 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG3Splat: Geometrically Consistent Generalizable Gaussian Splatting
Dec 19, 20253D Gaussians have recently emerged as an effective scene representation for real-time splatting and accurate novel-view synthesis, motivating several works to adapt multi-view structure prediction networks to regress per-pixel 3D Gaussians from images. However, most prior work extends these networks to predict additional Gaussian parameters -- orientation, scale, opacity, and appearance -- while relying almost exclusively on view-synthesis supervision. We show that a view-synthesis loss alone is insufficient to recover geometrically meaningful splats in this setting. We analyze and address the ambiguities of learning 3D Gaussian splats under self-supervision for pose-free generalizable splatting, and introduce G3Splat, which enforces geometric priors to obtain geometrically consistent 3D scene representations. Trained on RE10K, our approach achieves state-of-the-art performance in (i) geometrically consistent reconstruction, (ii) relative pose estimation, and (iii) novel-view synthesis. We further demonstrate strong zero-shot generalization on ScanNet, substantially outperforming prior work in both geometry recovery and relative pose estimation. Code and pretrained models are released on our project page (https://m80hz.github.io/g3splat/).
Category Level 6D Object Pose Estimation from a Single RGB Image using Diffusion
Dec 16, 2024



Estimating the 6D pose and 3D size of an object from an image is a fundamental task in computer vision. Most current approaches are restricted to specific instances with known models or require ground truth depth information or point cloud captures from LIDAR. We tackle the harder problem of pose estimation for category-level objects from a