 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegRap2025: A Benchmark of Gross Tumor Volume and Lymph Node Clinical Target Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Jan 28, 2026Accurate delineation of Gross Tumor Volume (GTV), Lymph Node Clinical Target Volume (LN CTV), and Organ-at-Risk (OAR) from Computed Tomography (CT) scans is essential for precise radiotherapy planning in Nasopharyngeal Carcinoma (NPC). Building upon SegRap2023, which focused on OAR and GTV segmentation using single-center paired non-contrast CT (ncCT) and contrast-enhanced CT (ceCT) scans, the SegRap2025 challenge aims to enhance the generalizability and robustness of segmentation models across imaging centers and modalities. SegRap2025 comprises two tasks: Task01 addresses GTV segmentation using paired CT from the SegRap2023 dataset, with an additional external testing set to evaluate cross-center generalization, and Task02 focuses on LN CTV segmentation using multi-center training data and an unseen external testing set, where each case contains paired CT scans or a single modality, emphasizing both cross-center and cross-modality robustness. This paper presents the challenge setup and provides a comprehensive analysis of the solutions submitted by ten participating teams. For GTV segmentation task, the top-performing models achieved average Dice Similarity Coefficient (DSC) of 74.61% and 56.79% on the internal and external testing cohorts, respectively. For LN CTV segmentation task, the highest average DSC values reached 60.24%, 60.50%, and 57.23% on paired CT, ceCT-only, and ncCT-only subsets, respectively. SegRap2025 establishes a large-scale multi-center, multi-modality benchmark for evaluating the generalization and robustness in radiotherapy target segmentation, providing valuable insights toward clinically applicable automated radiotherapy planning systems. The benchmark is available at: https://hilab-git.github.io/SegRap2025_Challenge.
PAINT: Pathology-Aware Integrated Next-Scale Transformation for Virtual Immunohistochemistry
Jan 22, 2026Virtual immunohistochemistry (IHC) aims to computationally synthesize molecular staining patterns from routine Hematoxylin and Eosin (H\&E) images, offering a cost-effective and tissue-efficient alternative to traditional physical staining. However, this task is particularly challenging: H\&E morphology provides ambiguous cues about protein expression, and similar tissue structures may correspond to distinct molecular states. Most existing methods focus on direct appearance synthesis to implicitly achieve cross-modal generation, often resulting in semantic inconsistencies due to insufficient structural priors. In this paper, we propose Pathology-Aware Integrated Next-Scale Transformation (PAINT), a visual autoregressive framework that reformulates the synthesis process as a structure-first conditional generation task. Unlike direct image translation, PAINT enforces a causal order by resolving molecular details conditioned on a global structural layout. Central to this approach is the introduction of a Spatial Structural Start Map (3S-Map), which grounds the autoregressive initialization in observed morphology, ensuring deterministic, spatially aligned synthesis. Experiments on the IHC4BC and MIST datasets demonstrate that PAINT outperforms state-of-the-art methods in structural fidelity and clinical downstream tasks, validating the potential of structure-guided autoregressive modeling.
SAM-aware Test-time Adaptation for Universal Medical Image Segmentation
