 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trustworthy Selective Generation: Reliability-Guided Diffusion for Ultra-Low-Field to High-Field MRI Synthesis
Mar 11, 2026Low-field to high-field MRI synthesis has emerged as a cost-effective strategy to enhance image quality under hardware and acquisition constraints, particularly in scenarios where access to high-field scanners is limited or impractical. Despite recent progress in diffusion models, diffusion-based approaches often struggle to balance fine-detail recovery and structural fidelity. In particular, the uncontrolled generation of high-resolution details in structurally ambiguous regions may introduce anatomically inconsistent patterns, such as spurious edges or artificial texture variations. These artifacts can bias downstream quantitative analysis. For example, they may cause inaccurate tissue boundary delineation or erroneous volumetric estimation, ultimately reducing clinical trust in synthesized images. These limitations highlight the need for generative models that are not only visually accurate but also spatially reliable and anatomically consistent. To address this issue, we propose a reliability-aware diffusion framework (ReDiff) that improves synthesis robustness at both the sampling and post-generation stages. Specifically, we introduce a reliability-guided sampling strategy to suppress unreliable responses during the denoising process. We further develop an uncertainty-aware multi-candidate selection scheme to enhance the reliability of the final prediction. Experiments on multi-center MRI datasets demonstrate improved structural fidelity and reduced artifacts compared with state-of-the-art methods.
M2Diff: Multi-Modality Multi-Task Enhanced Diffusion Model for MRI-Guided Low-Dose PET Enhancement
Mar 10, 2026Positron emission tomography (PET) scans expose patients to radiation, which can be mitigated by reducing the dose, albeit at the cost of diminished quality. This makes low-dose (LD) PET recovery an active research area. Previous studies have focused on standard-dose (SD) PET recovery from LD PET scans and/or multi-modal scans, e.g., PET/CT or PET/MRI, using deep learning. While these studies incorporate multi-modal information through conditioning in a single-task model, such approaches may limit the capacity to extract modality-specific features, potentially leading to early feature dilution. Although recent studies have begun incorporating pathology-rich data, challenges remain in effectively leveraging multi-modality inputs for reconstructing diverse features, particularly in heterogeneous patient populations. To address these limitations, we introduce a multi-modality multi-task diffusion model (M2Diff) that processes MRI and LD PET scans separately to learn modality-specific features and fuse them via hierarchical feature fusion to reconstruct SD PET. This design enables effective integration of complementary structural and functional information, leading to improved reconstruction fidelity. We have validated the effectiveness of our model on both healthy and Alzheimer's disease brain datasets. The M2Diff achieves superior qualitative and quantitative performance on both datasets.
Segment Any Tumour: An Uncertainty-Aware Vision Foundation Model for Whole-Body Analysis
Nov 11, 2025Prompt-driven vision foundation models, such as the Segment Anything Model, have recently demonstrated remarkable adaptability in computer vision. However, their direct application to medical imaging remains challenging due to heterogeneous tissue structures, imaging artefacts, and low-contrast boundaries, particularly in tumours and cancer primaries leading to suboptimal segmentation in ambiguous or overlapping lesion regions. Here, we present Segment Any Tumour 3D (SAT3D), a lightweight volumetric foundation model designed to enable robust and generalisable tumour segmentation across diverse medical imaging modalities. SAT3D integrates a shifted-window vision transformer for hierarchical volumetric representation with an uncertainty-aware training pipeline that explicitly incorporates uncertainty estimates as prompts to guide reliable boundary prediction in low-contrast regions. Adversarial learning further enhances model performance for the ambiguous pathological regions. We benchmark SAT3D against three recent vision foundation models and nnUNet across 11 publicly available datasets, encompassing 3,884 tumour and cancer cases for training and 694 cases for in-distribution evaluation. Trained on 17,075 3D volume-mask pairs across multiple modalities and cancer primaries, SAT3D demonstrates strong generalisation and robustness. To facilitate practical use and clinical translation, we developed a 3D Slicer plugin that enables interactive, prompt-driven segmentation and visualisation using the trained SAT3D model. Extensive experiments highlight its effectiveness in improving segmentation accuracy under challenging and out-of-distribution scenarios, underscoring its potential as a scalable foundation model for medical image analysis.