single RGB image. We propose a novel solution that eliminates the need for specific object models or depth information. Our method utilises score-based diffusion models to generate object pose hypotheses to model the distribution of possible poses for the object. Unlike previous methods that rely on costly trained likelihood estimators to remove outliers before pose aggregation using mean pooling, we introduce a simpler approach using Mean Shift to estimate the mode of the distribution as the final pose estimate. Our approach outperforms the current state-of-the-art on the REAL275 dataset by a significant margin.
Invertible Neural Warp for NeRF
Jul 17, 2024



This paper tackles the simultaneous optimization of pose and Neural Radiance Fields (NeRF). Departing from the conventional practice of using explicit global representations for camera pose, we propose a novel overparameterized representation that models camera poses as learnable rigid warp functions. We establish that modeling the rigid warps must be tightly coupled with constraints and regularization imposed. Specifically, we highlight the critical importance of enforcing invertibility when learning rigid warp functions via neural network and propose the use of an Invertible Neural Network (INN) coupled with a geometry-informed constraint for this purpose. We present results on synthetic and real-world datasets, and demonstrate that our approach outperforms existing baselines in terms of pose estimation and high-fidelity reconstruction due to enhanced optimization convergence.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022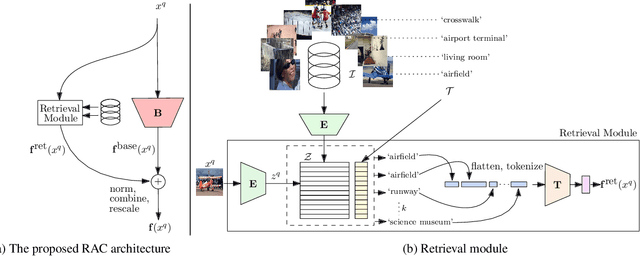
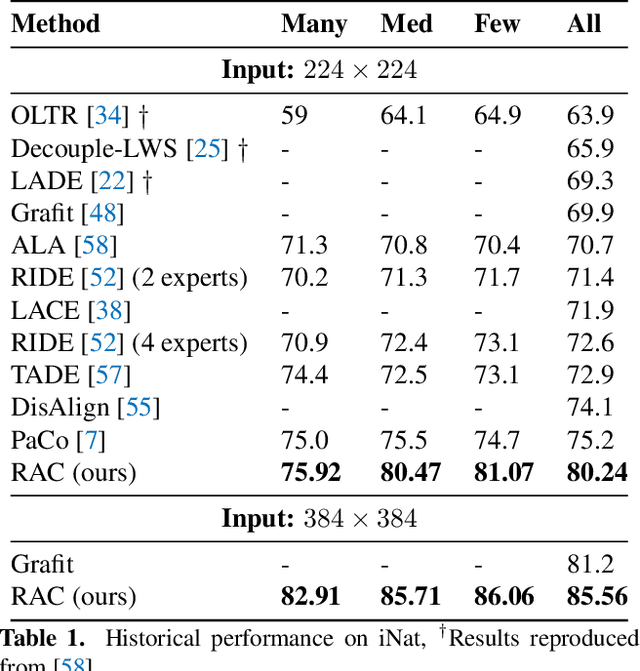
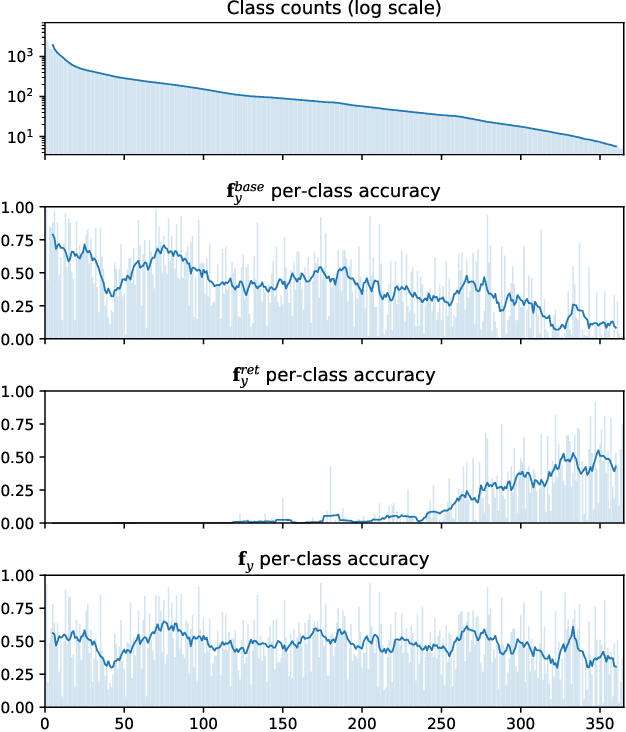
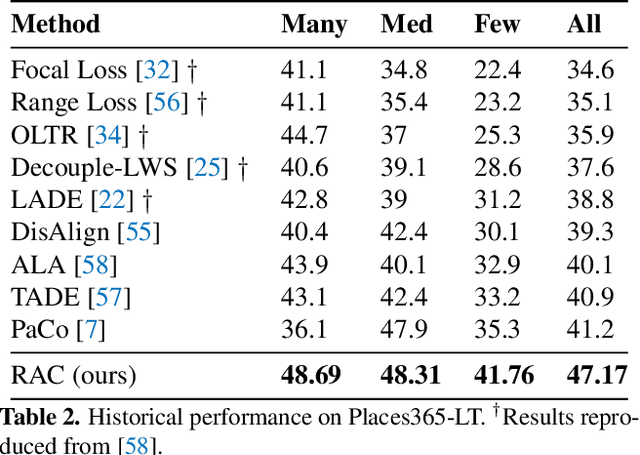