Jun 05, 2025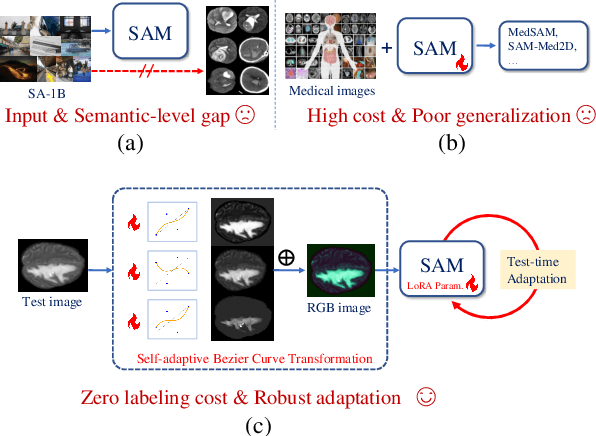
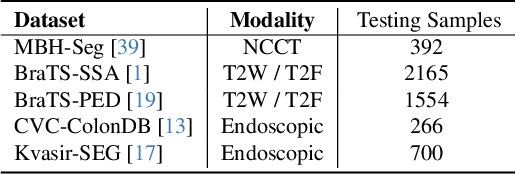
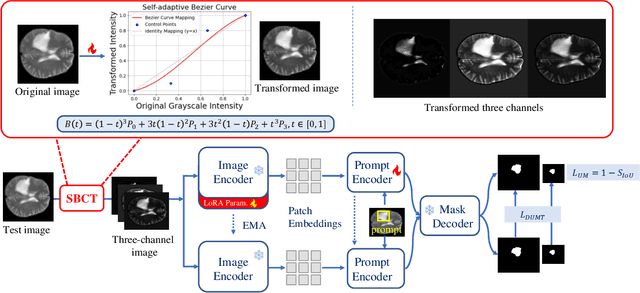
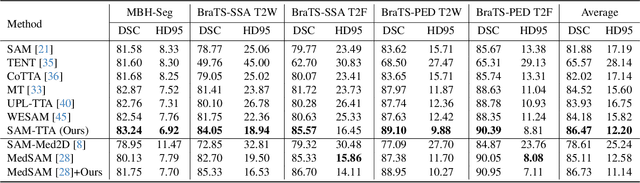
Universal medical image segmentation using the Segment Anything Model (SAM) remains challenging due to its limited adaptability to medical domains. Existing adaptations, such as MedSAM, enhance SAM's performance in medical imaging but at the cost of reduced generalization to unseen data. Therefore, in this paper, we propose SAM-aware Test-Time Adaptation (SAM-TTA), a fundamentally different pipeline that preserves the generalization of SAM while improving its segmentation performance in medical imaging via a test-time framework. SAM-TTA tackles two key challenges: (1) input-level discrepancies caused by differences in image acquisition between natural and medical images and (2) semantic-level discrepancies due to fundamental differences in object definition between natural and medical domains (e.g., clear boundaries vs. ambiguous structures). Specifically, our SAM-TTA framework comprises (1) Self-adaptive Bezier Curve-based Transformation (SBCT), which adaptively converts single-channel medical images into three-channel SAM-compatible inputs while maintaining structural integrity, to mitigate the input gap between medical and natural images, and (2) Dual-scale Uncertainty-driven Mean Teacher adaptation (DUMT), which employs consistency learning to align SAM's internal representations to medical semantics, enabling efficient adaptation without auxiliary supervision or expensive retraining. Extensive experiments on five public datasets demonstrate that our SAM-TTA outperforms existing TTA approaches and even surpasses fully fine-tuned models such as MedSAM in certain scenarios, establishing a new paradigm for universal medical image segmentation. Code can be found at https://github.com/JianghaoWu/SAM-TTA.
CodeBrain: Impute Any Brain MRI via Instance-specific Scalar-quantized Codes
Jan 30, 2025MRI imputation aims to synthesize the missing modality from one or more available ones, which is highly desirable since it reduces scanning costs and delivers comprehensive MRI information to enhance clinical diagnosis. In this paper, we propose a unified model, CodeBrain, designed to adapt to various brain MRI imputation scenarios. The core design lies in casting various inter-modality transformations as a full-modality code prediction task. To this end, CodeBrain is trained in two stages: Reconstruction and Code Prediction. First, in the Reconstruction stage, we reconstruct each MRI modality, which is mapped into a shared latent space followed by a scalar quantization. Since such quantization is lossy and the code is low dimensional, another MRI modality belonging to the same subject is randomly selected to generate common features to supplement the code and boost the target reconstruction. In the second stage, we train another encoder by a customized grading loss to predict the full-modality codes from randomly masked MRI samples, supervised by the corresponding quantized codes generated from the first stage. In this way, the inter-modality transformation is achieved by mapping the instance-specific codes in a finite scalar space. We evaluated the proposed CodeBrain model on two public brain MRI datasets (i.e., IXI and BraTS 2023). Extensive experiments demonstrate that our CodeBrain model achieves superior imputation performance compared to four existing methods, establishing a new state of the art for unified brain MRI imputation. Codes will be released.
