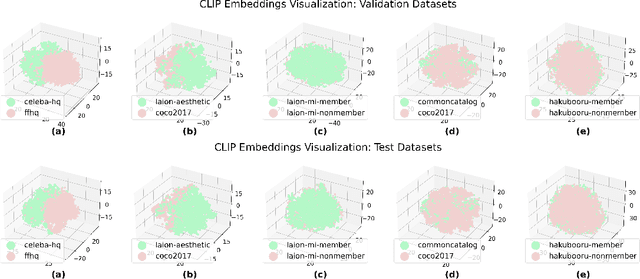

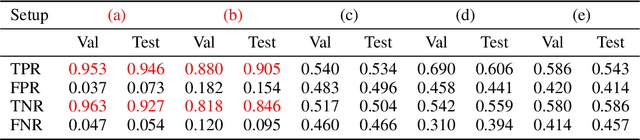
Membership inference attacks (MIAs) on diffusion models have emerged as potential evidence of unauthorized data usage in training pre-trained diffusion models. These attacks aim to detect the presence of specific images in training datasets of diffusion models. Our study delves into the evaluation of state-of-the-art MIAs on diffusion models and reveals critical flaws and overly optimistic performance estimates in existing MIA evaluation. We introduce CopyMark, a more realistic MIA benchmark that distinguishes itself through the support for pre-trained diffusion models, unbiased datasets, and fair evaluation pipelines. Through extensive experiments, we demonstrate that the effectiveness of current MIA methods significantly degrades under these more practical conditions. Based on our results, we alert that MIA, in its current state, is not a reliable approach for identifying unauthorized data usage in pre-trained diffusion models. To the best of our knowledge, we are the first to discover the performance overestimation of MIAs on diffusion models and present a unified benchmark for more realistic evaluation. Our code is available on GitHub: \url{https://github.com/caradryanl/CopyMark}.
CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion
Mar 17, 2024


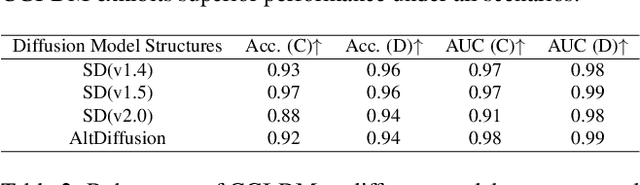
Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot generation where a pretrained model is fine-tuned on a small set of images to capture a specific style or object. Despite their success, concerns exist about potential copyright violations stemming from the use of unauthorized data in this process. In response, we present Contrasting Gradient Inversion for Diffusion Models (CGI-DM), a novel method featuring vivid visual representations for digital copyright authentication. Our approach involves removing partial information of an image and recovering missing details by exploiting conceptual differences between the pretrained and fine-tuned models. We formulate the differences as KL divergence between latent variables of the two models when given the same input image, which can be maximized through Monte Carlo sampling and Projected Gradient Descent (PGD). The similarity between original and recovered images serves as a strong indicator of potential infringements. Extensive experiments on the WikiArt and Dreambooth datasets demonstrate the high accuracy of CGI-DM in digital copyright authentication, surpassing alternative validation techniques. Code implementation is available at https://github.com/Nicholas0228/Revelio.
Understanding and Improving Adversarial Attacks on Latent Diffusion Model
Oct 07, 2023



