 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeMS: Efficient Gaussian Splatting for Extreme Motion Blur
Aug 20, 2025We introduce GeMS, a framework for 3D Gaussian Splatting (3DGS) designed to handle severely motion-blurred images. State-of-the-art deblurring methods for extreme blur, such as ExBluRF, as well as Gaussian Splatting-based approaches like Deblur-GS, typically assume access to sharp images for camera pose estimation and point cloud generation, an unrealistic assumption. Methods relying on COLMAP initialization, such as BAD-Gaussians, also fail due to unreliable feature correspondences under severe blur. To address these challenges, we propose GeMS, a 3DGS framework that reconstructs scenes directly from extremely blurred images. GeMS integrates: (1) VGGSfM, a deep learning-based Structure-from-Motion pipeline that estimates poses and generates point clouds directly from blurred inputs; (2) 3DGS-MCMC, which enables robust scene initialization by treating Gaussians as samples from a probability distribution, eliminating heuristic densification and pruning; and (3) joint optimization of camera trajectories and Gaussian parameters for stable reconstruction. While this pipeline produces strong results, inaccuracies may remain when all inputs are severely blurred. To mitigate this, we propose GeMS-E, which integrates a progressive refinement step using events: (4) Event-based Double Integral (EDI) deblurring restores sharper images that are then fed into GeMS, improving pose estimation, point cloud generation, and overall reconstruction. Both GeMS and GeMS-E achieve state-of-the-art performance on synthetic and real-world datasets. To our knowledge, this is the first framework to address extreme motion blur within 3DGS directly from severely blurred inputs.
SPC to 3D: Novel View Synthesis from Binary SPC via I2I translation
Jun 07, 2025



Single Photon Avalanche Diodes (SPADs) represent a cutting-edge imaging technology, capable of detecting individual photons with remarkable timing precision. Building on this sensitivity, Single Photon Cameras (SPCs) enable image capture at exceptionally high speeds under both low and high illumination. Enabling 3D reconstruction and radiance field recovery from such SPC data holds significant promise. However, the binary nature of SPC images leads to severe information loss, particularly in texture and color, making traditional 3D synthesis techniques ineffective. To address this challenge, we propose a modular two-stage framework that converts binary SPC images into high-quality colorized novel views. The first stage performs image-to-image (I2I) translation using generative models such as Pix2PixHD, converting binary SPC inputs into plausible RGB representations. The second stage employs 3D scene reconstruction techniques like Neural Radiance Fields (NeRF) or Gaussian Splatting (3DGS) to generate novel views. We validate our two-stage pipeline (Pix2PixHD + Nerf/3DGS) through extensive qualitative and quantitative experiments, demonstrating significant improvements in perceptual quality and geometric consistency over the alternative baseline.
RT-X Net: RGB-Thermal cross attention network for Low-Light Image Enhancement
May 30, 2025In nighttime conditions, high noise levels and bright illumination sources degrade image quality, making low-light image enhancement challenging. Thermal images provide complementary information, offering richer textures and structural details. We propose RT-X Net, a cross-attention network that fuses RGB and thermal images for nighttime image enhancement. We leverage self-attention networks for feature extraction and a cross-attention mechanism for fusion to effectively integrate information from both modalities. To support research in this domain, we introduce the Visible-Thermal Image Enhancement Evaluation (V-TIEE) dataset, comprising 50 co-located visible and thermal images captured under diverse nighttime conditions. Extensive evaluations on the publicly available LLVIP dataset and our V-TIEE dataset demonstrate that RT-X Net outperforms state-of-the-art methods in low-light image enhancement. The code and the V-TIEE can be found here https://github.com/jhakrraman/rt-xnet.
FlatTrack: Eye-tracking with ultra-thin lensless cameras
Jan 26, 2025Existing eye trackers use cameras based on thick compound optical elements, necessitating the cameras to be placed at focusing distance from the eyes. This results in the overall bulk of wearable eye trackers, especially for augmented and virtual reality (AR/VR) headsets. We overcome this limitation by building a compact flat eye gaze tracker using mask-based lensless cameras. These cameras, in combination with co-designed lightweight deep neural network algorithm, can be placed in extreme close proximity to the eye, within the eyeglasses frame, resulting in ultra-flat and lightweight eye gaze tracker system. We collect a large dataset of near-eye lensless camera measurements along with their calibrated gaze directions for training the gaze tracking network. Through real and simulation experiments, we show that the proposed gaze tracking system performs on par with conventional lens-based trackers while maintaining a significantly flatter and more compact form-factor. Moreover, our gaze regressor boasts real-time (>125 fps) performance for gaze tracking.
