 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-X Net: RGB-Thermal cross attention network for Low-Light Image Enhancement
May 30, 2025In nighttime conditions, high noise levels and bright illumination sources degrade image quality, making low-light image enhancement challenging. Thermal images provide complementary information, offering richer textures and structural details. We propose RT-X Net, a cross-attention network that fuses RGB and thermal images for nighttime image enhancement. We leverage self-attention networks for feature extraction and a cross-attention mechanism for fusion to effectively integrate information from both modalities. To support research in this domain, we introduce the Visible-Thermal Image Enhancement Evaluation (V-TIEE) dataset, comprising 50 co-located visible and thermal images captured under diverse nighttime conditions. Extensive evaluations on the publicly available LLVIP dataset and our V-TIEE dataset demonstrate that RT-X Net outperforms state-of-the-art methods in low-light image enhancement. The code and the V-TIEE can be found here https://github.com/jhakrraman/rt-xnet.
PS$^2$F: Polarized Spiral Point Spread Function for Single-Shot 3D Sensing
Jul 03, 2022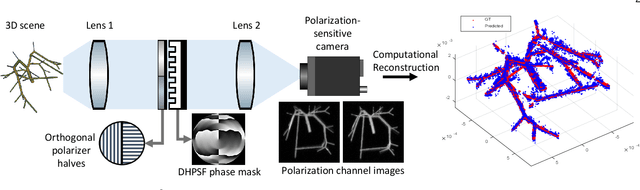
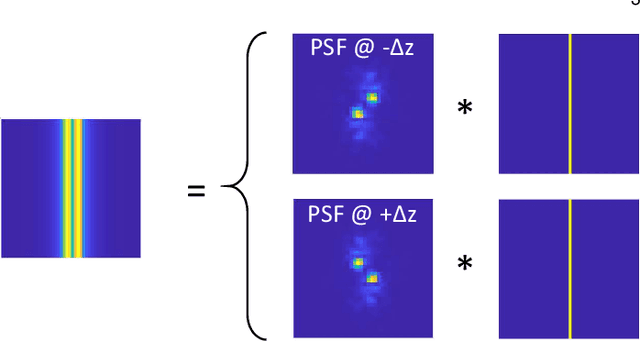
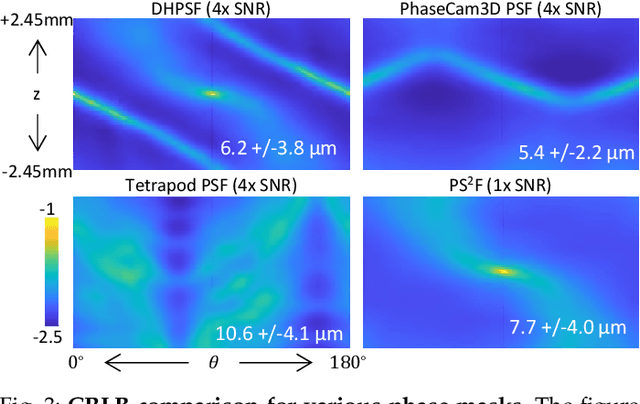
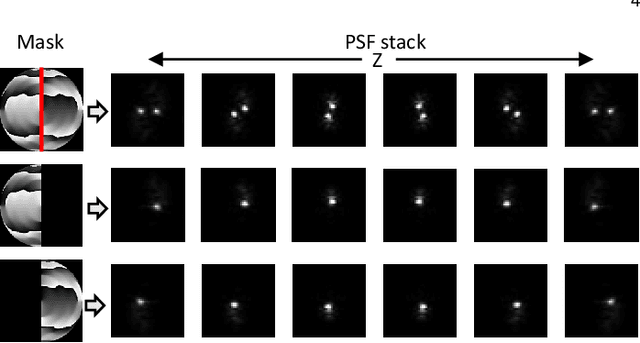
We propose a compact snapshot monocular depth estimation technique that relies on an engineered point spread function (PSF). Traditional approaches used in microscopic super-resolution imaging, such as the Double-Helix PSF (DHPSF), are ill-suited for scenes that are more complex than a sparse set of point light sources. We show, using the Cram\'er-Rao lower bound (CRLB), that separating the two lobes of the DHPSF and thereby capturing two separate images leads to a dramatic increase in depth accuracy. A unique property of the phase mask used for generating the DHPSF is that a separation of the phase mask into two halves leads to a spatial separation of the two lobes. We leverage this property to build a compact polarization-based optical setup, where we place two orthogonal linear polarizers on each half of the DHPSF phase mask and then capture the resulting image with a polarization sensitive camera. Results from simulations and a lab prototype demonstrate that our technique achieves up to $50\%$ lower depth error compared to state-of-the-art designs including the DHPSF, and the Tetrapod PSF, with little to no loss in spatial resolution.