Cycle-Consistent Bridge Diffusion Model for Accelerated MRI Reconstruction
Dec 13, 2024



Accelerated MRI reconstruction techniques aim to reduce examination time while maintaining high image fidelity, which is highly desirable in clinical settings for improving patient comfort and hospital efficiency. Existing deep learning methods typically reconstruct images from under-sampled data with traditional reconstruction approaches, but they still struggle to provide high-fidelity results. Diffusion models show great potential to improve fidelity of generated images in recent years. However, their inference process starting with a random Gaussian noise introduces instability into the results and usually requires thousands of sampling steps, resulting in sub-optimal reconstruction quality and low efficiency. To address these challenges, we propose Cycle-Consistent Bridge Diffusion Model (CBDM). CBDM employs two bridge diffusion models to construct a cycle-consistent diffusion process with a consistency loss, enhancing the fine-grained details of reconstructed images and reducing the number of diffusion steps. Moreover, CBDM incorporates a Contourlet Decomposition Embedding Module (CDEM) which captures multi-scale structural texture knowledge in images through frequency domain decomposition pyramids and directional filter banks to improve structural fidelity. Extensive experiments demonstrate the superiority of our model by higher reconstruction quality and fewer training iterations, achieving a new state of the art for accelerated MRI reconstruction in both fastMRI and IXI datasets.
Cross Group Attention and Group-wise Rolling for Multimodal Medical Image Synthesis
Nov 22, 2024Multimodal MR image synthesis aims to generate missing modality image by fusing and mapping a few available MRI data. Most existing approaches typically adopt an image-to-image translation scheme. However, these methods often suffer from sub-optimal performance due to the spatial misalignment between different modalities while they are typically treated as input channels. Therefore, in this paper, we propose an Adaptive Group-wise Interaction Network (AGI-Net) that explores both inter-modality and intra-modality relationships for multimodal MR image synthesis. Specifically, groups are first pre-defined along the channel dimension and then we perform an adaptive rolling for the standard convolutional kernel to capture inter-modality spatial correspondences. At the same time, a cross-group attention module is introduced to fuse information across different channel groups, leading to better feature representation. We evaluated the effectiveness of our model on the publicly available IXI and BraTS2023 datasets, where the AGI-Net achieved state-of-the-art performance for multimodal MR image synthesis. Code will be released.
Diversified and Personalized Multi-rater Medical Image Segmentation
Mar 20, 2024Annotation ambiguity due to inherent data uncertainties such as blurred boundaries in medical scans and different observer expertise and preferences has become a major obstacle for training deep-learning based medical image segmentation models. To address it, the common practice is to gather multiple annotations from different experts, leading to the setting of multi-rater medical image segmentation. Existing works aim to either merge different annotations into the "groundtruth" that is often unattainable in numerous medical contexts, or generate diverse results, or produce personalized results corresponding to individual expert raters. Here, we bring up a more ambitious goal for multi-rater medical image segmentation, i.e., obtaining both diversified and personalized results. Specifically, we propose a two-stage framework named D-Persona (first Diversification and then Personalization). In Stage I, we exploit multiple given annotations to train a Probabilistic U-Net model, with a bound-constrained loss to improve the prediction diversity. In this way, a common latent space is constructed in Stage I, where different latent codes denote diversified expert opinions. Then, in Stage II, we design multiple attention-based projection heads to adaptively query the corresponding expert prompts from the shared latent space, and then perform the personalized medical image segmentation. We evaluated the proposed model on our in-house Nasopharyngeal Carcinoma dataset and the public lung nodule dataset (i.e., LIDC-IDRI). Extensive experiments demonstrated our D-Persona can provide diversified and personalized results at the same time, achieving new SOTA performance for multi-rater medical image segmentation. Our code will be released at https://github.com/ycwu1997/D-Persona.
Segment Together: A Versatile Paradigm for Semi-Supervised Medical Image Segmentation
Nov 20, 2023



Annotation scarcity has become a major obstacle for training powerful deep-learning models for medical image segmentation, restricting their deployment in clinical scenarios. To address it, semi-supervised learning by exploiting abundant unlabeled data is highly desirable to boost the model training. However, most existing works still focus on limited medical tasks and underestimate the potential of learning across diverse tasks and multiple datasets. Therefore, in this paper, we introduce a \textbf{Ver}satile \textbf{Semi}-supervised framework (VerSemi) to point out a new perspective that integrates various tasks into a unified model with a broad label space, to exploit more unlabeled data for semi-supervised medical image segmentation. Specifically, we introduce a dynamic task-prompted design to segment various targets from different datasets. Next, this unified model is used to identify the foreground regions from all labeled data, to capture cross-dataset semantics. Particularly, we create a synthetic task with a cutmix strategy to augment foreground targets within the expanded label space. To effectively utilize unlabeled data, we introduce a consistency constraint. This involves aligning aggregated predictions from various tasks with those from the synthetic task, further guiding the model in accurately segmenting foreground regions during training. We evaluated our VerSemi model on four public benchmarking datasets. Extensive experiments demonstrated that VerSemi can consistently outperform the second-best method by a large margin (e.g., an average 2.69\% Dice gain on four datasets), setting new SOTA performance for semi-supervised medical image segmentation. The code will be released.