Style Content Decomposition-based Data Augmentation for Domain Generalizable Medical Image Segmentation
Feb 28, 2025Due to the domain shifts between training and testing medical images, learned segmentation models often experience significant performance degradation during deployment. In this paper, we first decompose an image into its style code and content map and reveal that domain shifts in medical images involve: \textbf{style shifts} (\emph{i.e.}, differences in image appearance) and \textbf{content shifts} (\emph{i.e.}, variations in anatomical structures), the latter of which has been largely overlooked. To this end, we propose \textbf{StyCona}, a \textbf{sty}le \textbf{con}tent decomposition-based data \textbf{a}ugmentation method that innovatively augments both image style and content within the rank-one space, for domain generalizable medical image segmentation. StyCona is a simple yet effective plug-and-play module that substantially improves model generalization without requiring additional training parameters or modifications to the segmentation model architecture. Experiments on cross-sequence, cross-center, and cross-modality medical image segmentation settings with increasingly severe domain shifts, demonstrate the effectiveness of StyCona and its superiority over state-of-the-arts. The code is available at https://github.com/Senyh/StyCona.
CodeBrain: Impute Any Brain MRI via Instance-specific Scalar-quantized Codes
Jan 30, 2025MRI imputation aims to synthesize the missing modality from one or more available ones, which is highly desirable since it reduces scanning costs and delivers comprehensive MRI information to enhance clinical diagnosis. In this paper, we propose a unified model, CodeBrain, designed to adapt to various brain MRI imputation scenarios. The core design lies in casting various inter-modality transformations as a full-modality code prediction task. To this end, CodeBrain is trained in two stages: Reconstruction and Code Prediction. First, in the Reconstruction stage, we reconstruct each MRI modality, which is mapped into a shared latent space followed by a scalar quantization. Since such quantization is lossy and the code is low dimensional, another MRI modality belonging to the same subject is randomly selected to generate common features to supplement the code and boost the target reconstruction. In the second stage, we train another encoder by a customized grading loss to predict the full-modality codes from randomly masked MRI samples, supervised by the corresponding quantized codes generated from the first stage. In this way, the