 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianJi-Environ: An Autonomous AI Scientist for Atmospheric Environmental Research
Jun 05, 2026As atmospheric environmental prediction continues to improve, interpretable validation of pollution mechanisms and feedback processes has become a main challenge in atmospheric chemistry. Yet mechanism validation based on complex numerical models still relies heavily on expert knowledge: mechanistic hypotheses must be operationalized into executable experiments, and model outputs must be organized into traceable evidence. We present TianJi-Environ, an auditable AI Scientist for atmospheric-chemistry mechanism validation. TianJi-Environ establishes the first WRF-Chem-based multi-agent framework that autonomously drives complex atmospheric-chemistry simulations, converting mechanistic hypotheses into executable configurations, testing experiments, and evidence criteria. Using ozone response and particulate-matter feedback as two representative examples, we demonstrate TianJi-Environ's capability for mechanism validation. In a summertime ozone case over the North China Plain, the system detects directionally consistent aerosol-radiation-interaction signals in shortwave radiation and boundary-layer height, but judges the evidence for ozone response to NOx control to be incomplete. In a wintertime PM2.5 case over the Guanzhong Basin, it localizes the unsupported link to insufficient propagation from black-carbon perturbation to particulate response and missing diagnostics of vertical absorptive heating. These results show that TianJi-Environ makes expert-driven mechanism validation explicit, structured, and auditable, offering a reproducible paradigm for multi-agent systems coupled with complex atmospheric-chemistry models.
Echoes within the Reasoning: Stealthy and Effective Watermarking via Chain of Thought
May 27, 2026Large Language Models with Chain-of-Thought reasoning capabilities represent valuable intellectual property, yet existing black-box watermarking methods often trade robustness for reasoning fidelity by perturbing final answers or relying on fragile trigger patterns. We propose BiCoT, a watermarking framework that embeds ownership signals into the internal geometry of reasoning traces by aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens to preserve semantic capacity. This design couples the watermark with reasoning-relevant representations, making removal difficult without disrupting the features that support coherent reasoning. To enable verification under model theft and representation drift, we introduce Robust Subspace Registration (RSR), a Top- logprob-based black-box verifier that uses sentinel tokens to calibrate systematic shifts in the output distribution. Experiments show that BiCoT preserves reasoning fidelity across diverse complex reasoning tasks while achieving robust detection under fine-tuning, quantization, model-level perturbations, and adaptive output-level attacks across in-domain and out-of-distribution settings.
SCT-MOT: Enhancing Air-to-Air Multiple UAVs Tracking with Swarm-Coupled Motion and Trajectory Guidance
Apr 08, 2026Air-to-air tracking of swarm UAVs presents significant challenges due to the complex nonlinear group motion and weak visual cues for small objects, which often cause detection failures, trajectory fragmentation, and identity switches. Although existing methods have attempted to improve performance by incorporating trajectory prediction, they model each object independently, neglecting the swarm-level motion dependencies. Their limited integration between motion prediction and appearance representation also weakens the spatio-temporal consistency required for tracking in visually ambiguous and cluttered environments, making it difficult to maintain coherent trajectories and reliable associations. To address these challenges, we propose SCT-MOT, a tracking framework that integrates Swarm-Coupled motion modeling and Trajectory-guided feature fusion. First, we develop a Swarm Motion-Aware Trajectory Prediction (SMTP) module jointly models historical trajectories and posture-aware appearance features from a swarm-level perspective, enabling more accurate forecasting of the nonlinear, coupled group trajectories. Second, we design a Trajectory-Guided Spatio-Temporal Feature Fusion (TG-STFF) module aligns predicted positions with historical visual cues and deeply integrates them with current frame features, enhancing temporal consistency and spatial discriminability for weak objects. Extensive experiments on three public air-to-air swarm UAV tracking datasets, including AIRMOT, MOT-FLY, and UAVSwarm, demonstrate that SMTP achieves more accurate trajectory forecasts and yields a 1.21\% IDF1 improvement over the state-of-the-art trajectory prediction module EqMotion when integrated into the same MOT framework. Overall, our SCT-MOT consistently achieves superior accuracy and robustness compared to state-of-the-art trackers across multiple metrics under complex swarm scenarios.