A Hybrid mmWave and Camera System for Long-Range Depth Imaging
Jun 15, 2021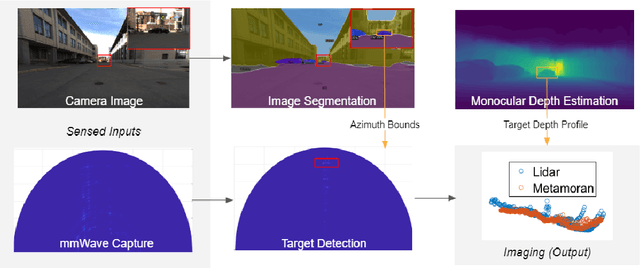
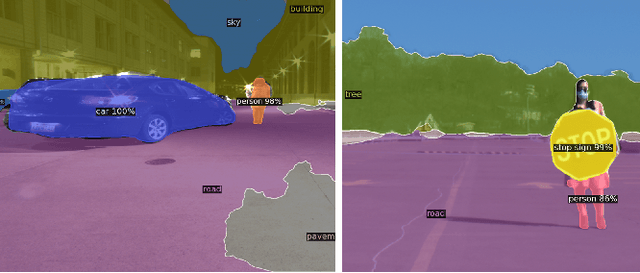
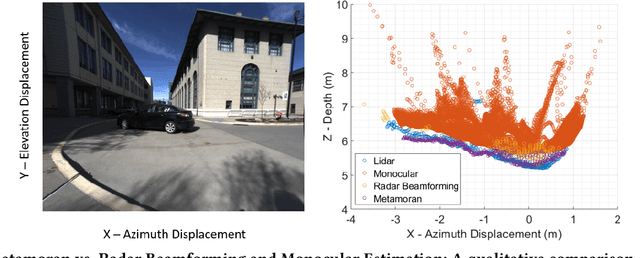

mmWave radars offer excellent depth resolution owing to their high bandwidth at mmWave radio frequencies. Yet, they suffer intrinsically from poor angular resolution, that is an order-of-magnitude worse than camera systems, and are therefore not a capable 3-D imaging solution in isolation. We propose Metamoran, a system that combines the complimentary strengths of radar and camera systems to obtain depth images at high azimuthal resolutions at distances of several tens of meters with high accuracy, all from a single fixed vantage point. Metamoran enables rich long-range depth imaging outdoors with applications to roadside safety infrastructure, surveillance and wide-area mapping. Our key insight is to use the high azimuth resolution from cameras using computer vision techniques, including image segmentation and monocular depth estimation, to obtain object shapes and use these as priors for our novel specular beamforming algorithm. We also design this algorithm to work in cluttered environments with weak reflections and in partially occluded scenarios. We perform a detailed evaluation of Metamoran's depth imaging and sensing capabilities in 200 diverse scenes at a major U.S. city. Our evaluation shows that Metamoran estimates the depth of an object up to 60~m away with a median error of 28~cm, an improvement of 13$\times$ compared to a naive radar+camera baseline and 23$\times$ compared to monocular depth estimation.