inter-modality transformation is achieved by mapping the instance-specific codes in a finite scalar space. We evaluated the proposed CodeBrain model on two public brain MRI datasets (i.e., IXI and BraTS 2023). Extensive experiments demonstrate that our CodeBrain model achieves superior imputation performance compared to four existing methods, establishing a new state of the art for unified brain MRI imputation. Codes will be released.
A Physics-based Generative Model to Synthesize Training Datasets for MRI-based Fat Quantification
Dec 11, 2024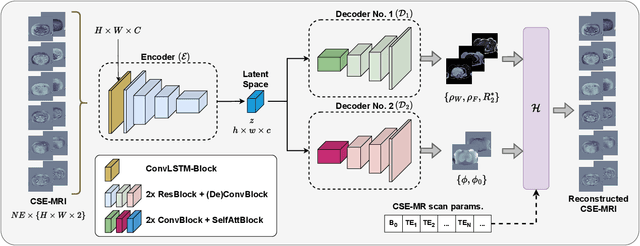
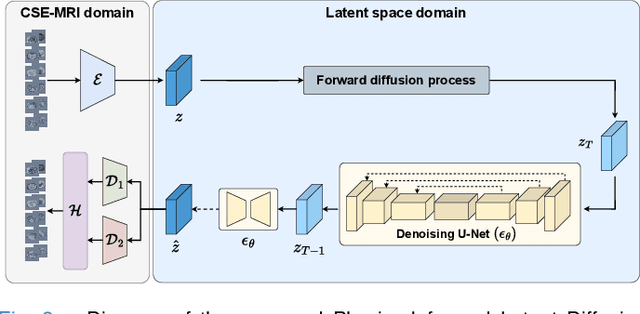
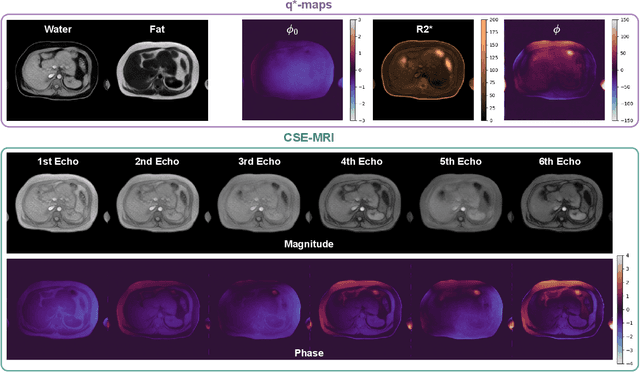
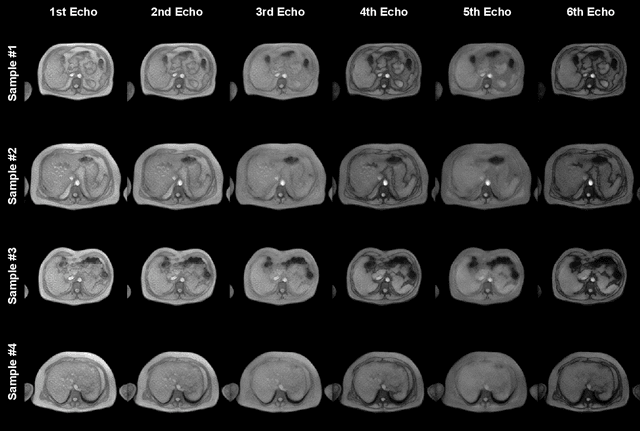
Deep learning-based techniques have potential to optimize scan and post-processing times required for MRI-based fat quantification, but they are constrained by the lack of large training datasets. Generative models are a promising tool to perform data augmentation by synthesizing realistic datasets. However no previous methods have been specifically designed to generate datasets for quantitative MRI (q-MRI) tasks, where reference quantitative maps and large variability in scanning protocols are usually required. We propose a Physics-Informed Latent Diffusion Model (PI-LDM) to synthesize quantitative parameter maps jointly with customizable MR images by incorporating the signal generation model. We assessed the quality of PI-LDM's synthesized data using metrics such as the Fr\'echet Inception Distance (FID), obtaining comparable scores to state-of-the-art generative methods (FID: 0.0459). We also trained a U-Net for the MRI-based fat quantification task incorporating synthetic datasets. When we used a few real (10 subjects, $~200$ slices) and numerous synthetic samples ($>3000$), fat fraction at specific liver ROIs showed a low bias on data obtained using the same protocol than training data ($0.10\%$ at $\hbox{ROI}_1$, $0.12\%$ at $\hbox{ROI}_2$) and on data acquired with an alternative protocol ($0.14\%$ at $\hbox{ROI}_1$, $0.62\%$ at $\hbox{ROI}_2$). Future work will be to extend PI-LDM to other q-MRI applications.
Bilateral Hippocampi Segmentation in Low Field MRIs Using Mutual Feature Learning via Dual-Views
Oct 23, 2024