IP-FaceDiff: Identity-Preserving Facial Video Editing with Diffusion
Jan 13, 2025Facial video editing has become increasingly important for content creators, enabling the manipulation of facial expressions and attributes. However, existing models encounter challenges such as poor editing quality, high computational costs and difficulties in preserving facial identity across diverse edits. Additionally, these models are often constrained to editing predefined facial attributes, limiting their flexibility to diverse editing prompts. To address these challenges, we propose a novel facial video editing framework that leverages the rich latent space of pre-trained text-to-image (T2I) diffusion models and fine-tune them specifically for facial video editing tasks. Our approach introduces a targeted fine-tuning scheme that enables high quality, localized, text-driven edits while ensuring identity preservation across video frames. Additionally, by using pre-trained T2I models during inference, our approach significantly reduces editing time by 80%, while maintaining temporal consistency throughout the video sequence. We evaluate the effectiveness of our approach through extensive testing across a wide range of challenging scenarios, including varying head poses, complex action sequences, and diverse facial expressions. Our method consistently outperforms existing techniques, demonstrating superior performance across a broad set of metrics and benchmarks.
BeSplat -- Gaussian Splatting from a Single Blurry Image and Event Stream
Dec 26, 2024Novel view synthesis has been greatly enhanced by the development of radiance field methods. The introduction of 3D Gaussian Splatting (3DGS) has effectively addressed key challenges, such as long training times and slow rendering speeds, typically associated with Neural Radiance Fields (NeRF), while maintaining high-quality reconstructions. In this work (BeSplat), we demonstrate the recovery of sharp radiance field (Gaussian splats) from a single motion-blurred image and its corresponding event stream. Our method jointly learns the scene representation via Gaussian Splatting and recovers the camera motion through Bezier SE(3) formulation effectively, minimizing discrepancies between synthesized and real-world measurements of both blurry image and corresponding event stream. We evaluate our approach on both synthetic and real datasets, showcasing its ability to render view-consistent, sharp images from the learned radiance field and the estimated camera trajectory. To the best of our knowledge, ours is the first work to address this highly challenging ill-posed problem in a Gaussian Splatting framework with the effective incorporation of temporal information captured using the event stream.
Transforming Single Photon Camera Images to Color High Dynamic Range Images
Dec 17, 2024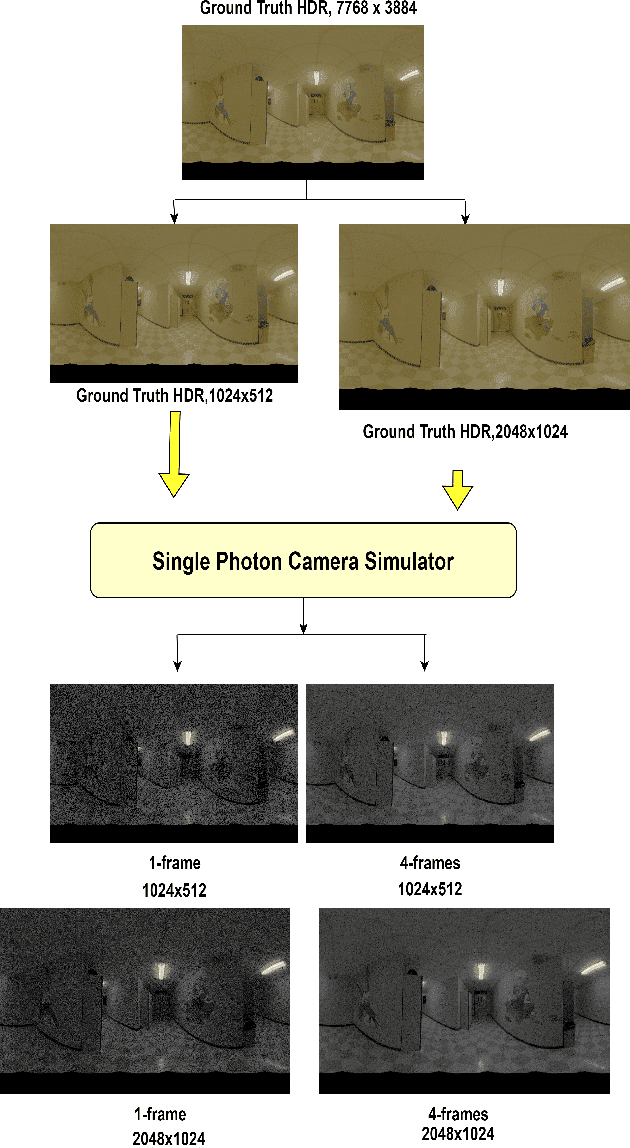


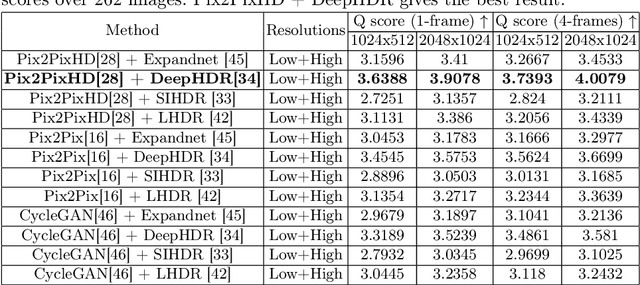
Traditional CMOS sensors suffer from restricted dynamic range and sub optimal performance under extreme lighting conditions. They are affected by electronic noise in low light conditions and pixel saturation while capturing high illumination. Recent High Dynamic Range (HDR) Imaging methods, often designed for CMOS Sensors, attempt to address these issues by fusing multiple exposures. However, they frequently introduce artifacts like ghosting and light flickering in dynamic scenarios and non-uniform signal-to-noise ratio in extreme dynamic range conditions. Recently, Single Photon Avalanche Diodes (SPADs), also known as Single Photon Camera (SPC) sensors, have surpassed CMOS sensors due to their capability to capture individual photons with high timing precision. Unlike traditional digital cameras that first convert light energy into analog electrical currents and then digitize them, SPAD sensors perform direct photon detection, making them less susceptible to extreme illumination conditions. Their distinctive non-linear response curve aids in capturing photons across both low-light and high-illumination environments, making them particularly effective for High Dynamic Range Imaging. Despite their advantages, images from SPAD Sensors are often noisy and visually unappealing. To address these challenges, we evaluate state-of-the-art architectures for converting monochromatic SPAD images into Color HDR images at various resolutions. Our evaluation involves both qualitative and quantitative assessments of these architectures, focusing on their effectiveness in each stage of the conversion process.
