 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegQIR: Generative Quanta Image Reconstruction
Feb 23, 2026Capturing high-quality images from only a few detected photons is a fundamental challenge in computational imaging. Single-photon avalanche diode (SPAD) sensors promise high-quality imaging in regimes where conventional cameras fail, but raw \emph{quanta frames} contain only sparse, noisy, binary photon detections. Recovering a coherent image from a burst of such frames requires handling alignment, denoising, and demosaicing (for color) under noise statistics far outside those assumed by standard restoration pipelines or modern generative models. We present an approach that adapts large text-to-image latent diffusion models to the photon-limited domain of quanta burst imaging. Our method leverages the structural and semantic priors of internet-scale diffusion models while introducing mechanisms to handle Bernoulli photon statistics. By integrating latent-space restoration with burst-level spatio-temporal reasoning, our approach produces reconstructions that are both photometrically faithful and perceptually pleasing, even under high-speed motion. We evaluate the method on synthetic benchmarks and new real-world datasets, including the first color SPAD burst dataset and a challenging \textit{Deforming (XD)} video benchmark. Across all settings, the approach substantially improves perceptual quality over classical and modern learning-based baselines, demonstrating the promise of adapting large generative priors to extreme photon-limited sensing. Code at \href{https://github.com/Aryan-Garg/gQIR}{https://github.com/Aryan-Garg/gQIR}.
DiffVQA: Video Quality Assessment Using Diffusion Feature Extractor
May 06, 2025Video Quality Assessment (VQA) aims to evaluate video quality based on perceptual distortions and human preferences. Despite the promising performance of existing methods using Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), they often struggle to align closely with human perceptions, particularly in diverse real-world scenarios. This challenge is exacerbated by the limited scale and diversity of available datasets. To address this limitation, we introduce a novel VQA framework, DiffVQA, which harnesses the robust generalization capabilities of diffusion models pre-trained on extensive datasets. Our framework adapts these models to reconstruct identical input frames through a control module. The adapted diffusion model is then used to extract semantic and distortion features from a resizing branch and a cropping branch, respectively. To enhance the model's ability to handle long-term temporal dynamics, a parallel Mamba module is introduced, which extracts temporal coherence augmented features that are merged with the diffusion features to predict the final score. Experiments across multiple datasets demonstrate DiffVQA's superior performance on intra-dataset evaluations and its exceptional generalization across datasets. These results confirm that leveraging a diffusion model as a feature extractor can offer enhanced VQA performance compared to CNN and ViT backbones.
GuideSR: Rethinking Guidance for One-Step High-Fidelity Diffusion-Based Super-Resolution
May 01, 2025In this paper, we propose GuideSR, a novel single-step diffusion-based image super-resolution (SR) model specifically designed to enhance image fidelity. Existing diffusion-based SR approaches typically adapt pre-trained generative models to image restoration tasks by adding extra conditioning on a VAE-downsampled representation of the degraded input, which often compromises structural fidelity. GuideSR addresses this limitation by introducing a dual-branch architecture comprising: (1) a Guidance Branch that preserves high-fidelity structures from the original-resolution degraded input, and (2) a Diffusion Branch, which a pre-trained latent diffusion model to enhance perceptual quality. Unlike conventional conditioning mechanisms, our Guidance Branch features a tailored structure for image restoration tasks, combining Full Resolution Blocks (FRBs) with channel attention and an Image Guidance Network (IGN) with guided attention. By embedding detailed structural information directly into the restoration pipeline, GuideSR produces sharper and more visually consistent results. Extensive experiments on benchmark datasets demonstrate that GuideSR achieves state-of-the-art performance while maintaining the low computational cost of single-step approaches, with up to 1.39dB PSNR gain on challenging real-world datasets. Our approach consistently outperforms existing methods across various reference-based metrics including PSNR, SSIM, LPIPS, DISTS and FID, further representing a practical advancement for real-world image restoration.
Snapmoji: Instant Generation of Animatable Dual-Stylized Avatars
Mar 15, 2025



The increasing popularity of personalized avatar systems, such as Snapchat Bitmojis and Apple Memojis, highlights the growing demand for digital self-representation. Despite their widespread use, existing avatar platforms face significant limitations, including restricted expressivity due to predefined assets, tedious customization processes, or inefficient rendering requirements. Addressing these shortcomings, we introduce Snapmoji, an avatar generation system that instantly creates animatable, dual-stylized avatars from a selfie. We propose Gaussian Domain Adaptation (GDA), which is pre-trained on large-scale Gaussian models using 3D data from sources such as Objaverse and fine-tuned with 2D style transfer tasks, endowing it with a rich 3D prior. This enables Snapmoji to transform a selfie into a primary stylized avatar, like the Bitmoji style, and apply a secondary style, such as Plastic Toy or Alien, all while preserving the user's identity and the primary style's integrity. Our system is capable of producing 3D Gaussian avatars that support dynamic animation, including accurate facial expression transfer. Designed for efficiency, Snapmoji achieves selfie-to-avatar conversion in just 0.9 seconds and supports real-time interactions on mobile devices at 30 to 40 frames per second. Extensive testing confirms that Snapmoji outperforms existing methods in versatility and speed, making it a convenient tool for automatic avatar creation in various styles.
