 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEviATTA: Evidential Active Test-Time Adaptation for Medical Segment Anything Models
Mar 15, 2026Deploying foundational medical Segment Anything Models (SAMs) via test-time adaptation (TTA) is challenging under large distribution shifts, where test-time supervision is often unreliable. While active test-time adaptation (ATTA) introduces limited expert feedback to improve reliability, existing ATTA methods still suffer from unreliable uncertainty estimation and inefficient utilization of sparse annotations. To address these issues, we propose Evidential Active Test-Time Adaptation (EviATTA), which is, to our knowledge, the first ATTA framework tailored for medical SAMs. Specifically, we adopt the Dirichlet-based Evidential Modeling to decompose overall predictive uncertainty into distribution uncertainty and data uncertainty. Building on this decomposition, we design a Hierarchical Evidential Sampling strategy, where image-wise distribution uncertainty is used to select informative shifted samples, while distance-aware data uncertainty guides sparse pixel annotations to resolve data ambiguities. We further introduce Dual Consistency Regularization, which enforces progressive prompt consistency on sparsely labeled samples to better exploit sparse supervision and applies variational feature consistency on unlabeled samples to stabilize adaptation. Extensive experiments on six medical image segmentation datasets demonstrate that EviATTA consistently improves adaptation reliability with minimal expert feedback under both batch-wise and instance-wise test-time adaptation settings.
SAM-aware Test-time Adaptation for Universal Medical Image Segmentation
Jun 05, 2025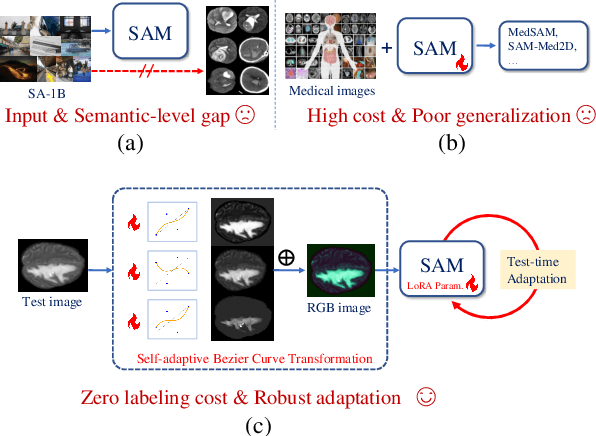
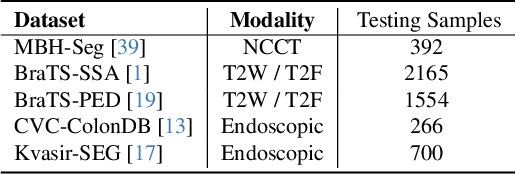
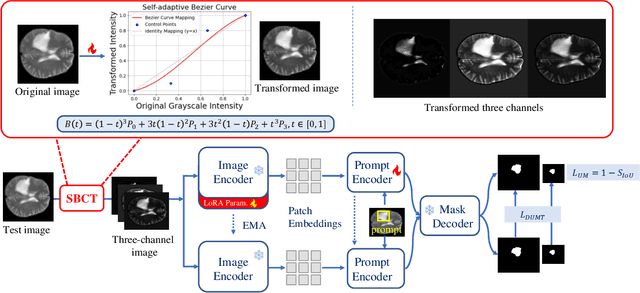
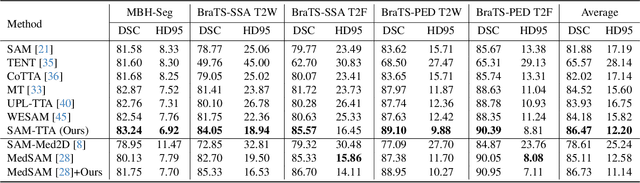
Universal medical image segmentation using the Segment Anything Model (SAM) remains challenging due to its limited adaptability to medical domains. Existing adaptations, such as MedSAM, enhance SAM's performance in medical imaging but at the cost of reduced generalization to unseen data. Therefore, in this paper, we propose SAM-aware Test-Time Adaptation (SAM-TTA), a fundamentally different pipeline that preserves the generalization of SAM while improving its segmentation performance in medical imaging via a test-time framework. SAM-TTA tackles two key challenges: (1) input-level discrepancies caused by differences in image acquisition between natural and medical images and (2) semantic-level discrepancies due to fundamental differences in object definition between natural and medical domains (e.g., clear boundaries vs. ambiguous structures). Specifically, our SAM-TTA framework comprises (1) Self-adaptive Bezier Curve-based Transformation (SBCT), which adaptively converts single-channel medical images into three-channel SAM-compatible inputs while maintaining structural integrity, to mitigate the input gap between medical and natural images, and (2) Dual-scale Uncertainty-driven Mean Teacher adaptation (DUMT), which employs consistency learning to align SAM's internal representations to medical semantics, enabling efficient adaptation without auxiliary supervision or expensive retraining. Extensive experiments on five public datasets demonstrate that our SAM-TTA outperforms existing TTA approaches and even surpasses fully fine-tuned models such as MedSAM in certain scenarios, establishing a new paradigm for universal medical image segmentation. Code can be found at https://github.com/JianghaoWu/SAM-TTA.