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Feasibility Study on Intra-Grid Location Estimation Using Power ENF Signals
May 03, 2021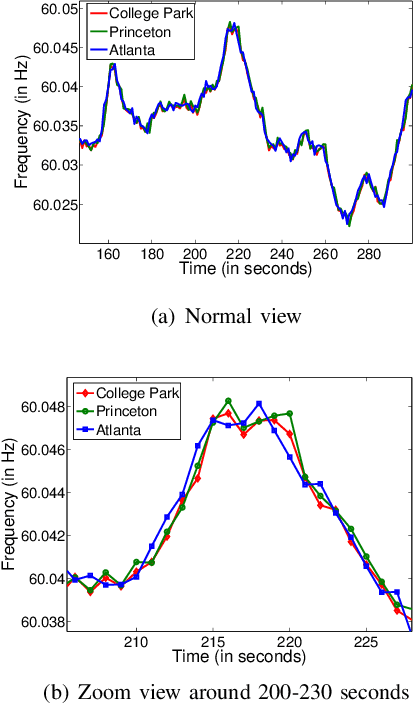
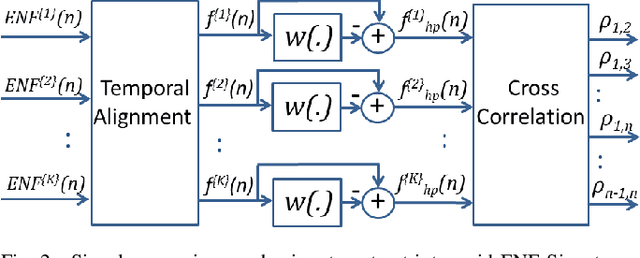
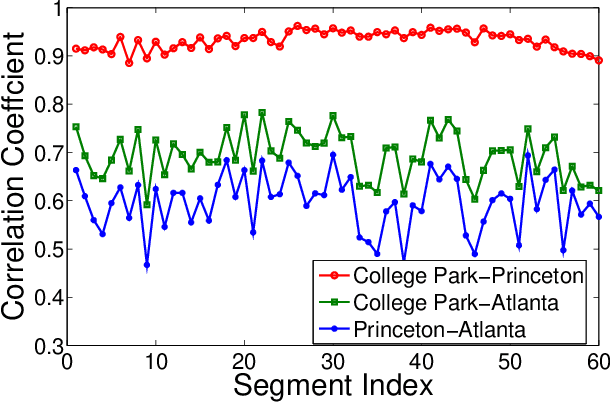
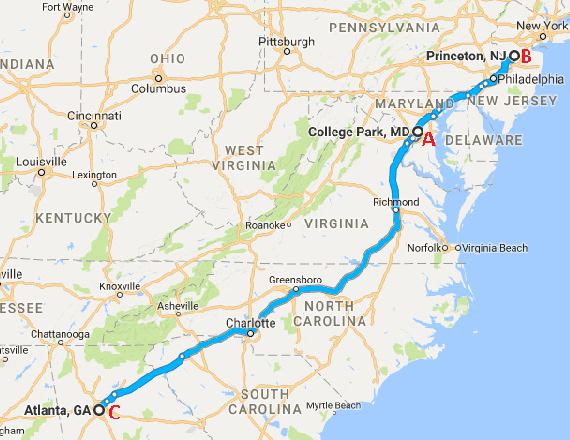
The Electric Network Frequency (ENF) is a signature of power distribution networks that can be captured by multimedia recordings made in areas where there is electrical activity. This has led to an emergence of several forensic applications based on the use of the ENF signature. Examples of such applications include estimating or verifying the time-of-recording of a media signal and inferring the power grid associated with the location in which the media signal was recorded. In this paper, we carry out a feasibility study to examine the possibility of using embedded ENF traces to pinpoint the location-of-recording of a signal within a power grid. In this study, we demonstrate that it is possible to pinpoint the location-of-recording to a certain geographical resolution using power signal recordings containing strong ENF traces. To this purpose, a high-passed version of an ENF signal is extracted and it is demonstrated that the correlation between two such signals, extracted from recordings made in different geographical locations within the same grid, decreases as the distance between the recording locations increases. We harness this property of correlation in the ENF signals to propose trilateration based localization methods, which pinpoint the unknown location of a recording while using some known recording locations as anchor locations. We also discuss the challenges that need to be overcome in order to extend this work to using ENF traces in noisier audio/video recordings for such fine localization purposes.
DF-VO: What Should Be Learnt for Visual Odometry?