SASSI -- Super-Pixelated Adaptive Spatio-Spectral Imaging
Dec 28, 2020
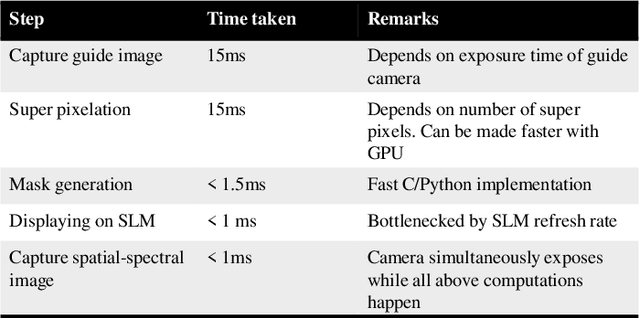


We introduce a novel video-rate hyperspectral imager with high spatial, and temporal resolutions. Our key hypothesis is that spectral profiles of pixels in a super-pixel of an oversegmented image tend to be very similar. Hence, a scene-adaptive spatial sampling of an hyperspectral scene, guided by its super-pixel segmented image, is capable of obtaining high-quality reconstructions. To achieve this, we acquire an RGB image of the scene, compute its super-pixels, from which we generate a spatial mask of locations where we measure high-resolution spectrum. The hyperspectral image is subsequently estimated by fusing the RGB image and the spectral measurements using a learnable guided filtering approach. Due to low computational complexity of the superpixel estimation step, our setup can capture hyperspectral images of the scenes with little overhead over traditional snapshot hyperspectral cameras, but with significantly higher spatial and spectral resolutions. We validate the proposed technique with extensive simulations as well as a lab prototype that measures hyperspectral video at a spatial resolution of $600 \times 900$ pixels, at a spectral resolution of 10 nm over visible wavebands, and achieving a frame rate at $18$fps.
Halluci-Net: Scene Completion by Exploiting Object Co-occurrence Relationships
Apr 18, 2020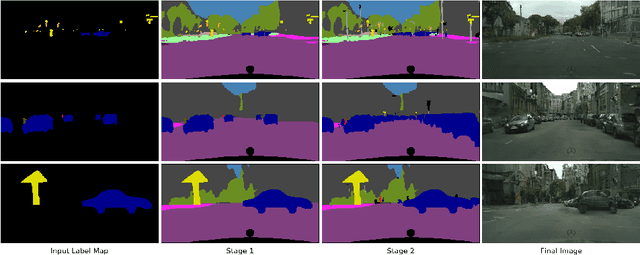

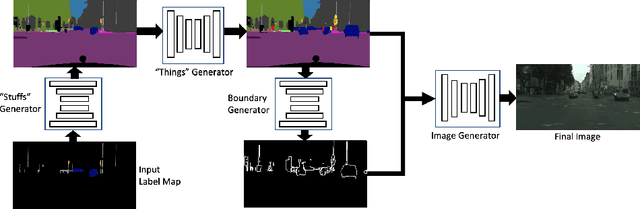

We address the new problem of complex scene completion from sparse label maps. We use a two-stage deep network based method, called `Halluci-Net', that uses object co-occurrence relationships to produce a dense and complete label map. The generated dense label map is fed into a state-of-the-art image synthesis method to obtain the final image. The proposed method is evaluated on the Cityscapes dataset and it outperforms a single-stage baseline method on various performance metrics like Fr\'echet Inception Distance (FID), semantic segmentation accuracy, and similarity in object co-occurrences. In addition to this, we show qualitative results on a subset of ADE20K dataset containing bedroom images.
