 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Adaptation of Grounding DINO for Agricultural Domain
Apr 09, 2025Deep learning models are transforming agricultural applications by enabling automated phenotyping, monitoring, and yield estimation. However, their effectiveness heavily depends on large amounts of annotated training data, which can be labor and time intensive. Recent advances in open-set object detection, particularly with models like Grounding-DINO, offer a potential solution to detect regions of interests based on text prompt input. Initial zero-shot experiments revealed challenges in crafting effective text prompts, especially for complex objects like individual leaves and visually similar classes. To address these limitations, we propose an efficient few-shot adaptation method that simplifies the Grounding-DINO architecture by removing the text encoder module (BERT) and introducing a randomly initialized trainable text embedding. This method achieves superior performance across multiple agricultural datasets, including plant-weed detection, plant counting, insect identification, fruit counting, and remote sensing tasks. Specifically, it demonstrates up to a $\sim24\%$ higher mAP than fully fine-tuned YOLO models on agricultural datasets and outperforms previous state-of-the-art methods by $\sim10\%$ in remote sensing, under few-shot learning conditions. Our method offers a promising solution for automating annotation and accelerating the development of specialized agricultural AI solutions.
Self-Supervised Backbone Framework for Diverse Agricultural Vision Tasks
Mar 22, 2024



Computer vision in agriculture is game-changing with its ability to transform farming into a data-driven, precise, and sustainable industry. Deep learning has empowered agriculture vision to analyze vast, complex visual data, but heavily rely on the availability of large annotated datasets. This remains a bottleneck as manual labeling is error-prone, time-consuming, and expensive. The lack of efficient labeling approaches inspired us to consider self-supervised learning as a paradigm shift, learning meaningful feature representations from raw agricultural image data. In this work, we explore how self-supervised representation learning unlocks the potential applicability to diverse agriculture vision tasks by eliminating the need for large-scale annotated datasets. We propose a lightweight framework utilizing SimCLR, a contrastive learning approach, to pre-train a ResNet-50 backbone on a large, unannotated dataset of real-world agriculture field images. Our experimental analysis and results indicate that the model learns robust features applicable to a broad range of downstream agriculture tasks discussed in the paper. Additionally, the reduced reliance on annotated data makes our approach more cost-effective and accessible, paving the way for broader adoption of computer vision in agriculture.
Polynomial Implicit Neural Representations For Large Diverse Datasets
Mar 20, 2023



Implicit neural representations (INR) have gained significant popularity for signal and image representation for many end-tasks, such as superresolution, 3D modeling, and more. Most INR architectures rely on sinusoidal positional encoding, which accounts for high-frequency information in data. However, the finite encoding size restricts the model's representational power. Higher representational power is needed to go from representing a single given image to representing large and diverse datasets. Our approach addresses this gap by representing an image with a polynomial function and eliminates the need for positional encodings. Therefore, to achieve a progressively higher degree of polynomial representation, we use element-wise multiplications between features and affine-transformed coordinate locations after every ReLU layer. The proposed method is evaluated qualitatively and quantitatively on large datasets like ImageNet. The proposed Poly-INR model performs comparably to state-of-the-art generative models without any convolution, normalization, or self-attention layers, and with far fewer trainable parameters. With much fewer training parameters and higher representative power, our approach paves the way for broader adoption of INR models for generative modeling tasks in complex domains. The code is available at \url{https://github.com/Rajhans0/Poly_INR}
Deep Geometric Moment
May 24, 2022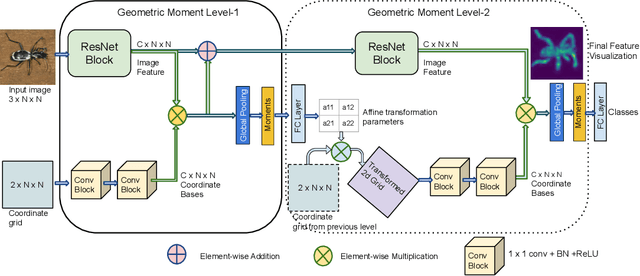