Mar 01, 2021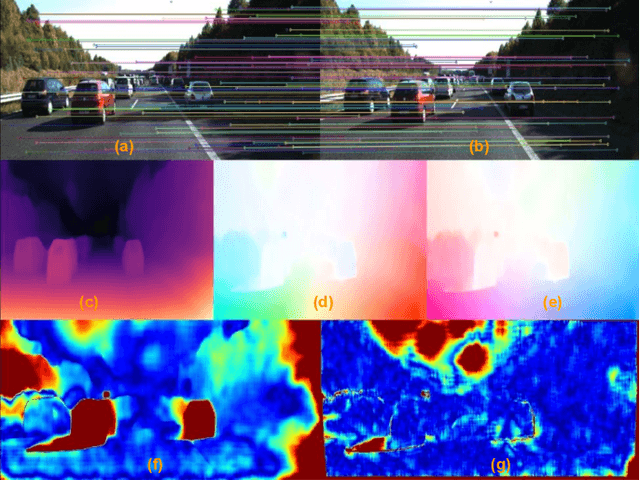
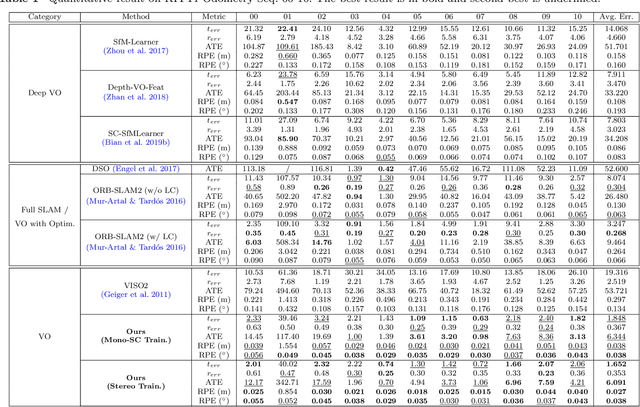
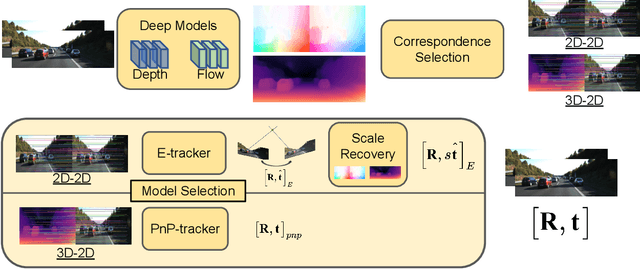

Multi-view geometry-based methods dominate the last few decades in monocular Visual Odometry for their superior performance, while they have been vulnerable to dynamic and low-texture scenes. More importantly, monocular methods suffer from scale-drift issue, i.e., errors accumulate over time. Recent studies show that deep neural networks can learn scene depths and relative camera in a self-supervised manner without acquiring ground truth labels. More surprisingly, they show that the well-trained networks enable scale-consistent predictions over long videos, while the accuracy is still inferior to traditional methods because of ignoring geometric information. Building on top of recent progress in computer vision, we design a simple yet robust VO system by integrating multi-view geometry and deep learning on Depth and optical Flow, namely DF-VO. In this work, a) we propose a method to carefully sample high-quality correspondences from deep flows and recover accurate camera poses with a geometric module; b) we address the scale-drift issue by aligning geometrically triangulated depths to the scale-consistent deep depths, where the dynamic scenes are taken into account. Comprehensive ablation studies show the effectiveness of the proposed method, and extensive evaluation results show the state-of-the-art performance of our system, e.g., Ours (1.652%) v.s. ORB-SLAM (3.247%}) in terms of translation error in KITTI Odometry benchmark. Source code is publicly available at: \href{https://github.com/Huangying-Zhan/DF-VO}{DF-VO}.
