 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMMAL -- Molecular Aligned Multi-Modal Architecture and Language
Oct 28, 2024Drug discovery typically consists of multiple steps, including identifying a target protein key to a disease's etiology, validating that interacting with this target could prevent symptoms or cure the disease, discovering a small molecule or biologic therapeutic to interact with it, and optimizing the candidate molecule through a complex landscape of required properties. Drug discovery related tasks often involve prediction and generation while considering multiple entities that potentially interact, which poses a challenge for typical AI models. For this purpose we present MAMMAL - Molecular Aligned Multi-Modal Architecture and Language - a method that we applied to create a versatile multi-task foundation model ibm/biomed.omics.bl.sm.ma-ted-458m that learns from large-scale biological datasets (2 billion samples) across diverse modalities, including proteins, small molecules, and genes. We introduce a prompt syntax that supports a wide range of classification, regression, and generation tasks. It allows combining different modalities and entity types as inputs and/or outputs. Our model handles combinations of tokens and scalars and enables the generation of small molecules and proteins, property prediction, and transcriptomic lab test predictions. We evaluated the model on 11 diverse downstream tasks spanning different steps within a typical drug discovery pipeline, where it reaches new SOTA in 9 tasks and is comparable to SOTA in 2 tasks. This performance is achieved while using a unified architecture serving all tasks, in contrast to the original SOTA performance achieved using tailored architectures. The model code and pretrained weights are publicly available at https://github.com/BiomedSciAI/biomed-multi-alignment and https://huggingface.co/ibm/biomed.omics.bl.sm.ma-ted-458m.
A large dataset curation and benchmark for drug target interaction
Jan 30, 2024Bioactivity data plays a key role in drug discovery and repurposing. The resource-demanding nature of \textit{in vitro} and \textit{in vivo} experiments, as well as the recent advances in data-driven computational biochemistry research, highlight the importance of \textit{in silico} drug target interaction (DTI) prediction approaches. While numerous large public bioactivity data sources exist, research in the field could benefit from better standardization of existing data resources. At present, different research works that share similar goals are often difficult to compare properly because of different choices of data sources and train/validation/test split strategies. Additionally, many works are based on small data subsets, leading to results and insights of possible limited validity. In this paper we propose a way to standardize and represent efficiently a very large dataset curated from multiple public sources, split the data into train, validation and test sets based on different meaningful strategies, and provide a concrete evaluation protocol to accomplish a benchmark. We analyze the proposed data curation, prove its usefulness and validate the proposed benchmark through experimental studies based on an existing neural network model.
The KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023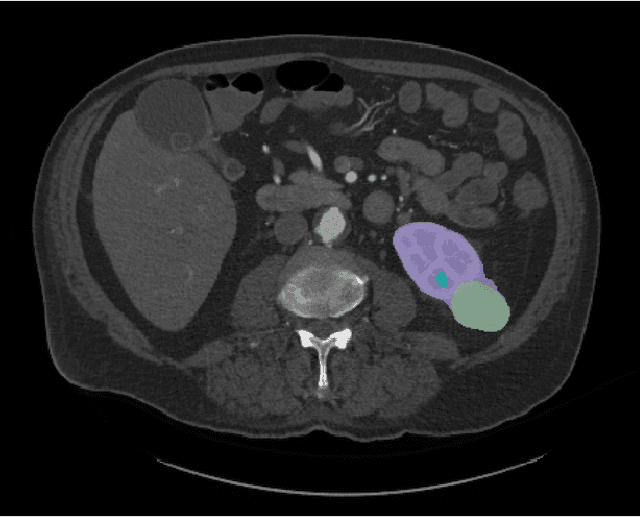
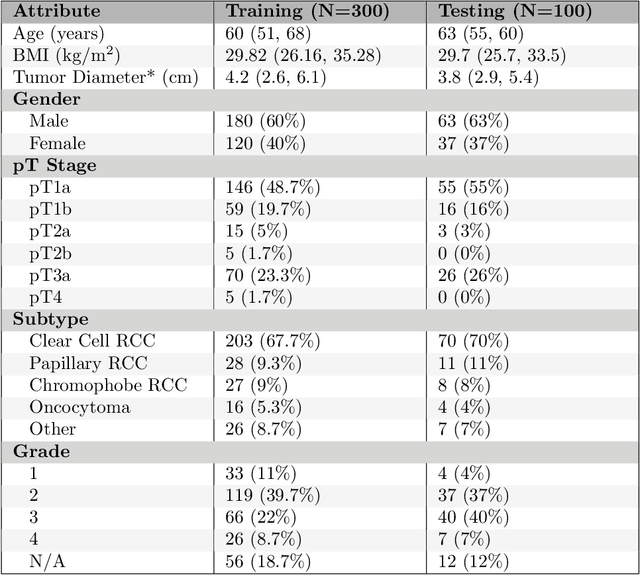
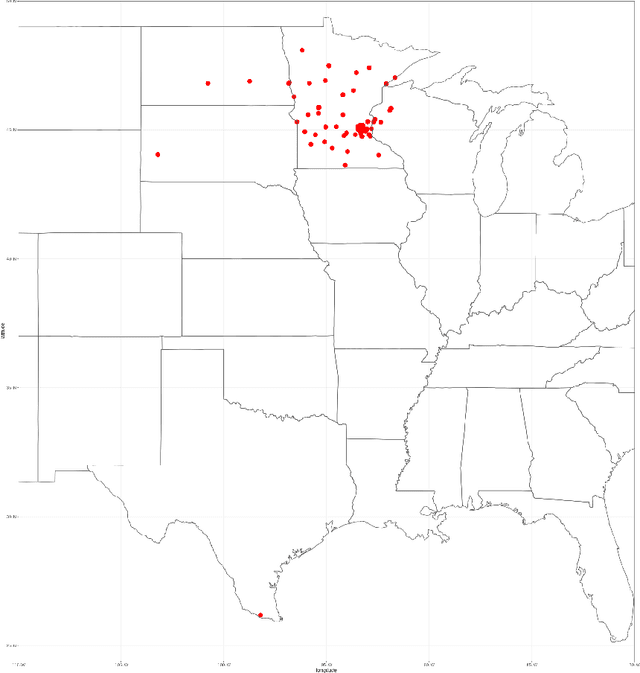
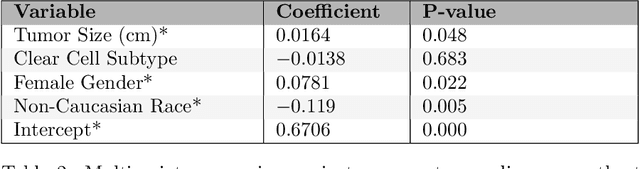
This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.
Image compression optimized for 3D reconstruction by utilizing deep neural networks
Mar 27, 2020



Computer vision tasks are often expected to be executed on compressed images. Classical image compression standards like JPEG 2000 are widely used. However, they do not account for the specific end-task at hand. Motivated by works on recurrent neural network (RNN)-based image compression and three-dimensional (3D) reconstruction, we propose unified network architectures to solve both tasks jointly. These joint models provide image compression tailored for the specific task of 3D reconstruction. Images compressed by our proposed models, yield 3D reconstruction performance superior as compared to using JPEG 2000 compression. Our models significantly extend the range of compression rates for which 3D reconstruction is possible. We also show that this can be done highly efficiently at almost no additional cost to obtain compression on top of the computation already required for performing the 3D reconstruction task.