InstantRestore: Single-Step Personalized Face Restoration with Shared-Image Attention
Dec 09, 2024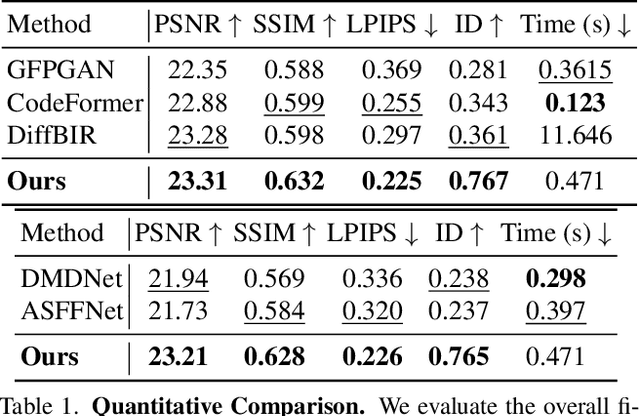
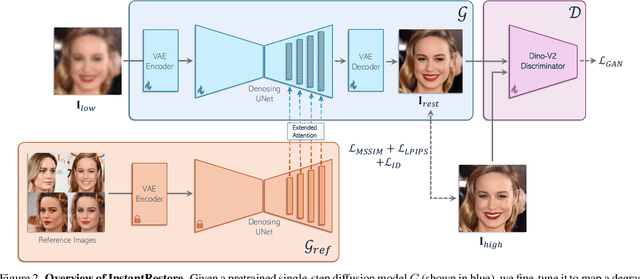
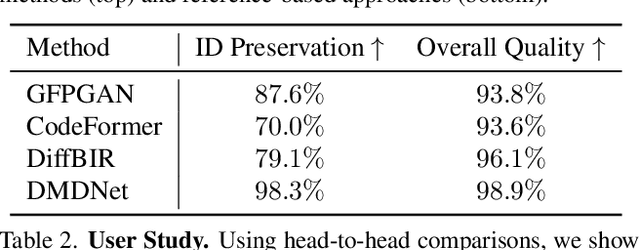
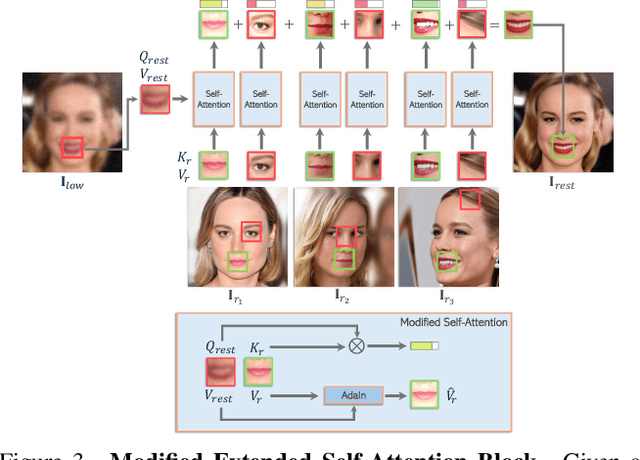
Face image restoration aims to enhance degraded facial images while addressing challenges such as diverse degradation types, real-time processing demands, and, most crucially, the preservation of identity-specific features. Existing methods often struggle with slow processing times and suboptimal restoration, especially under severe degradation, failing to accurately reconstruct finer-level identity details. To address these issues, we introduce InstantRestore, a novel framework that leverages a single-step image diffusion model and an attention-sharing mechanism for fast and personalized face restoration. Additionally, InstantRestore incorporates a novel landmark attention loss, aligning key facial landmarks to refine the attention maps, enhancing identity preservation. At inference time, given a degraded input and a small (~4) set of reference images, InstantRestore performs a single forward pass through the network to achieve near real-time performance. Unlike prior approaches that rely on full diffusion processes or per-identity model tuning, InstantRestore offers a scalable solution suitable for large-scale applications. Extensive experiments demonstrate that InstantRestore outperforms existing methods in quality and speed, making it an appealing choice for identity-preserving face restoration.