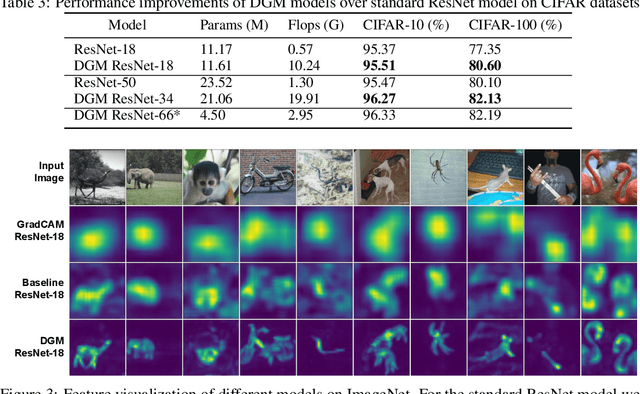
Deep networks for image classification often rely more on texture information than object shape. While efforts have been made to make deep-models shape-aware, it is often difficult to make such models simple, interpretable, or rooted in known mathematical definitions of shape. This paper presents a deep-learning model inspired by geometric moments, a classically well understood approach to measure shape-related properties. The proposed method consists of a trainable network for generating coordinate bases and affine parameters for making the features geometrically invariant, yet in a task-specific manner. The proposed model improves the final feature's interpretation. We demonstrate the effectiveness of our method on standard image classification datasets. The proposed model achieves higher classification performance as compared to the baseline and standard ResNet models while substantially improving interpretability.
Halluci-Net: Scene Completion by Exploiting Object Co-occurrence Relationships
Apr 18, 2020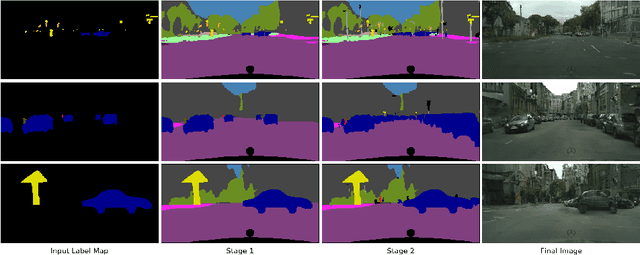

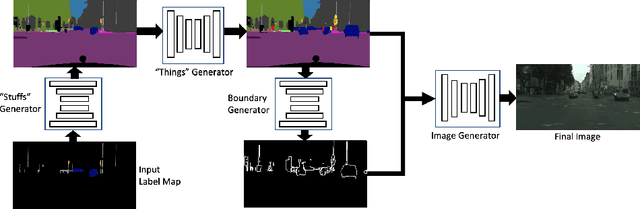

We address the new problem of complex scene completion from sparse label maps. We use a two-stage deep network based method, called `Halluci-Net', that uses object co-occurrence relationships to produce a dense and complete label map. The generated dense label map is fed into a state-of-the-art image synthesis method to obtain the final image. The proposed method is evaluated on the Cityscapes dataset and it outperforms a single-stage baseline method on various performance metrics like Fr\'echet Inception Distance (FID), semantic segmentation accuracy, and similarity in object co-occurrences. In addition to this, we show qualitative results on a subset of ADE20K dataset containing bedroom images.
Non-Parametric Priors For Generative Adversarial Networks
May 16, 2019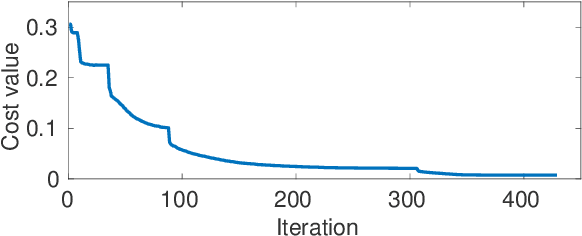

