 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpgrade or Switch: Do We Need a New Registry Architecture for the Internet of AI Agents?
Jun 13, 2025The emerging Internet of AI Agents challenges existing web infrastructure designed for human-scale, reactive interactions. Unlike traditional web resources, autonomous AI agents initiate actions, maintain persistent state, spawn sub-agents, and negotiate directly with peers: demanding millisecond-level discovery, instant credential revocation, and cryptographic behavioral proofs that exceed current DNS/PKI capabilities. This paper analyzes whether to upgrade existing infrastructure or implement purpose-built registry architectures for autonomous agents. We identify critical failure points: DNS propagation (24-48 hours vs. required milliseconds), certificate revocation unable to scale to trillions of entities, and IPv4/IPv6 addressing inadequate for agent-scale routing. We evaluate three approaches: (1) Upgrade paths, (2) Switch options, (3) Hybrid registries. Drawing parallels to dialup-to-broadband transitions, we find that agent requirements constitute qualitative, and not incremental, changes. While upgrades offer compatibility and faster deployment, clean-slate solutions provide better performance but require longer for adoption. Our analysis suggests hybrid approaches will emerge, with centralized registries for critical agents and federated meshes for specialized use cases.
Collaborative Agentic AI Needs Interoperability Across Ecosystems
May 25, 2025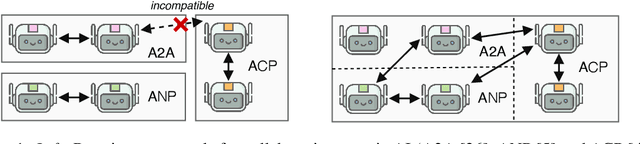
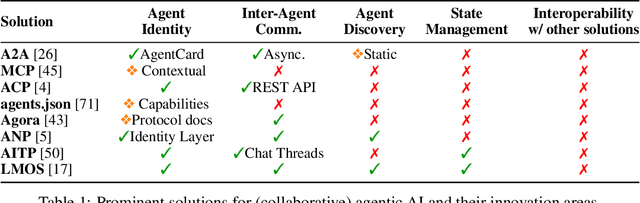
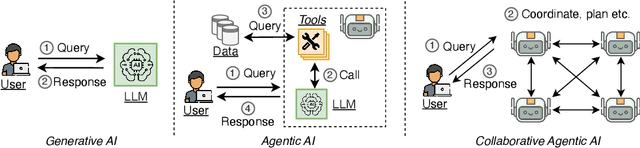
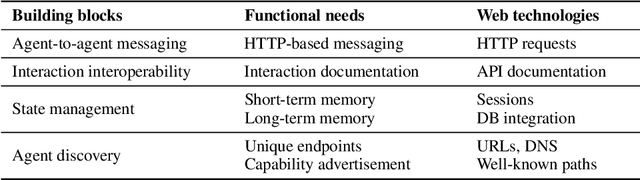
Collaborative agentic AI is projected to transform entire industries by enabling AI-powered agents to autonomously perceive, plan, and act within digital environments. Yet, current solutions in this field are all built in isolation, and we are rapidly heading toward a landscape of fragmented, incompatible ecosystems. In this position paper, we argue that interoperability, achieved by the adoption of minimal standards, is essential to ensure open, secure, web-scale, and widely-adopted agentic ecosystems. To this end, we devise a minimal architectural foundation for collaborative agentic AI, named Web of Agents, which is composed of four components: agent-to-agent messaging, interaction interoperability, state management, and agent discovery. Web of Agents adopts existing standards and reuses existing infrastructure where possible. With Web of Agents, we take the first but critical step toward interoperable agentic systems and offer a pragmatic path forward before ecosystem fragmentation becomes the norm.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Apr 10, 2024