Improved Visual Localization via Graph Smoothing
Nov 07, 2019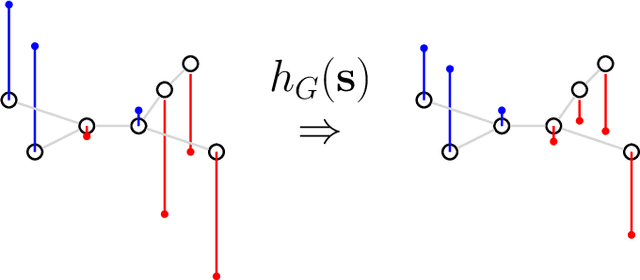
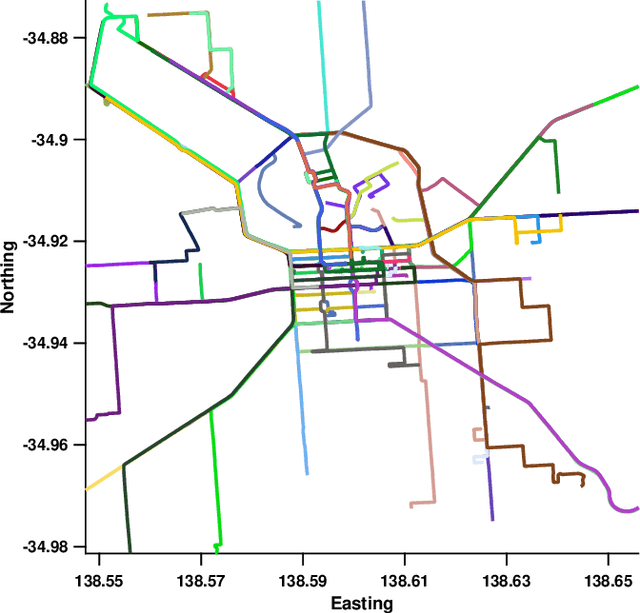
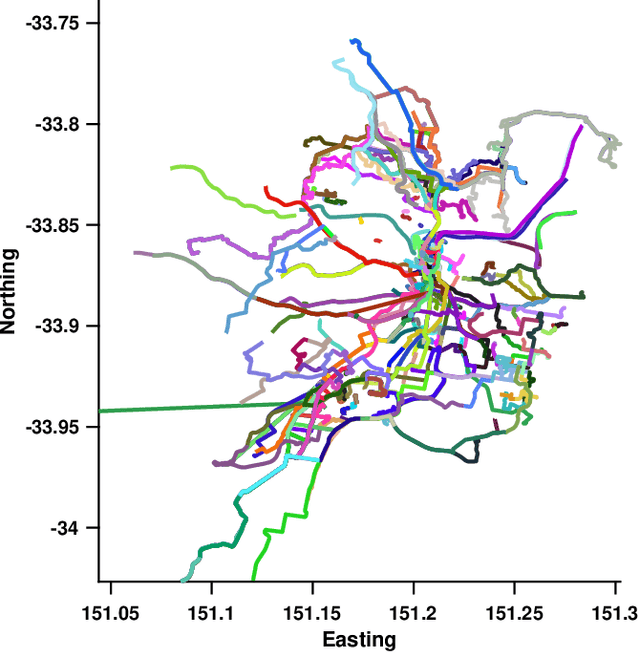
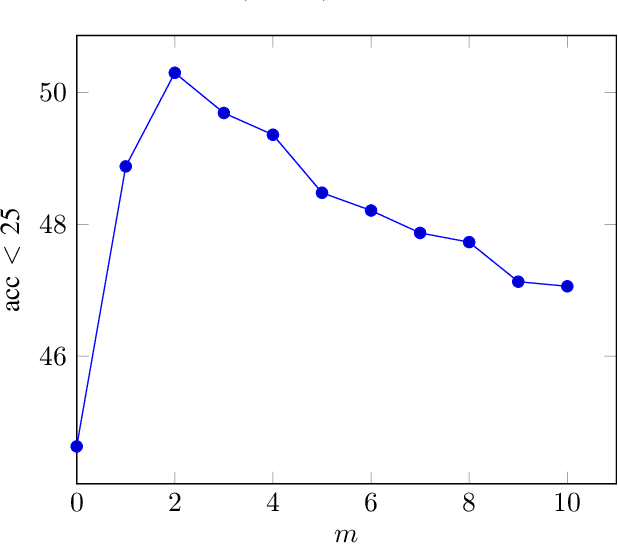
Vision based localization is the problem of inferring the pose of the camera given a single image. One solution to this problem is to learn a deep neural network to infer the pose of a query image after learning on a dataset of images with known poses. Another more commonly used approach rely on image retrieval where the query image is compared against the database of images and its pose is inferred with the help of the retrieved images. The latter approach assumes that images taken from the same places consists of the same landmarks and, thus would have similar feature representations. These representation can be learned using full supervision to be robust to different variations in capture conditions like time of the day and weather. In this work, we introduce a framework to enhance the performance of these retrieval based localization methods by taking into account the additional information including GPS coordinates and temporal neighbourhood of the images provided by the acquisition process in addition to the descriptor similarity of pairs of images in the reference or query database which is used traditionally for localization. Our method constructs a graph based on this additional information and use it for robust retrieval by smoothing the feature representation of reference and/or query images. We show that the proposed method is able to significantly improve the localization accuracy on two large scale datasets over the baselines.