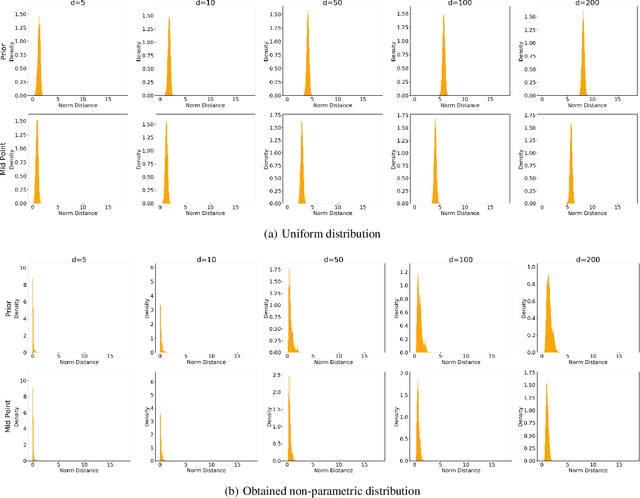
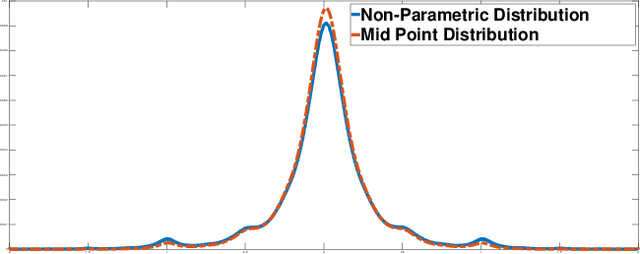
The advent of generative adversarial networks (GAN) has enabled new capabilities in synthesis, interpolation, and data augmentation heretofore considered very challenging. However, one of the common assumptions in most GAN architectures is the assumption of simple parametric latent-space distributions. While easy to implement, a simple latent-space distribution can be problematic for uses such as interpolation. This is due to distributional mismatches when samples are interpolated in the latent space. We present a straightforward formalization of this problem; using basic results from probability theory and off-the-shelf-optimization tools, we develop ways to arrive at appropriate non-parametric priors. The obtained prior exhibits unusual qualitative properties in terms of its shape, and quantitative benefits in terms of lower divergence with its mid-point distribution. We demonstrate that our designed prior helps improve image generation along any Euclidean straight line during interpolation, both qualitatively and quantitatively, without any additional training or architectural modifications. The proposed formulation is quite flexible, paving the way to impose newer constraints on the latent-space statistics.
Rate-Adaptive Neural Networks for Spatial Multiplexers
Sep 08, 2018
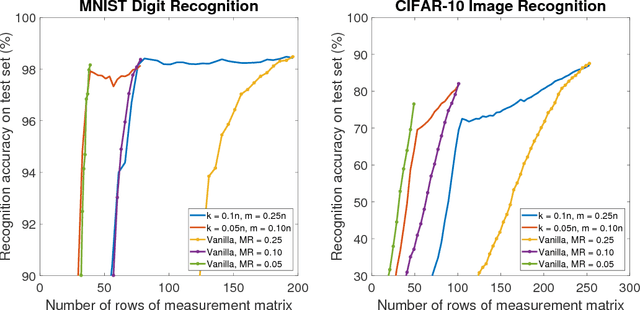
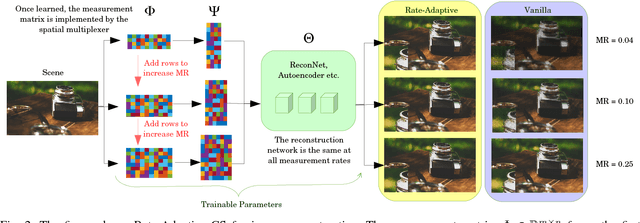

In resource-constrained environments, one can employ spatial multiplexing cameras to acquire a small number of measurements of a scene, and perform effective reconstruction or high-level inference using purely data-driven neural networks. However, once trained, the measurement matrix and the network are valid only for a single measurement rate (MR) chosen at training time. To overcome this drawback, we answer the following question: How can we jointly design the measurement operator and the reconstruction/inference network so that the system can operate over a \textit{range} of MRs? To this end, we present a novel training algorithm, for learning \textbf{\textit{rate-adaptive}} networks. Using standard datasets, we demonstrate that, when tested over a range of MRs, a rate-adaptive network can provide high quality reconstruction over a the entire range, resulting in up to about 15 dB improvement over previous methods, where the network is valid for only one MR. We demonstrate the effectiveness of our approach for sample-efficient object tracking where video frames are acquired at dynamically varying MRs. We also extend this algorithm to learn the measurement operator in conjunction with image recognition networks. Experiments on MNIST and CIFAR-10 confirm the applicability of our algorithm to different tasks.