 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic and Consistent Orbital Video Generation via 3D Foundation Priors
Apr 14, 2026We present a novel method for generating geometrically realistic and consistent orbital videos from a single image of an object. Existing video generation works mostly rely on pixel-wise attention to enforce view consistency across frames. However, such mechanism does not impose sufficient constraints for long-range extrapolation, e.g. rear-view synthesis, in which pixel correspondences to the input image are limited. Consequently, these works often fail to produce results with a plausible and coherent structure. To tackle this issue, we propose to leverage rich shape priors from a 3D foundational generative model as an auxiliary constraint, motivated by its capability of modeling realistic object shape distributions learned from large 3D asset corpora. Specifically, we prompt the video generation with two scales of latent features encoded by the 3D foundation model: (i) a denoised global latent vector as an overall structural guidance, and (ii) a set of latent images projected from volumetric features to provide view-dependent and fine-grained geometry details. In contrast to commonly used 2.5D representations such as depth or normal maps, these compact features can model complete object shapes, and help to improve inference efficiency by avoiding explicit mesh extraction. To achieve effective shape conditioning, we introduce a multi-scale 3D adapter to inject feature tokens to the base video model via cross-attention, which retains its capabilities from general video pretraining and enables a simple and model-agonistic fine-tuning process. Extensive experiments on multiple benchmarks show that our method achieves superior visual quality, shape realism and multi-view consistency compared to state-of-the-art methods, and robustly generalizes to complex camera trajectories and in-the-wild images.
Joint Shadow Generation and Relighting via Light-Geometry Interaction Maps
Feb 25, 2026We propose Light-Geometry Interaction (LGI) maps, a novel representation that encodes light-aware occlusion from monocular depth. Unlike ray tracing, which requires full 3D reconstruction, LGI captures essential light-shadow interactions reliably and accurately, computed from off-the-shelf 2.5D depth map predictions. LGI explicitly ties illumination direction to geometry, providing a physics-inspired prior that constrains generative models. Without such prior, these models often produce floating shadows, inconsistent illumination, and implausible shadow geometry. Building on this representation, we propose a unified pipeline for joint shadow generation and relighting - unlike prior methods that treat them as disjoint tasks - capturing the intrinsic coupling of illumination and shadowing essential for modeling indirect effects. By embedding LGI into a bridge-matching generative backbone, we reduce ambiguity and enforce physically consistent light-shadow reasoning. To enable effective training, we curated the first large-scale benchmark dataset for joint shadow and relighting, covering reflections, transparency, and complex interreflections. Experiments show significant gains in realism and consistency across synthetic and real images. LGI thus bridges geometry-inspired rendering with generative modeling, enabling efficient, physically consistent shadow generation and relighting.
SRSR: Enhancing Semantic Accuracy in Real-World Image Super-Resolution with Spatially Re-Focused Text-Conditioning
Oct 26, 2025Existing diffusion-based super-resolution approaches often exhibit semantic ambiguities due to inaccuracies and incompleteness in their text conditioning, coupled with the inherent tendency for cross-attention to divert towards irrelevant pixels. These limitations can lead to semantic misalignment and hallucinated details in the generated high-resolution outputs. To address these, we propose a novel, plug-and-play spatially re-focused super-resolution (SRSR) framework that consists of two core components: first, we introduce Spatially Re-focused Cross-Attention (SRCA), which refines text conditioning at inference time by applying visually-grounded segmentation masks to guide cross-attention. Second, we introduce a Spatially Targeted Classifier-Free Guidance (STCFG) mechanism that selectively bypasses text influences on ungrounded pixels to prevent hallucinations. Extensive experiments on both synthetic and real-world datasets demonstrate that SRSR consistently outperforms seven state-of-the-art baselines in standard fidelity metrics (PSNR and SSIM) across all datasets, and in perceptual quality measures (LPIPS and DISTS) on two real-world benchmarks, underscoring its effectiveness in achieving both high semantic fidelity and perceptual quality in super-resolution.