Accurate hippocampus segmentation in brain MRI is critical for studying cognitive and memory functions and diagnosing neurodevelopmental disorders. While high-field MRIs provide detailed imaging, low-field MRIs are more accessible and cost-effective, which eliminates the need for sedation in children, though they often suffer from lower image quality. In this paper, we present a novel deep-learning approach for the automatic segmentation of bilateral hippocampi in low-field MRIs. Extending recent advancements in infant brain segmentation to underserved communities through the use of low-field MRIs ensures broader access to essential diagnostic tools, thereby supporting better healthcare outcomes for all children. Inspired by our previous work, Co-BioNet, the proposed model employs a dual-view structure to enable mutual feature learning via high-frequency masking, enhancing segmentation accuracy by leveraging complementary information from different perspectives. Extensive experiments demonstrate that our method provides reliable segmentation outcomes for hippocampal analysis in low-resource settings. The code is publicly available at: https://github.com/himashi92/LoFiHippSeg.
Deep kernel representations of latent space features for low-dose PET-MR imaging robust to variable dose reduction
Sep 10, 2024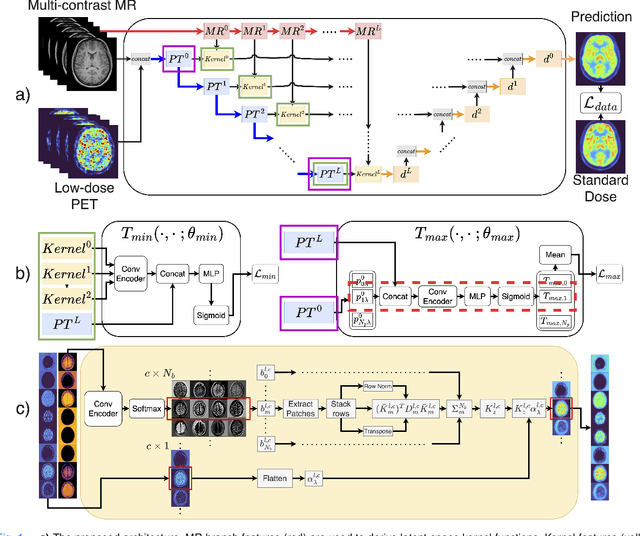
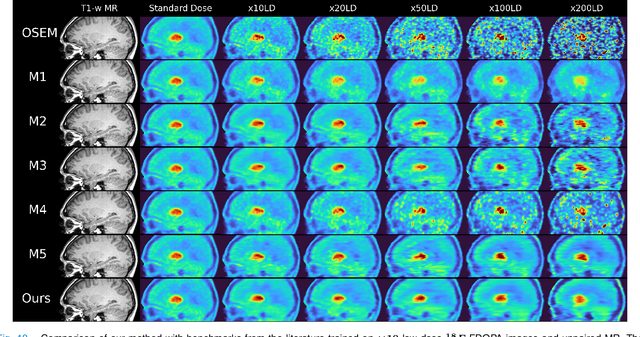
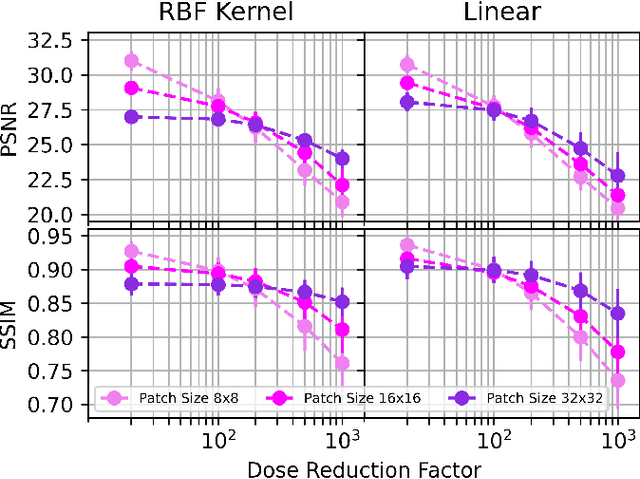
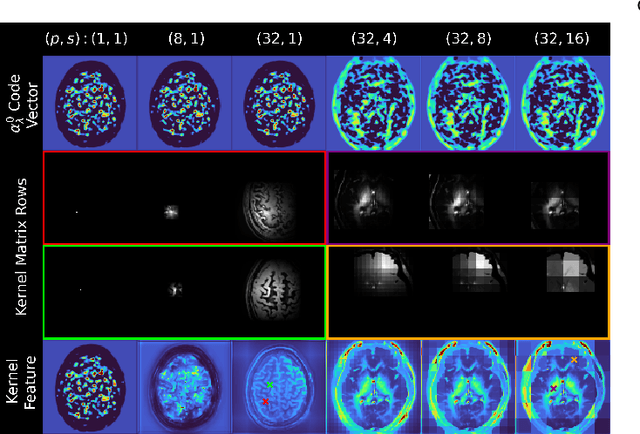
Low-dose positron emission tomography (PET) image reconstruction methods have potential to significantly improve PET as an imaging modality. Deep learning provides a promising means of incorporating prior information into the image reconstruction problem to produce quantitatively accurate images from compromised signal. Deep learning-based methods for low-dose PET are generally poorly conditioned and perform unreliably on images with features not present in the training distribution. We present a method which explicitly models deep latent space features using a robust kernel representation, providing robust performance on previously unseen dose reduction factors. Additional constraints on the information content of deep latent features allow for tuning in-distribution accuracy and generalisability. Tests with out-of-distribution dose reduction factors ranging from $\times 10$ to $\times 1000$ and with both paired and unpaired MR, demonstrate significantly improved performance relative to conventional deep-learning methods trained using the same data. Code:https://github.com/cameronPain
SeCo-INR: Semantically Conditioned Implicit Neural Representations for Improved Medical Image Super-Resolution
Sep 02, 2024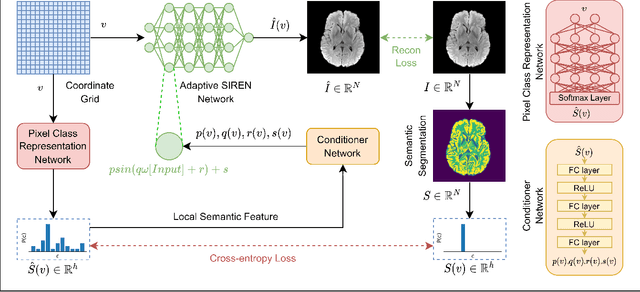
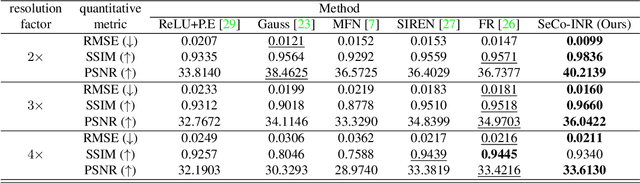
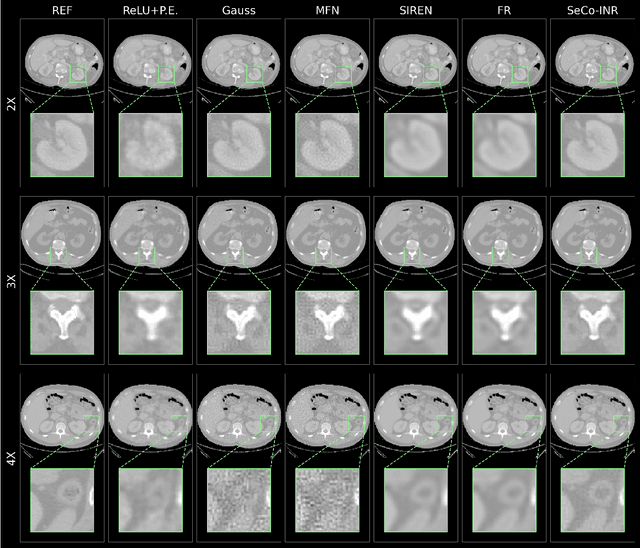
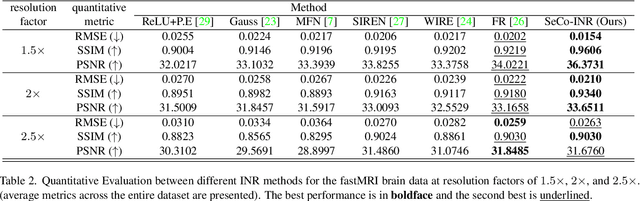