On Space-spectrum Uncertainty Analysis for Coded Aperture Systems
Nov 16, 2019
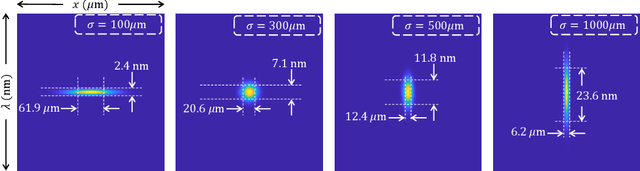
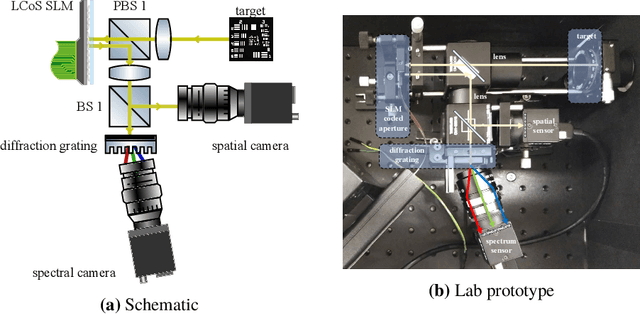

We introduce and analyze the concept of space-spectrum uncertainty for certain commonly-used designs for spectrally programmable cameras. Our key finding states that, it is impossible to simultaneously capture high-resolution spatial images while programming the spectrum at high resolution. This phenomenon arises due to a Fourier relationship between the aperture used for obtaining spectrum and its corresponding diffraction blur in the (spatial) image. We show that the product of spatial and spectral standard deviations is lower bounded by {\lambda}/4{\pi}{\nu_0} femto square-meters, where {\nu_0} is the density of groves in the diffraction grating and {\lambda} is the wavelength of light. Experiments with a lab prototype for simultaneously measuring spectrum and image validate our findings and its implication for spectral filtering.
Cross-scale predictive dictionaries
Sep 04, 2018
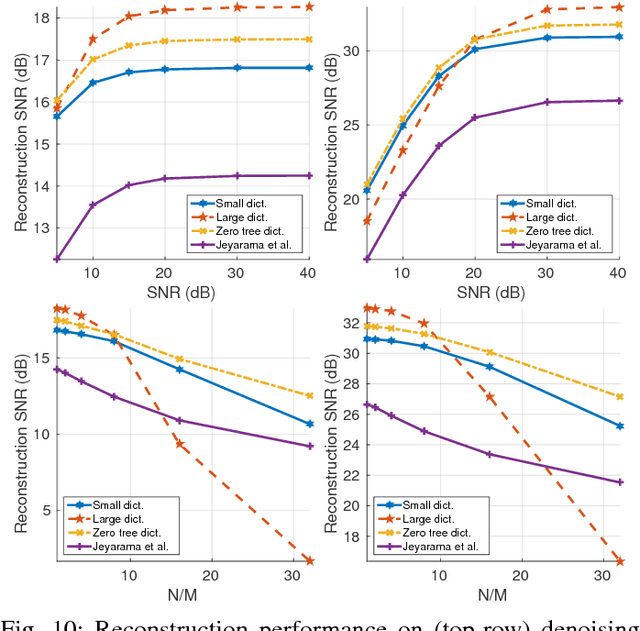
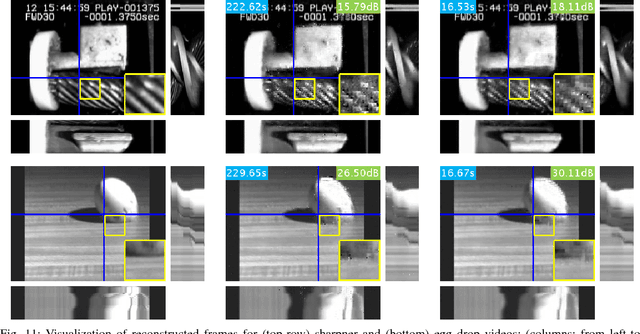
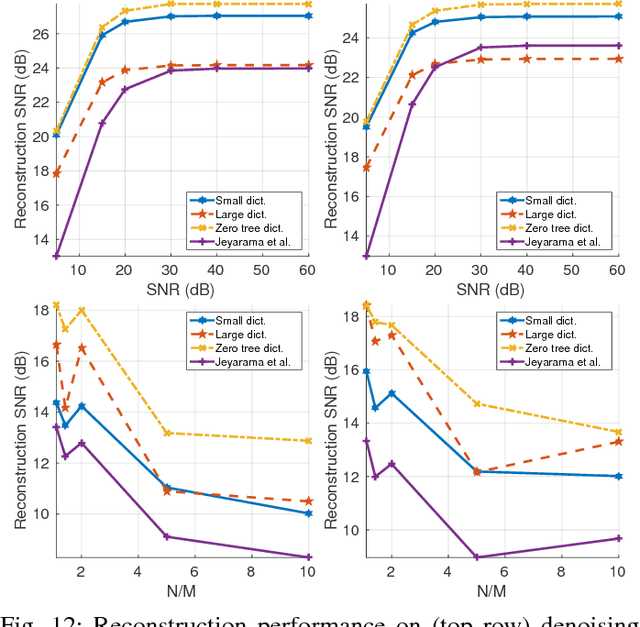
Sparse representations using data dictionaries provide an efficient model particularly for signals that do not enjoy alternate analytic sparsifying transformations. However, solving inverse problems with sparsifying dictionaries can be computationally expensive, especially when the dictionary under consideration has a large number of atoms. In this paper, we incorporate additional structure on to dictionary-based sparse representations for visual signals