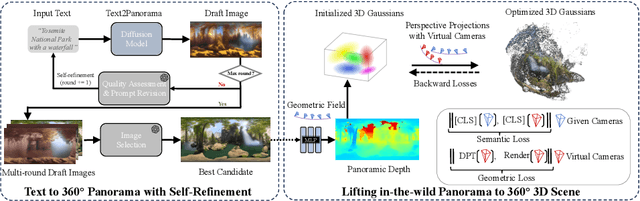
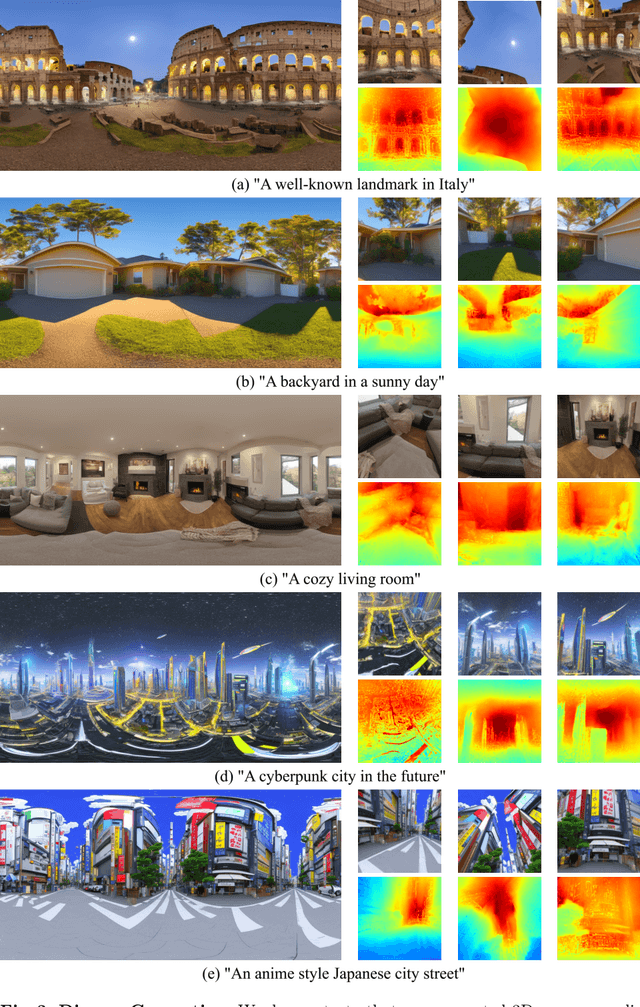

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Personalized Restoration via Dual-Pivot Tuning
Dec 28, 2023Generative diffusion models can serve as a prior which ensures that solutions of image restoration systems adhere to the manifold of natural images. However, for restoring facial images, a personalized prior is necessary to accurately represent and reconstruct unique facial features of a given individual. In this paper, we propose a simple, yet effective, method for personalized restoration, called Dual-Pivot Tuning - a two-stage approach that personalize a blind restoration system while maintaining the integrity of the general prior and the distinct role of each component. Our key observation is that for optimal personalization, the generative model should be tuned around a fixed text pivot, while the guiding network should be tuned in a generic (non-personalized) manner, using the personalized generative model as a fixed ``pivot". This approach ensures that personalization does not interfere with the restoration process, resulting in a natural appearance with high fidelity to the person's identity and the attributes of the degraded image. We evaluated our approach both qualitatively and quantitatively through extensive experiments with images of widely recognized individuals, comparing it against relevant baselines. Surprisingly, we found that our personalized prior not only achieves higher fidelity to identity with respect to the person's identity, but also outperforms state-of-the-art generic priors in terms of general image quality. Project webpage: https://personalized-restoration.github.io
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Dec 06, 2023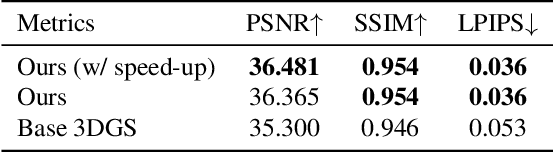
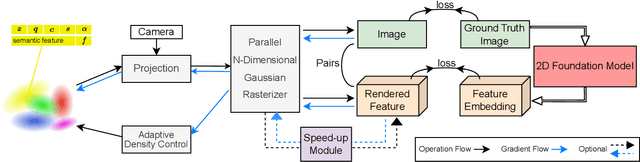
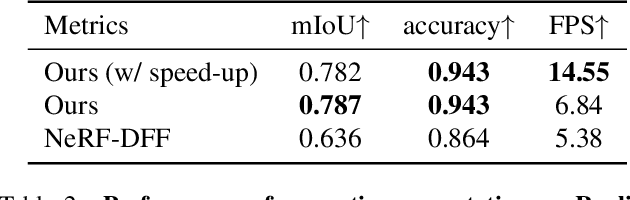
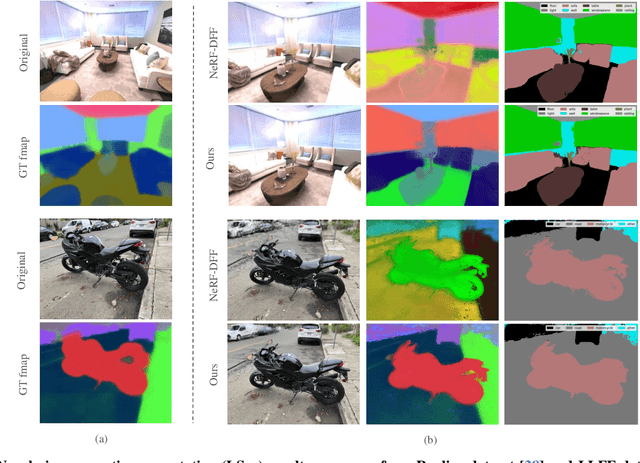
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework leads to warp-level divergence. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
SparseGS: Real-Time 360° Sparse View Synthesis using Gaussian Splatting
Nov 30, 2023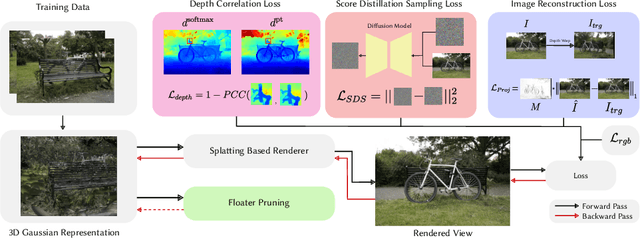

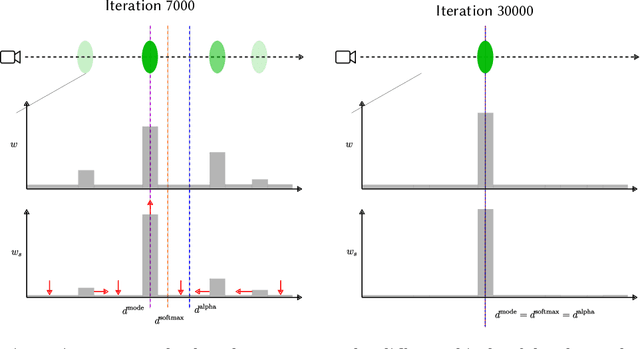

The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360 scenes from sparse training views. We find that using naive depth priors is not sufficient and integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by up to 30.5% and NeRF-based methods by up to 15.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.
CG3D: Compositional Generation for Text-to-3D via Gaussian Splatting
Nov 29, 2023