TianJi:An autonomous AI meteorologist for discovering physical mechanisms in atmospheric science
Mar 29, 2026Artificial intelligence (AI) has achieved breakthroughs comparable to traditional numerical models in data-driven weather forecasting, yet it remains essentially statistical fitting and struggles to uncover the physical causal mechanisms of the atmosphere. Physics-oriented mechanism research still heavily relies on domain knowledge and cumbersome engineering operations of human scientists, becoming a bottleneck restricting the efficiency of Earth system science exploration. Here, we propose TianJi - the first "AI meteorologist" system capable of autonomously driving complex numerical models to verify physical mechanisms. Powered by a large language model-driven multi-agent architecture, TianJi can autonomously conduct literature research and generate scientific hypotheses. We further decouple scientific research into cognitive planning and engineering execution: the meta-planner interprets hypotheses and devises experimental roadmaps, while a cohort of specialized worker agents collaboratively complete data preparation, model configuration, and multi-dimensional result analysis. In two classic atmospheric dynamic scenarios (squall-line cold pools and typhoon track deflections), TianJi accomplishes expert-level end-to-end experimental operations with zero human intervention, compressing the research cycle to a few hours. It also delivers detailed result analyses and autonomously judges and explains the validity of the hypotheses from outputs. TianJi reveals that the role of AI in Earth system science is transitioning from a "black-box predictor" to an "interpretable scientific collaborator", offering a new paradigm for high-throughput exploration of scientific mechanisms.
FedMomentum: Preserving LoRA Training Momentum in Federated Fine-Tuning
Mar 09, 2026Federated fine-tuning of large language models (LLMs) with low-rank adaptation (LoRA) offers a communication-efficient and privacy-preserving solution for task-specific adaptation. Naive aggregation of LoRA modules introduces noise due to mathematical incorrectness when averaging the downsampling and upsampling matrices independently. However, existing noise-free aggregation strategies inevitably compromise the structural expressiveness of LoRA, limiting its ability to retain client-specific adaptations by either improperly reconstructing the low-rank structure or excluding partially trainable components. We identify this problem as loss of training momentum, where LoRA updates fail to accumulate effectively across rounds, resulting in slower convergence and suboptimal performance. To address this, we propose FedMomentum, a novel framework that enables structured and momentum-preserving LoRA aggregation via singular value decomposition (SVD). Specifically, after aggregating low-rank updates in a mathematically correct manner, FedMomentum applies SVD to extract the dominant components that capture the main update directions. These components are used to reconstruct the LoRA modules with the same rank, while residual components can be retained and later merged into the backbone to preserve semantic information and ensure robustness. Extensive experiments across multiple tasks demonstrate that FedMomentum consistently outperforms prior state-of-the-art methods in convergence speed and final accuracy.
SettleFL: Trustless and Scalable Reward Settlement Protocol for Federated Learning on Permissionless Blockchains (Extended version)
Feb 26, 2026In open Federated Learning (FL) environments where no central authority exists, ensuring collaboration fairness relies on decentralized reward settlement, yet the prohibitive cost of permissionless blockchains directly clashes with the high-frequency, iterative nature of model training. Existing solutions either compromise decentralization or suffer from scalability bottlenecks due to linear on-chain costs. To address this, we present SettleFL, a trustless and scalable reward settlement protocol designed to minimize total economic friction by offering a family of two interoperable protocols. Leveraging a shared domain-specific circuit architecture, SettleFL offers two interoperable strategies: (1) a Commit-and-Challenge variant that minimizes on-chain costs via optimistic execution and dispute-driven arbitration, and (2) a Commit-with-Proof variant that guarantees instant finality through per-round validity proofs. This design allows the protocol to flexibly adapt to varying latency and cost constraints while enforcing rational robustness without trusted coordination. We conduct extensive experiments combining real FL workloads and controlled simulations. Results show that SettleFL remains practical when scaling to 800 participants, achieving substantially lower gas cost.