Implicit Neural Representations (INRs) have recently advanced the field of deep learning due to their ability to learn continuous representations of signals without the need for large training datasets. Although INR methods have been studied for medical image super-resolution, their adaptability to localized priors in medical images has not been extensively explored. Medical images contain rich anatomical divisions that could provide valuable local prior information to enhance the accuracy and robustness of INRs. In this work, we propose a novel framework, referred to as the Semantically Conditioned INR (SeCo-INR), that conditions an INR using local priors from a medical image, enabling accurate model fitting and interpolation capabilities to achieve super-resolution. Our framework learns a continuous representation of the semantic segmentation features of a medical image and utilizes it to derive the optimal INR for each semantic region of the image. We tested our framework using several medical imaging modalities and achieved higher quantitative scores and more realistic super-resolution outputs compared to state-of-the-art methods.
McCaD: Multi-Contrast MRI Conditioned, Adaptive Adversarial Diffusion Model for High-Fidelity MRI Synthesis
Sep 01, 2024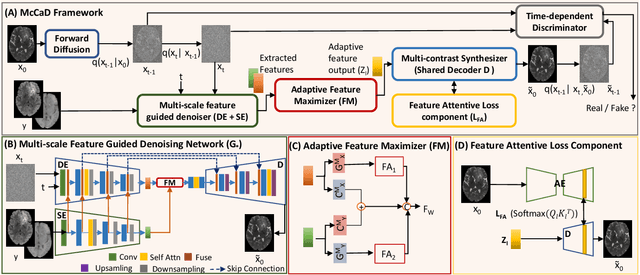



Magnetic Resonance Imaging (MRI) is instrumental in clinical diagnosis, offering diverse contrasts that provide comprehensive diagnostic information. However, acquiring multiple MRI contrasts is often constrained by high costs, long scanning durations, and patient discomfort. Current synthesis methods, typically focused on single-image contrasts, fall short in capturing the collective nuances across various contrasts. Moreover, existing methods for multi-contrast MRI synthesis often fail to accurately map feature-level information across multiple imaging contrasts. We introduce McCaD (Multi-Contrast MRI Conditioned Adaptive Adversarial Diffusion), a novel framework leveraging an adversarial diffusion model conditioned on multiple contrasts for high-fidelity MRI synthesis. McCaD significantly enhances synthesis accuracy by employing a multi-scale, feature-guided mechanism, incorporating denoising and semantic encoders. An adaptive feature maximization strategy and a spatial feature-attentive loss have been introduced to capture more intrinsic features across multiple contrasts. This facilitates a precise and comprehensive feature-guided denoising process. Extensive experiments on tumor and healthy multi-contrast MRI datasets demonstrated that the McCaD outperforms state-of-the-art baselines quantitively and qualitatively. The code is provided with supplementary materials.