GN-FR:Generalizable Neural Radiance Fields for Flare Removal
Dec 11, 2024



Flare, an optical phenomenon resulting from unwanted scattering and reflections within a lens system, presents a significant challenge in imaging. The diverse patterns of flares, such as halos, streaks, color bleeding, and haze, complicate the flare removal process. Existing traditional and learning-based methods have exhibited limited efficacy due to their reliance on single-image approaches, where flare removal is highly ill-posed. We address this by framing flare removal as a multi-view image problem, taking advantage of the view-dependent nature of flare artifacts. This approach leverages information from neighboring views to recover details obscured by flare in individual images. Our proposed framework, GN-FR (Generalizable Neural Radiance Fields for Flare Removal), can render flare-free views from a sparse set of input images affected by lens flare and generalizes across different scenes in an unsupervised manner. GN-FR incorporates several modules within the Generalizable NeRF Transformer (GNT) framework: Flare-occupancy Mask Generation (FMG), View Sampler (VS), and Point Sampler (PS). To overcome the impracticality of capturing both flare-corrupted and flare-free data, we introduce a masking loss function that utilizes mask information in an unsupervised setting. Additionally, we present a 3D multi-view flare dataset, comprising 17 real flare scenes with 782 images, 80 real flare patterns, and their corresponding annotated flare-occupancy masks. To our knowledge, this is the first work to address flare removal within a Neural Radiance Fields (NeRF) framework.
U2NeRF: Unsupervised Underwater Image Restoration and Neural Radiance Fields
Nov 25, 2024Underwater images suffer from colour shifts, low contrast, and haziness due to light absorption, refraction, scattering and restoring these images has warranted much attention. In this work, we present Unsupervised Underwater Neural Radiance Field U2NeRF, a transformer-based architecture that learns to render and restore novel views conditioned on multi-view geometry simultaneously. Due to the absence of supervision, we attempt to implicitly bake restoring capabilities onto the NeRF pipeline and disentangle the predicted color into several components - scene radiance, direct transmission map, backscatter transmission map, and global background light, and when combined reconstruct the underwater image in a self-supervised manner. In addition, we release an Underwater View Synthesis UVS dataset consisting of 12 underwater scenes, containing both synthetically-generated and real-world data. Our experiments demonstrate that when optimized on a single scene, U2NeRF outperforms several baselines by as much LPIPS 11%, UIQM 5%, UCIQE 4% (on average) and showcases improved rendering and restoration capabilities. Code will be made available upon acceptance.
GANESH: Generalizable NeRF for Lensless Imaging
Nov 07, 2024



Lensless imaging offers a significant opportunity to develop ultra-compact cameras by removing the conventional bulky lens system. However, without a focusing element, the sensor's output is no longer a direct image but a complex multiplexed scene representation. Traditional methods have attempted to address this challenge by employing learnable inversions and refinement models, but these methods are primarily designed for 2D reconstruction and do not generalize well to 3D reconstruction. We introduce GANESH, a novel framework designed to enable simultaneous refinement and novel view synthesis from multi-view lensless images. Unlike existing methods that require scene-specific training, our approach supports on-the-fly inference without retraining on each scene. Moreover, our framework allows us to tune our model to specific scenes, enhancing the rendering and refinement quality. To facilitate research in this area, we also present the first multi-view lensless dataset, LenslessScenes. Extensive experiments demonstrate that our method outperforms current approaches in reconstruction accuracy and refinement quality. Code and video results are available at https://rakesh-123-cryp.github.io/Rakesh.github.io/