Sagiri: Low Dynamic Range Image Enhancement with Generative Diffusion Prior
Jun 13, 2024



Capturing High Dynamic Range (HDR) scenery using 8-bit cameras often suffers from over-/underexposure, loss of fine details due to low bit-depth compression, skewed color distributions, and strong noise in dark areas. Traditional LDR image enhancement methods primarily focus on color mapping, which enhances the visual representation by expanding the image's color range and adjusting the brightness. However, these approaches fail to effectively restore content in dynamic range extremes, which are regions with pixel values close to 0 or 255. To address the full scope of challenges in HDR imaging and surpass the limitations of current models, we propose a novel two-stage approach. The first stage maps the color and brightness to an appropriate range while keeping the existing details, and the second stage utilizes a diffusion prior to generate content in dynamic range extremes lost during capture. This generative refinement module can also be used as a plug-and-play module to enhance and complement existing LDR enhancement models. The proposed method markedly improves the quality and details of LDR images, demonstrating superior performance through rigorous experimental validation. The project page is at https://sagiri0208.github.io
RobustSAM: Segment Anything Robustly on Degraded Images
Jun 13, 2024Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization. Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
DSL-FIQA: Assessing Facial Image Quality via Dual-Set Degradation Learning and Landmark-Guided Transformer
Jun 13, 2024Generic Face Image Quality Assessment (GFIQA) evaluates the perceptual quality of facial images, which is crucial in improving image restoration algorithms and selecting high-quality face images for downstream tasks. We present a novel transformer-based method for GFIQA, which is aided by two unique mechanisms. First, a Dual-Set Degradation Representation Learning (DSL) mechanism uses facial images with both synthetic and real degradations to decouple degradation from content, ensuring generalizability to real-world scenarios. This self-supervised method learns degradation features on a global scale, providing a robust alternative to conventional methods that use local patch information in degradation learning. Second, our transformer leverages facial landmarks to emphasize visually salient parts of a face image in evaluating its perceptual quality. We also introduce a balanced and diverse Comprehensive Generic Face IQA (CGFIQA-40k) dataset of 40K images carefully designed to overcome the biases, in particular the imbalances in skin tone and gender representation, in existing datasets. Extensive analysis and evaluation demonstrate the robustness of our method, marking a significant improvement over prior methods.
Personalized Restoration via Dual-Pivot Tuning
Dec 28, 2023Generative diffusion models can serve as a prior which ensures that solutions of image restoration systems adhere to the manifold of natural images. However, for restoring facial images, a personalized prior is necessary to accurately represent and reconstruct unique facial features of a given individual. In this paper, we propose a simple, yet effective, method for personalized restoration, called Dual-Pivot Tuning - a two-stage approach that personalize a blind restoration system while maintaining the integrity of the general prior and the distinct role of each component. Our key observation is that for optimal personalization, the generative model should be tuned around a fixed text pivot, while the guiding network should be tuned in a generic (non-personalized) manner, using the personalized generative model as a fixed ``pivot". This approach ensures that personalization does not interfere with the restoration process, resulting in a natural appearance with high fidelity to the person's identity and the attributes of the degraded image. We evaluated our approach both qualitatively and quantitatively through extensive experiments with images of widely recognized individuals, comparing it against relevant baselines. Surprisingly, we found that our personalized prior not only achieves higher fidelity to identity with respect to the person's identity, but also outperforms state-of-the-art generic priors in terms of general image quality. Project webpage: https://personalized-restoration.github.io
Clearer Frames, Anytime: Resolving Velocity Ambiguity in Video Frame Interpolation
Nov 14, 2023



Existing video frame interpolation (VFI) methods blindly predict where each object is at a specific timestep t ("time indexing"), which struggles to predict precise object movements. Given two images of a baseball, there are infinitely many possible trajectories: accelerating or decelerating, straight or curved. This often results in blurry frames as the method averages out these possibilities. Instead of forcing the network to learn this complicated time-to-location mapping implicitly together with predicting the frames, we provide the network with an explicit hint on how far the object has traveled between start and end frames, a novel approach termed "distance indexing". This method offers a clearer learning goal for models, reducing the uncertainty tied to object speeds. We further observed that, even with this extra guidance, objects can still be blurry especially when they are equally far from both input frames (i.e., halfway in-between), due to the directional ambiguity in long-range motion. To solve this, we propose an iterative reference-based estimation strategy that breaks down a long-range prediction into several short-range steps. When integrating our plug-and-play strategies into state-of-the-art learning-based models, they exhibit markedly sharper outputs and superior perceptual quality in arbitrary time interpolations, using a uniform distance indexing map in the same format as time indexing. Additionally, distance indexing can be specified pixel-wise, which enables temporal manipulation of each object independently, offering a novel tool for video editing tasks like re-timing.