Latent Diffusion Model (LDM) has emerged as a leading tool in image generation, particularly with its capability in few-shot generation. This capability also presents risks, notably in unauthorized artwork replication and misinformation generation. In response, adversarial attacks have been designed to safeguard personal images from being used as reference data. However, existing adversarial attacks are predominantly empirical, lacking a solid theoretical foundation. In this paper, we introduce a comprehensive theoretical framework for understanding adversarial attacks on LDM. Based on the framework, we propose a novel adversarial attack that exploits a unified target to guide the adversarial attack both in the forward and the reverse process of LDM. We provide empirical evidences that our method overcomes the offset problem of the optimization of adversarial attacks in existing methods. Through rigorous experiments, our findings demonstrate that our method outperforms current attacks and is able to generalize over different state-of-the-art few-shot generation pipelines based on LDM. Our method can serve as a stronger and efficient tool for people exposed to the risk of data privacy and security to protect themselves in the new era of powerful generative models. The code is available on GitHub: https://github.com/CaradryanLiang/ImprovedAdvDM.git.
FDTI: Fine-grained Deep Traffic Inference with Roadnet-enriched Graph
Jun 19, 2023This paper proposes the fine-grained traffic prediction task (e.g. interval between data points is 1 minute), which is essential to traffic-related downstream applications. Under this setting, traffic flow is highly influenced by traffic signals and the correlation between traffic nodes is dynamic. As a result, the traffic data is non-smooth between nodes, and hard to utilize previous methods which focus on smooth traffic data. To address this problem, we propose Fine-grained Deep Traffic Inference, termed as FDTI. Specifically, we construct a fine-grained traffic graph based on traffic signals to model the inter-road relations. Then, a physically-interpretable dynamic mobility convolution module is proposed to capture vehicle moving dynamics controlled by the traffic signals. Furthermore, traffic flow conservation is introduced to accurately infer future volume. Extensive experiments demonstrate that our method achieves state-of-the-art performance and learned traffic dynamics with good properties. To the best of our knowledge, we are the first to conduct the city-level fine-grained traffic prediction.
Mist: Towards Improved Adversarial Examples for Diffusion Models
May 22, 2023


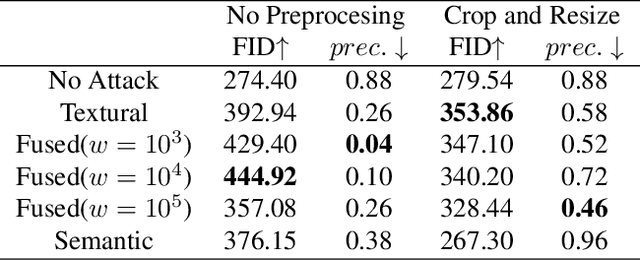
Diffusion Models (DMs) have empowered great success in artificial-intelligence-generated content, especially in artwork creation, yet raising new concerns in intellectual properties and copyright. For example, infringers can make profits by imitating non-authorized human-created paintings with DMs. Recent researches suggest that various adversarial examples for diffusion models can be effective tools against these copyright infringements. However, current adversarial examples show weakness in transferability over different painting-imitating methods and robustness under straightforward adversarial defense, for example, noise purification. We surprisingly find that the transferability of adversarial examples can be significantly enhanced by exploiting a fused and modified adversarial loss term under consistent parameters. In this work, we comprehensively evaluate the cross-method transferability of adversarial examples. The experimental observation shows that our method generates more transferable adversarial examples with even stronger robustness against the simple adversarial defense.
Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
Feb 09, 2023



Diffusion Models (DMs) achieve state-of-the-art performance in generative tasks, boosting a wave in AI for Art. Despite the success of commercialization, DMs meanwhile provide tools for copyright violations, where infringers benefit from illegally using paintings created by human artists to train DMs and generate novel paintings in a similar style. In this paper, we show that it is possible to create an image $x'$ that is similar to an image $x$ for human vision but unrecognizable for DMs. We build a framework to define and evaluate this adversarial example for diffusion models. Based on the framework, we further propose AdvDM, an algorithm to generate adversarial examples for DMs. By optimizing upon different latent variables sampled from the reverse process of DMs, AdvDM conducts a Monte-Carlo estimation of adversarial examples for DMs. Extensive experiments show that the estimated adversarial examples can effectively hinder DMs from extracting their features. Our method can be a powerful tool for human artists to protect their copyright against infringers with DM-based AI-for-Art applications.