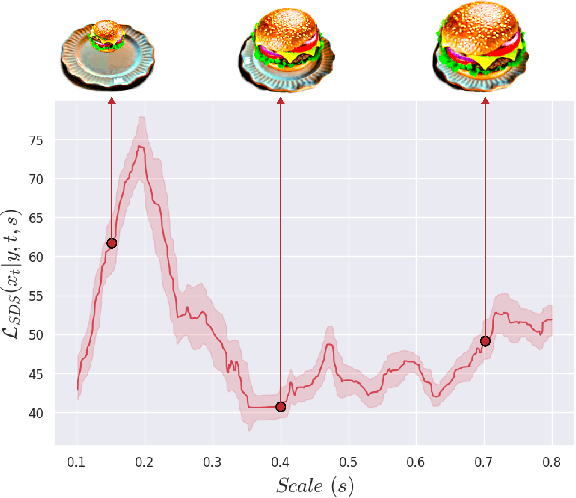
With the onset of diffusion-based generative models and their ability to generate text-conditioned images, content generation has received a massive invigoration. Recently, these models have been shown to provide useful guidance for the generation of 3D graphics assets. However, existing work in text-conditioned 3D generation faces fundamental constraints: (i) inability to generate detailed, multi-object scenes, (ii) inability to textually control multi-object configurations, and (iii) physically realistic scene composition. In this work, we propose CG3D, a method for compositionally generating scalable 3D assets that resolves these constraints. We find that explicit Gaussian radiance fields, parameterized to allow for compositions of objects, possess the capability to enable semantically and physically consistent scenes. By utilizing a guidance framework built around this explicit representation, we show state of the art results, capable of even exceeding the guiding diffusion model in terms of object combinations and physics accuracy.
Making Thermal Imaging More Equitable and Accurate: Resolving Solar Loading Biases
Apr 18, 2023
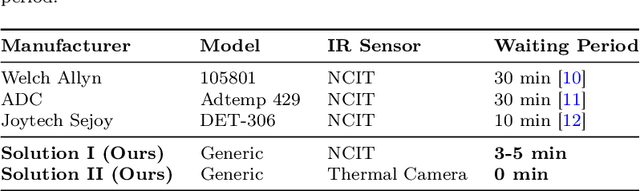


Thermal cameras and thermal point detectors are used to measure the temperature of human skin. These are important devices that are used everyday in clinical and mass screening settings, particularly in an epidemic. Unfortunately, despite the wide use of thermal sensors, the temperature estimates from thermal sensors do not work well in uncontrolled scene conditions. Previous work has studied the effect of wind and other environment factors on skin temperature, but has not considered the heating effect from sunlight, which is termed solar loading. Existing device manufacturers recommend that a subject who has been outdoors in sun re-acclimate to an indoor environment after a waiting period. The waiting period, up to 30 minutes, is insufficient for a rapid screening tool. Moreover, the error bias from solar loading is greater for darker skin tones since melanin absorbs solar radiation. This paper explores two approaches to address this problem. The first approach uses transient behavior of cooling to more quickly extrapolate the steady state temperature. A second approach explores the spatial modulation of solar loading, to propose single-shot correction with a wide-field thermal camera. A real world dataset comprising of thermal point, thermal image, subjective, and objective measurements of melanin is collected with statistical significance for the effect size observed. The single-shot correction scheme is shown to eliminate solar loading bias in the time of a typical frame exposure (33ms).
