 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023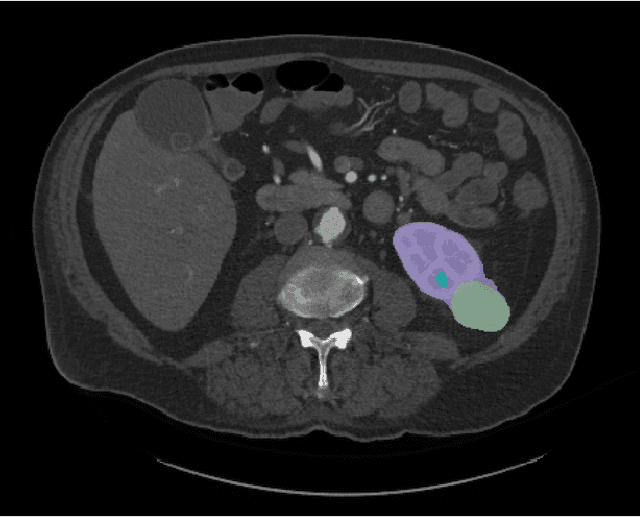
This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.
AdapterNet - learning input transformation for domain adaptation
May 29, 2018

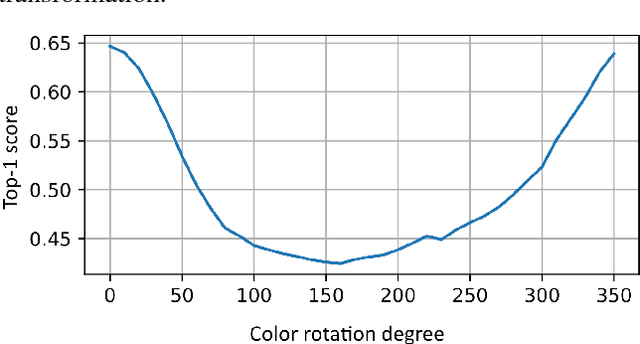

Deep neural networks have demonstrated impressive performance in various machine learning tasks. However, they are notoriously sensitive to changes in data distribution. Often, even a slight change in the distribution can lead to drastic performance reduction. Artificially augmenting the data may help to some extent, but in most cases, fails to achieve model invariance to the data distribution. Some examples where this sub-class of domain adaptation can be valuable are various imaging modalities such as thermal imaging, X-ray, ultrasound, and MRI, where changes in acquisition parameters or acquisition device manufacturer will result in different representation of the same input. Our work shows that standard finetuning fails to adapt the model in certain important cases. We propose a novel method of adapting to a new data source, and demonstrate near perfect adaptation on a customized ImageNet benchmark.