to enable speedups when solving sparse approximation problems. The specific structure that we endow onto sparse models is that of a multi-scale modeling where the sparse representation at each scale is constrained by the sparse representation at coarser scales. We show that this cross-scale predictive model delivers significant speedups, often in the range of 10-60$\times$, with little loss in accuracy for linear inverse problems associated with images, videos, and light fields.
FlatCam: Thin, Bare-Sensor Cameras using Coded Aperture and Computation
Jan 27, 2016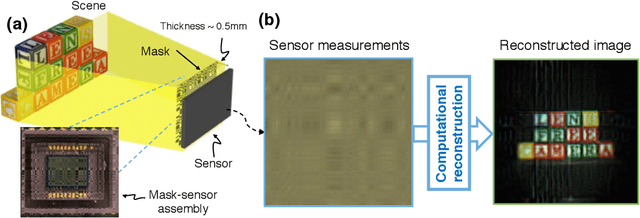
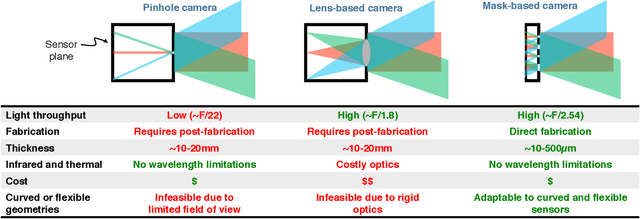
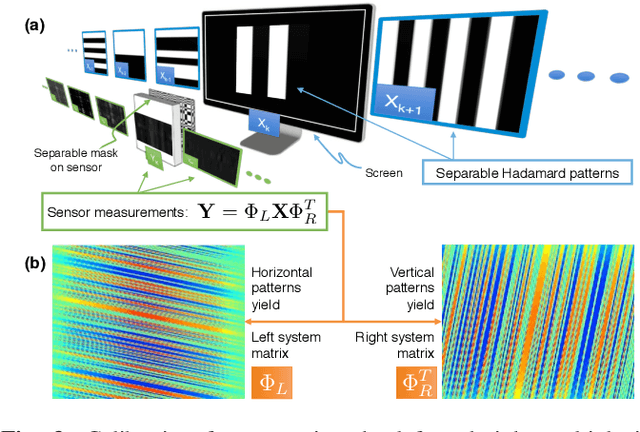

FlatCam is a thin form-factor lensless camera that consists of a coded mask placed on top of a bare, conventional sensor array. Unlike a traditional, lens-based camera where an image of the scene is directly recorded on the sensor pixels, each pixel in FlatCam records a linear combination of light from multiple scene elements. A computational algorithm is then used to demultiplex the recorded measurements and reconstruct an image of the scene. FlatCam is an instance of a coded aperture imaging system; however, unlike the vast majority of related work, we place the coded mask extremely close to the image sensor that can enable a thin system. We employ a separable mask to ensure that both calibration and image reconstruction are scalable in terms of memory requirements and computational complexity. We demonstrate the potential of the FlatCam design using two prototypes: one at visible wavelengths and one at infrared wavelengths.