Non-Parametric Priors For Generative Adversarial Networks
May 16, 2019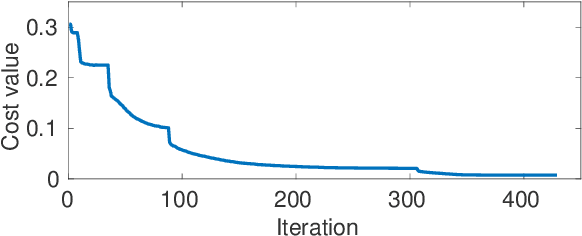

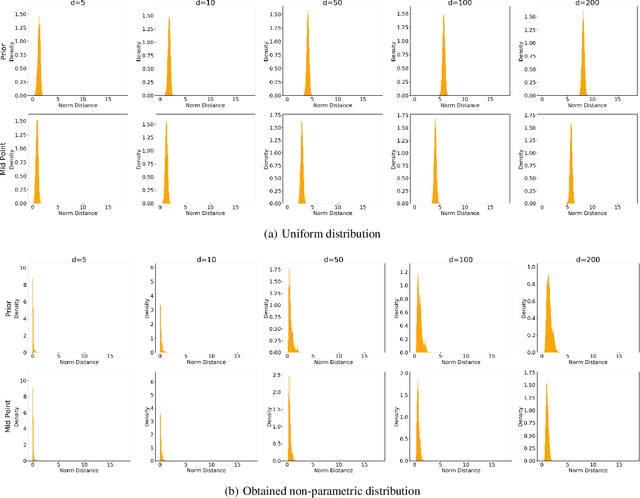
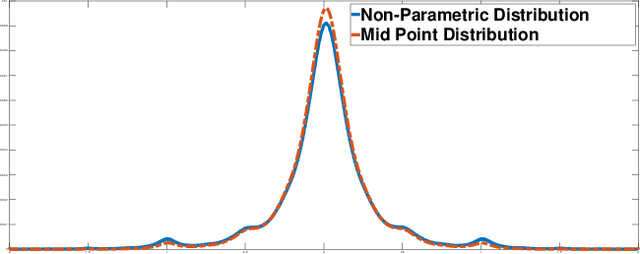
The advent of generative adversarial networks (GAN) has enabled new capabilities in synthesis, interpolation, and data augmentation heretofore considered very challenging. However, one of the common assumptions in most GAN architectures is the assumption of simple parametric latent-space distributions. While easy to implement, a simple latent-space distribution can be problematic for uses such as interpolation. This is due to distributional mismatches when samples are interpolated in the latent space. We present a straightforward formalization of this problem; using basic results from probability theory and off-the-shelf-optimization tools, we develop ways to arrive at appropriate non-parametric priors. The obtained prior exhibits unusual qualitative properties in terms of its shape, and quantitative benefits in terms of lower divergence with its mid-point distribution. We demonstrate that our designed prior helps improve image generation along any Euclidean straight line during interpolation, both qualitatively and quantitatively, without any additional training or architectural modifications. The proposed formulation is quite flexible, paving the way to impose newer constraints on the latent-space statistics.