A Physics-based Generative Model to Synthesize Training Datasets for MRI-based Fat Quantification
Dec 11, 2024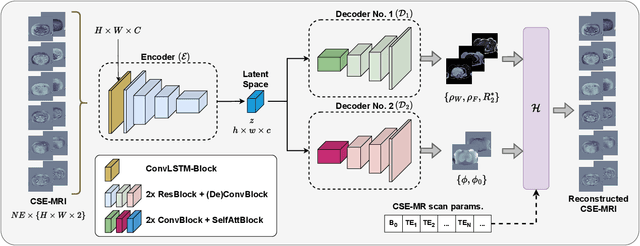
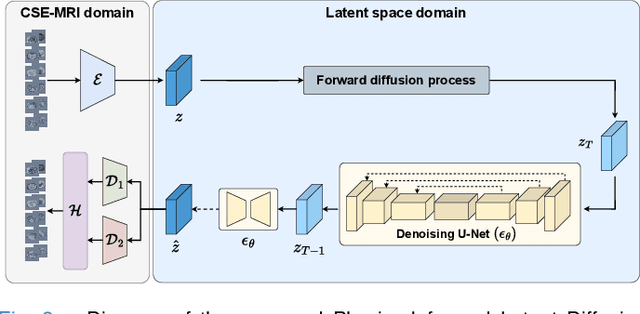
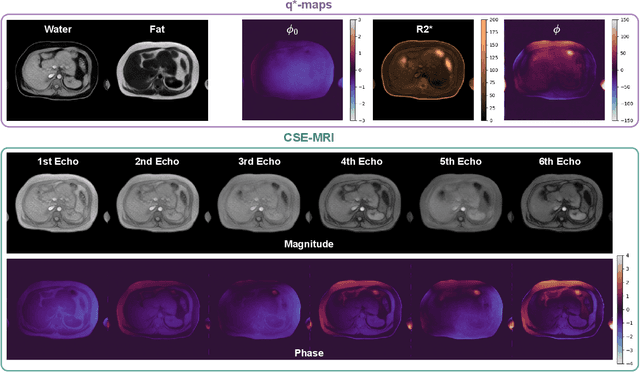
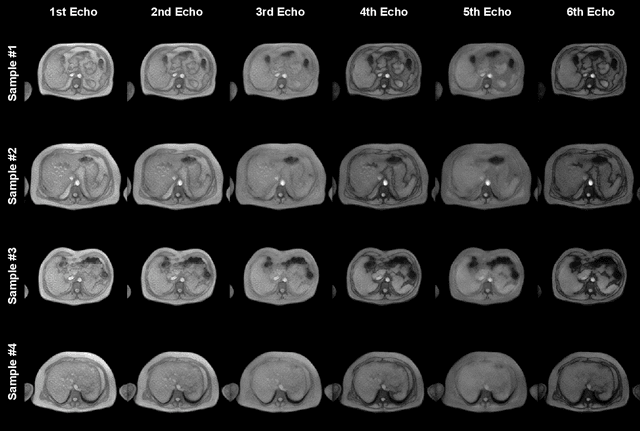
Deep learning-based techniques have potential to optimize scan and post-processing times required for MRI-based fat quantification, but they are constrained by the lack of large training datasets. Generative models are a promising tool to perform data augmentation by synthesizing realistic datasets. However no previous methods have been specifically designed to generate datasets for quantitative MRI (q-MRI) tasks, where reference quantitative maps and large variability in scanning protocols are usually required. We propose a Physics-Informed Latent Diffusion Model (PI-LDM) to synthesize quantitative parameter maps jointly with customizable MR images by incorporating the signal generation model. We assessed the quality of PI-LDM's synthesized data using metrics such as the Fr\'echet Inception Distance (FID), obtaining comparable scores to state-of-the-art generative methods (FID: 0.0459). We also trained a U-Net for the MRI-based fat quantification task incorporating synthetic datasets. When we used a few real (10 subjects, $~200$ slices) and numerous synthetic samples ($>3000$), fat fraction at specific liver ROIs showed a low bias on data obtained using the same protocol than training data ($0.10\%$ at $\hbox{ROI}_1$, $0.12\%$ at $\hbox{ROI}_2$) and on data acquired with an alternative protocol ($0.14\%$ at $\hbox{ROI}_1$, $0.62\%$ at $\hbox{ROI}_2$). Future work will be to extend PI-LDM to other q-MRI applications.