MIME: Minority Inclusion for Majority Group Enhancement of AI Performance
Sep 01, 2022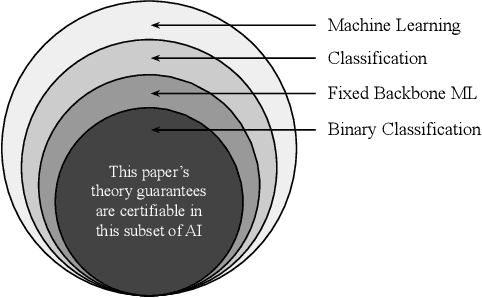

Several papers have rightly included minority groups in artificial intelligence (AI) training data to improve test inference for minority groups and/or society-at-large. A society-at-large consists of both minority and majority stakeholders. A common misconception is that minority inclusion does not increase performance for majority groups alone. In this paper, we make the surprising finding that including minority samples can improve test error for the majority group. In other words, minority group inclusion leads to majority group enhancements (MIME) in performance. A theoretical existence proof of the MIME effect is presented and found to be consistent with experimental results on six different datasets. Project webpage: https://visual.ee.ucla.edu/mime.htm/
Optimal HDR and Depth from Dual Cameras
Mar 12, 2020
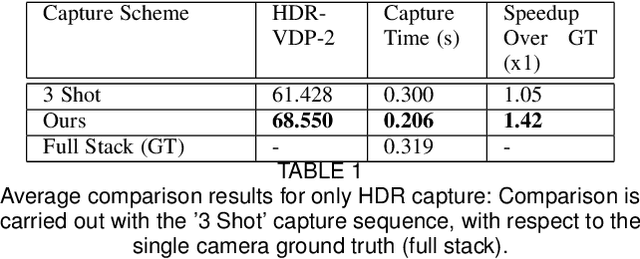
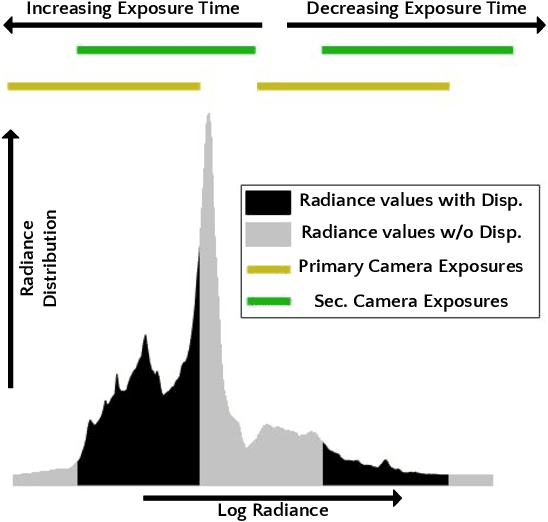
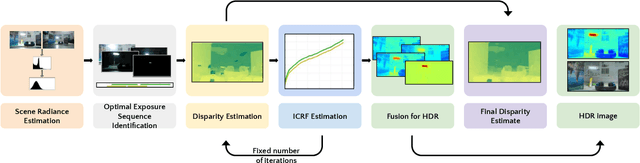
Dual camera systems have assisted in the proliferation of various applications, such as optical zoom, low-light imaging and High Dynamic Range (HDR) imaging. In this work, we explore an optimal method for capturing the scene HDR and disparity map using dual camera setups. Hasinoff et al. (2010) have developed a noise optimal framework for HDR capture from a single camera. We generalize this to the dual camera set-up for estimating both HDR and disparity map. It may seem that dual camera systems can capture HDR in a shorter time. However, disparity estimation is a necessary step, which requires overlap among the images captured by the two cameras. This may lead to an increase in the capture time. To address this conflicting requirement, we propose a novel framework to find the optimal exposure and ISO sequence by minimizing the capture time under the constraints of an upper bound on the disparity error and a lower bound on the per-exposure SNR. We show that the resulting optimization problem is non-convex in general and propose an appropriate initialization technique. To obtain the HDR and disparity map from the optimal capture sequence, we propose a pipeline which alternates between estimating the camera ICRFs and the scene disparity map. We demonstrate that our optimal capture sequence leads to better results than other possible capture sequences. Our results are also close to those obtained by capturing the full stereo stack spanning the entire dynamic range. Finally, we present for the first time a stereo HDR dataset consisting of dense ISO and exposure stack captured from a smartphone dual camera. The dataset consists of 6 scenes, with an average of 142 exposure-ISO image sequence per scene.