pFedNavi: Structure-Aware Personalized Federated Vision-Language Navigation for Embodied AI
Feb 16, 2026Vision-Language Navigation VLN requires large-scale trajectory instruction data from private indoor environments, raising significant privacy concerns. Federated Learning FL mitigates this by keeping data on-device, but vanilla FL struggles under VLNs' extreme cross-client heterogeneity in environments and instruction styles, making a single global model suboptimal. This paper proposes pFedNavi, a structure-aware and dynamically adaptive personalized federated learning framework tailored for VLN. Our key idea is to personalize where it matters: pFedNavi adaptively identifies client-specific layers via layer-wise mixing coefficients, and performs fine-grained parameter fusion on the selected components (e.g., the encoder-decoder projection and environment-sensitive decoder layers) to balance global knowledge sharing with local specialization. We evaluate pFedNavi on two standard VLN benchmarks, R2R and RxR, using both ResNet and CLIP visual representations. Across all metrics, pFedNavi consistently outperforms the FedAvg-based VLN baseline, achieving up to 7.5% improvement in navigation success rate and up to 7.8% gain in trajectory fidelity, while converging 1.38x faster under non-IID conditions.
CADET: Context-Conditioned Ads CTR Prediction With a Decoder-Only Transformer
Feb 11, 2026Click-through rate (CTR) prediction is fundamental to online advertising systems. While Deep Learning Recommendation Models (DLRMs) with explicit feature interactions have long dominated this domain, recent advances in generative recommenders have shown promising results in content recommendation. However, adapting these transformer-based architectures to ads CTR prediction still presents unique challenges, including handling post-scoring contextual signals, maintaining offline-online consistency, and scaling to industrial workloads. We present CADET (Context-Conditioned Ads Decoder-Only Transformer), an end-to-end decoder-only transformer for ads CTR prediction deployed at LinkedIn. Our approach introduces several key innovations: (1) a context-conditioned decoding architecture with multi-tower prediction heads that explicitly model post-scoring signals such as ad position, resolving the chicken-and-egg problem between predicted CTR and ranking; (2) a self-gated attention mechanism that stabilizes training by adaptively regulating information flow at both representation and interaction levels; (3) a timestamp-based variant of Rotary Position Embedding (RoPE) that captures temporal relationships across timescales from seconds to months; (4) session masking strategies that prevent the model from learning dependencies on unavailable in-session events, addressing train-serve skew; and (5) production engineering techniques including tensor packing, sequence chunking, and custom Flash Attention kernels that enable efficient training and serving at scale. In online A/B testing, CADET achieves a 11.04\% CTR lift compared to the production LiRank baseline model, a hybrid ensemble of DCNv2 and sequential encoders. The system has been successfully deployed on LinkedIn's advertising platform, serving the main traffic for homefeed sponsored updates.
Intelligent Multimodal Multi-Sensor Fusion-Based UAV Identification, Localization, and Countermeasures for Safeguarding Low-Altitude Economy
Oct 27, 2025The development of the low-altitude economy has led to a growing prominence of uncrewed aerial vehicle (UAV) safety management issues. Therefore, accurate identification, real-time localization, and effective countermeasures have become core challenges in airspace security assurance. This paper introduces an integrated UAV management and control system based on deep learning, which integrates multimodal multi-sensor fusion perception, precise positioning, and collaborative countermeasures. By incorporating deep learning methods, the system combines radio frequency (RF) spectral feature analysis, radar detection, electro-optical identification, and other methods at the detection level to achieve the identification and classification of UAVs. At the localization level, the system relies on multi-sensor data fusion and the air-space-ground integrated communication network to conduct real-time tracking and prediction of UAV flight status, providing support for early warning and decision-making. At the countermeasure level, it adopts comprehensive measures that integrate ``soft kill'' and ``hard kill'', including technologies such as electromagnetic signal jamming, navigation spoofing, and physical interception, to form a closed-loop management and control process from early warning to final disposal, which significantly enhances the response efficiency and disposal accuracy of low-altitude UAV management.
POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025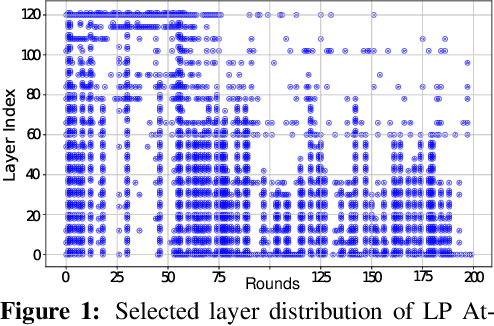



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.