Deep kernel representations of latent space features for low-dose PET-MR imaging robust to variable dose reduction
Sep 10, 2024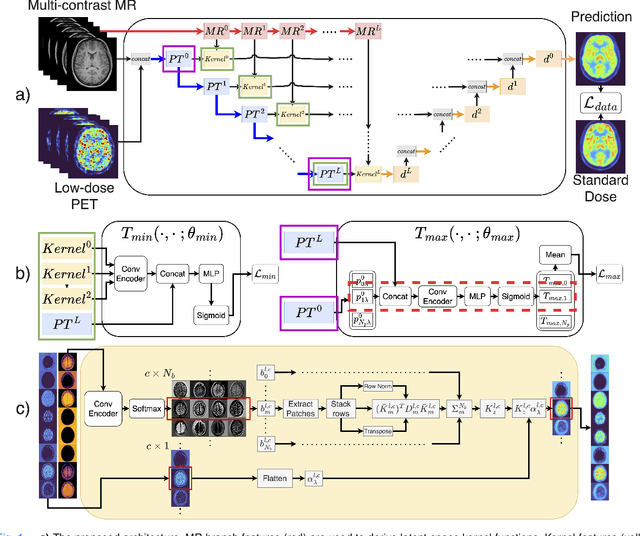
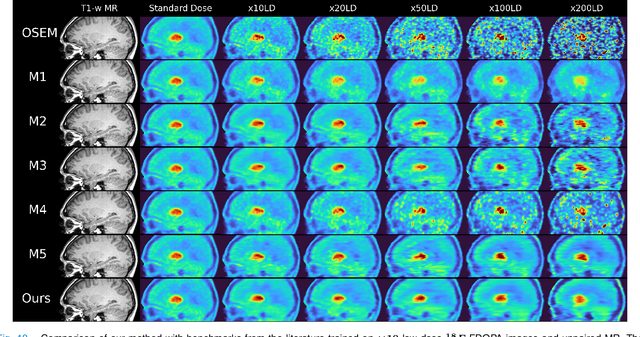
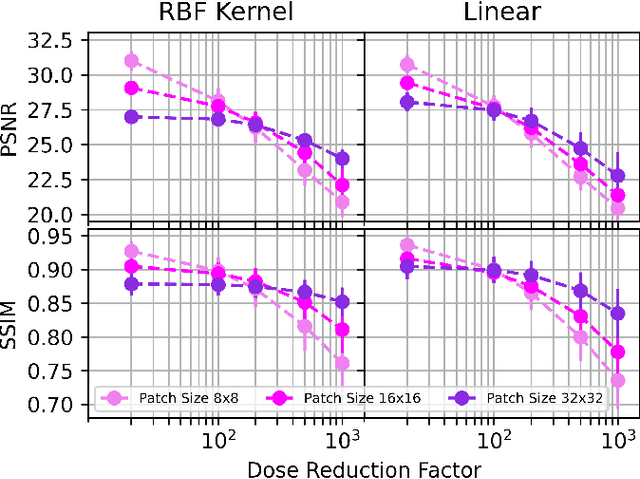
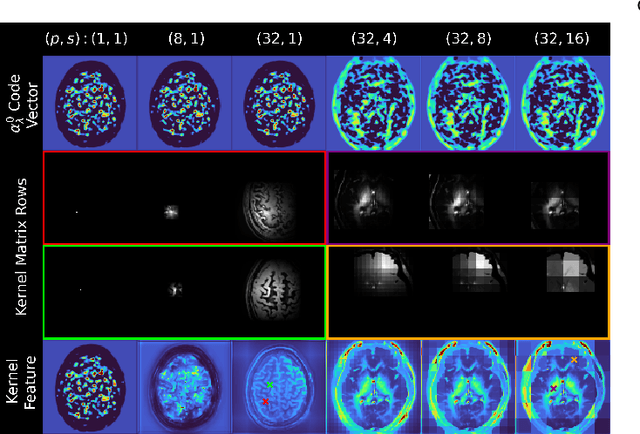
Low-dose positron emission tomography (PET) image reconstruction methods have potential to significantly improve PET as an imaging modality. Deep learning provides a promising means of incorporating prior information into the image reconstruction problem to produce quantitatively accurate images from compromised signal. Deep learning-based methods for low-dose PET are generally poorly conditioned and perform unreliably on images with features not present in the training distribution. We present a method which explicitly models deep latent space features using a robust kernel representation, providing robust performance on previously unseen dose reduction factors. Additional constraints on the information content of deep latent features allow for tuning in-distribution accuracy and generalisability. Tests with out-of-distribution dose reduction factors ranging from $\times 10$ to $\times 1000$ and with both paired and unpaired MR, demonstrate significantly improved performance relative to conventional deep-learning methods trained using the same data. Code:https://github.com/cameronPain
The KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023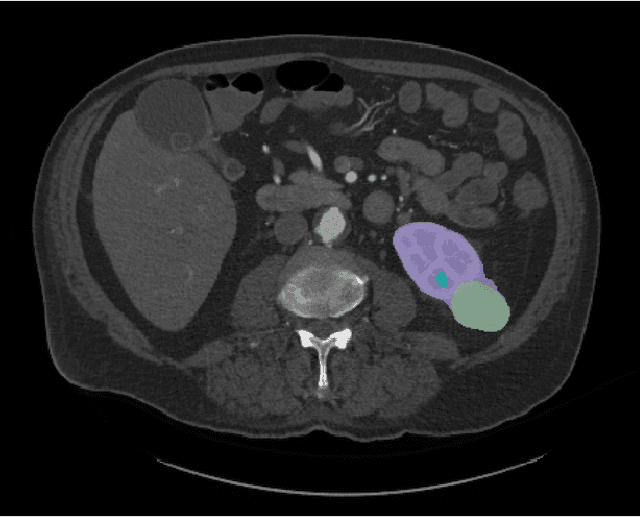
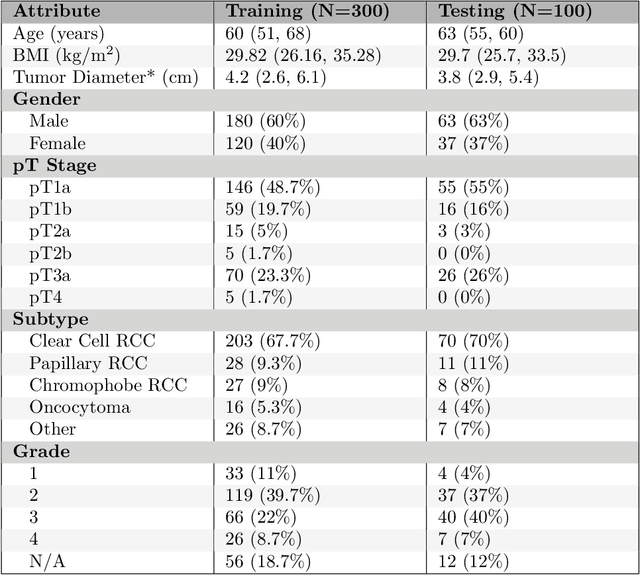
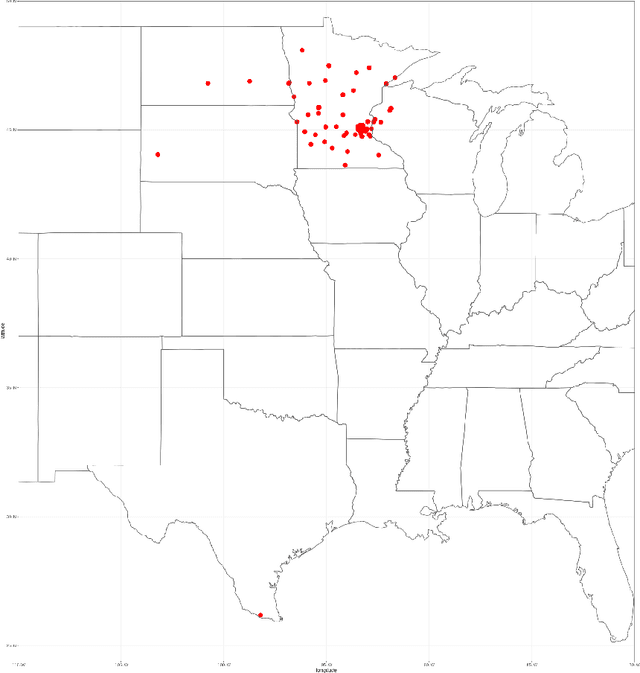
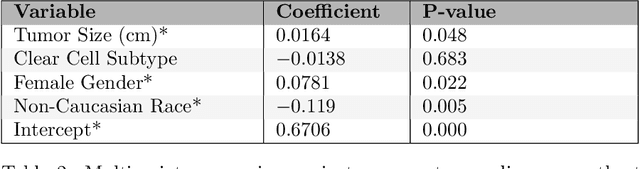
This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.
Real-time Spatio-temporal Event Detection on Geotagged Social Media
Jun 23, 2021
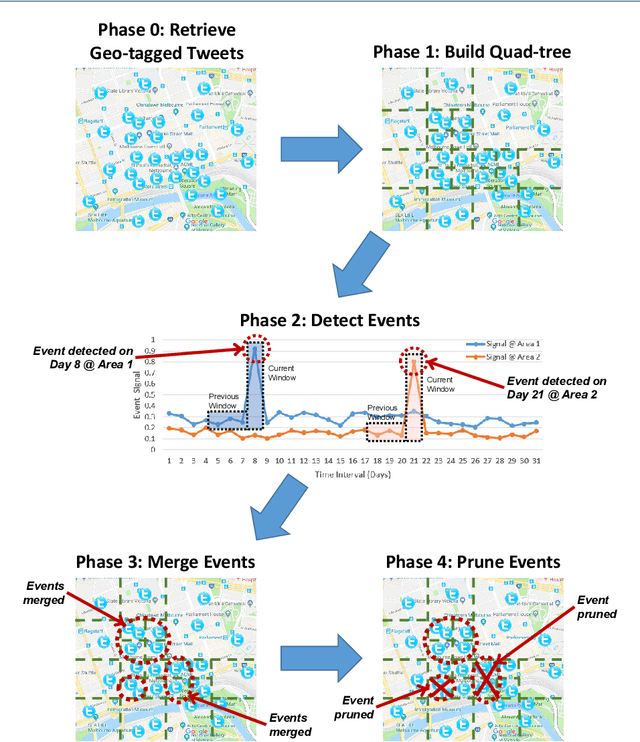


A key challenge in mining social media data streams is to identify events which are actively discussed by a group of people in a specific local or global area. Such events are useful for early warning for accident, protest, election or breaking news. However, neither the list of events nor the resolution of both event time and space is fixed or known beforehand. In this work, we propose an online spatio-temporal event detection system using social media that is able to detect events at different time and space resolutions. First, to address the challenge related to the unknown spatial resolution of events, a quad-tree method is exploited in order to split the geographical space into multiscale regions based on the density of social media data. Then, a statistical unsupervised approach is performed that involves Poisson distribution and a smoothing method for highlighting regions with unexpected density of social posts. Further, event duration is precisely estimated by merging events happening in the same region at consecutive time intervals. A post processing stage is introduced to filter out events that are spam, fake or wrong. Finally, we incorporate simple semantics by using social media entities to assess the integrity, and accuracy of detected events. The proposed method is evaluated using different social media datasets: Twitter and Flickr for different cities: Melbourne, London, Paris and New York. To verify the effectiveness of the proposed method, we compare our results with two baseline algorithms based on fixed split of geographical space and clustering method. For performance evaluation, we manually compute recall and precision. We also propose a new quality measure named strength index, which automatically measures how accurate the reported event is.