CoactSeg: Learning from Heterogeneous Data for New Multiple Sclerosis Lesion Segmentation
Jul 10, 2023

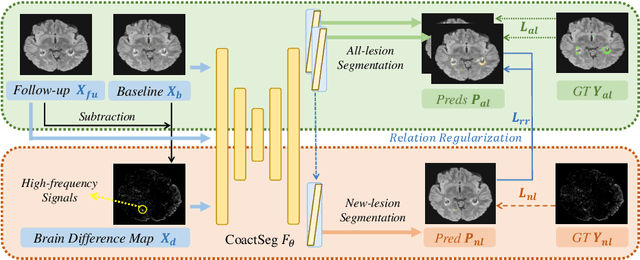
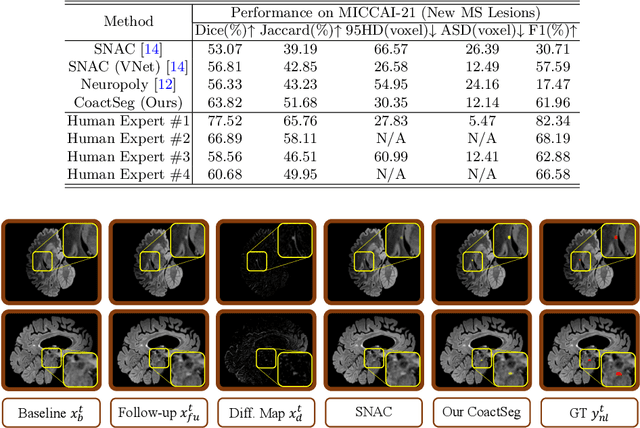
New lesion segmentation is essential to estimate the disease progression and therapeutic effects during multiple sclerosis (MS) clinical treatments. However, the expensive data acquisition and expert annotation restrict the feasibility of applying large-scale deep learning models. Since single-time-point samples with all-lesion labels are relatively easy to collect, exploiting them to train deep models is highly desirable to improve new lesion segmentation. Therefore, we proposed a coaction segmentation (CoactSeg) framework to exploit the heterogeneous data (i.e., new-lesion annotated two-time-point data and all-lesion annotated single-time-point data) for new MS lesion segmentation. The CoactSeg model is designed as a unified model, with the same three inputs (the baseline, follow-up, and their longitudinal brain differences) and the same three outputs (the corresponding all-lesion and new-lesion predictions), no matter which type of heterogeneous data is being used. Moreover, a simple and effective relation regularization is proposed to ensure the longitudinal relations among the three outputs to improve the model learning. Extensive experiments demonstrate that utilizing the heterogeneous data and the proposed longitudinal relation constraint can significantly improve the performance for both new-lesion and all-lesion segmentation tasks. Meanwhile, we also introduce an in-house MS-23v1 dataset, including 38 Oceania single-time-point samples with all-lesion labels. Codes and the dataset are released at https://github.com/ycwu1997/CoactSeg.
Towards Open-Scenario Semi-supervised Medical Image Classification
Apr 08, 2023



Semi-supervised learning (SSL) has attracted much attention since it reduces the expensive costs of collecting adequate well-labeled training data, especially for deep learning methods. However, traditional SSL is built upon an assumption that labeled and unlabeled data should be from the same distribution e.g., classes and domains. However, in practical scenarios, unlabeled data would be from unseen classes or unseen domains, and it is still challenging to exploit them by existing SSL methods. Therefore, in this paper, we proposed a unified framework to leverage these unseen unlabeled data for open-scenario semi-supervised medical image classification. We first design a novel scoring mechanism, called dual-path outliers estimation, to identify samples from unseen classes. Meanwhile, to extract unseen-domain samples, we then apply an effective variational autoencoder (VAE) pre-training. After that, we conduct domain adaptation to fully exploit the value of the detected unseen-domain samples to boost semi-supervised training. We evaluated our proposed framework on dermatology and ophthalmology tasks. Extensive experiments demonstrate our model can achieve superior classification performance in various medical SSL scenarios.