Self-supervised Learning for Single View Depth and Surface Normal Estimation
Mar 01, 2019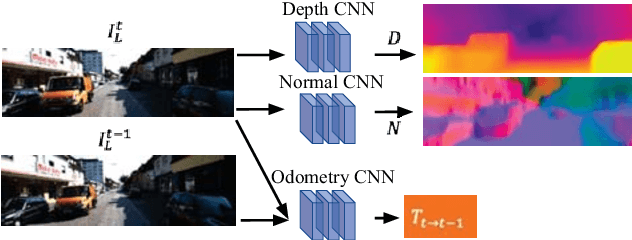
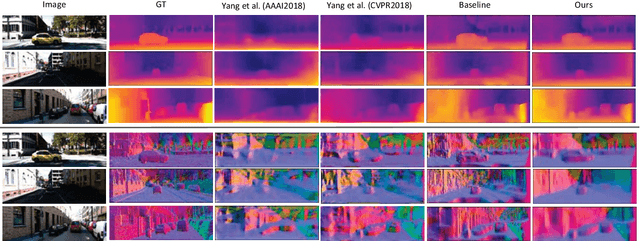
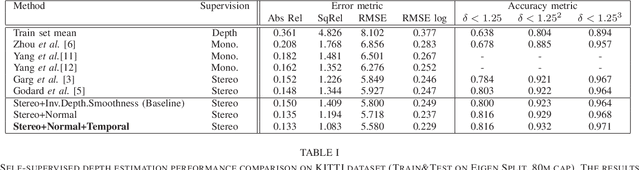
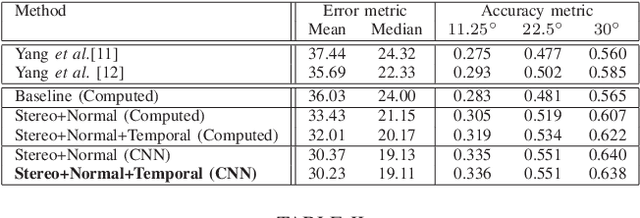
In this work we present a self-supervised learning framework to simultaneously train two Convolutional Neural Networks (CNNs) to predict depth and surface normals from a single image. In contrast to most existing frameworks which represent outdoor scenes as fronto-parallel planes at piece-wise smooth depth, we propose to predict depth with surface orientation while assuming that natural scenes have piece-wise smooth normals. We show that a simple depth-normal consistency as a soft-constraint on the predictions is sufficient and effective for training both these networks simultaneously. The trained normal network provides state-of-the-art predictions while the depth network, relying on much realistic smooth normal assumption, outperforms the traditional self-supervised depth prediction network by a large margin on the KITTI benchmark. Demo video: https://youtu.be/ZD-ZRsw7hdM
Optimizable Object Reconstruction from a Single View
Nov 29, 2018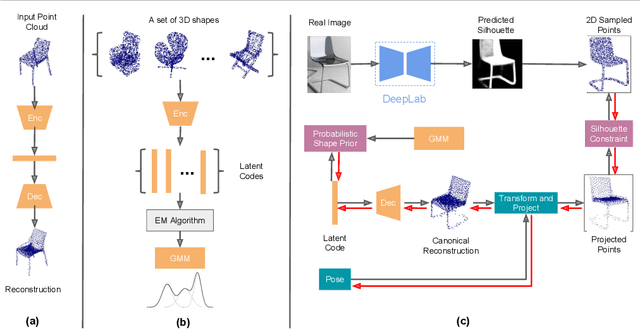
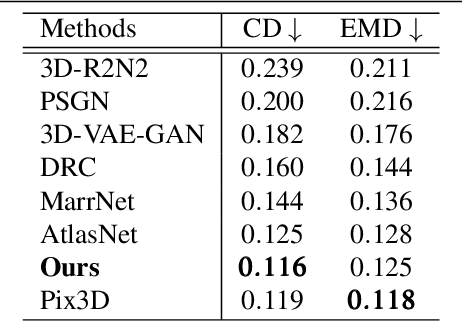

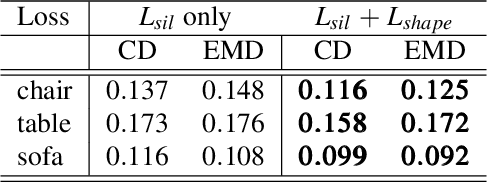
3D shape reconstruction from a single image is a highly ill-posed problem. A number of current deep learning based systems aim to solve the shape reconstruction and shape pose problems by learning an end-to-end network to perform feed-forward inference. More traditional (non-deep learning) methods cast the problem in an iterative optimization framework. In this paper, inspired by these more traditional shape-prior-based approaches, which separate the 2D recognition and 3D reconstruction, we develop a system that leverages the power of both feed-forward and iterative approaches. Our framework uses the power of deep learning to capture 3D shape information from training data and provide high-quality initialization, while allowing both image evidence and shape priors to influence iterative refinement at inference time. Specifically, we employ an auto-encoder to learn a latent space of object shapes, a CNN that maps an image to the latent space, another CNN to predict 2D keypoints to recover object pose using PnP, and a segmentation network to predict an object's silhouette from an RGB image. At inference time these components provide high-quality initial estimates of the shape and pose, which are then further optimized based on the silhouette-shape constraint and a probabilistic shape prior learned on the latent space. Our experiments show that this optimizable inference framework achieves state-of-the-art results on a large benchmarking dataset with real images.