Knowledge Combination to Learn Rotated Detection Without Rotated Annotation
Apr 05, 2023



Rotated bounding boxes drastically reduce output ambiguity of elongated objects, making it superior to axis-aligned bounding boxes. Despite the effectiveness, rotated detectors are not widely employed. Annotating rotated bounding boxes is such a laborious process that they are not provided in many detection datasets where axis-aligned annotations are used instead. In this paper, we propose a framework that allows the model to predict precise rotated boxes only requiring cheaper axis-aligned annotation of the target dataset 1. To achieve this, we leverage the fact that neural networks are capable of learning richer representation of the target domain than what is utilized by the task. The under-utilized representation can be exploited to address a more detailed task. Our framework combines task knowledge of an out-of-domain source dataset with stronger annotation and domain knowledge of the target dataset with weaker annotation. A novel assignment process and projection loss are used to enable the co-training on the source and target datasets. As a result, the model is able to solve the more detailed task in the target domain, without additional computation overhead during inference. We extensively evaluate the method on various target datasets including fresh-produce dataset, HRSC2016 and SSDD. Results show that the proposed method consistently performs on par with the fully supervised approach.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022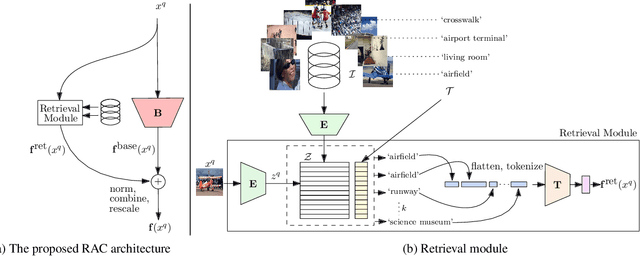
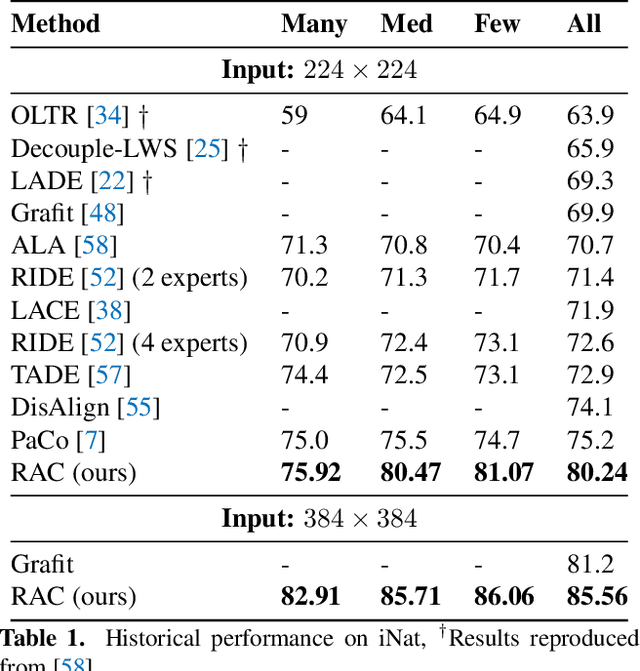
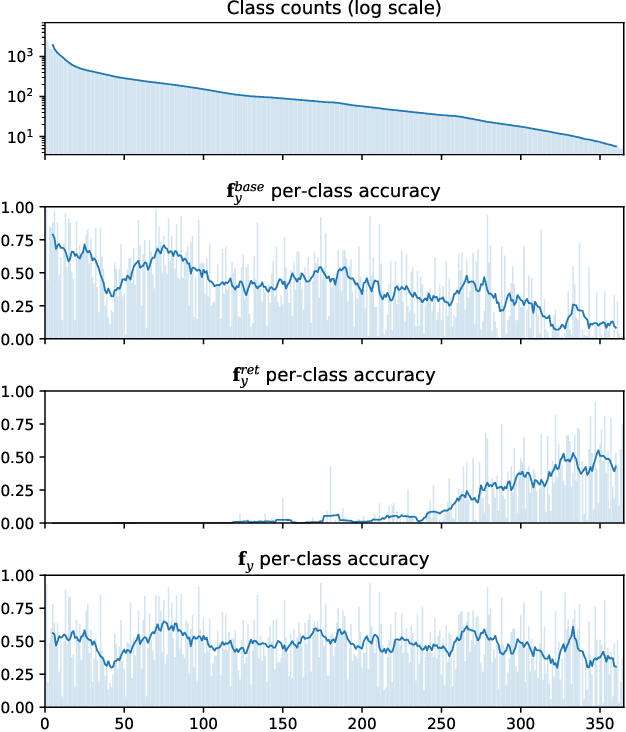
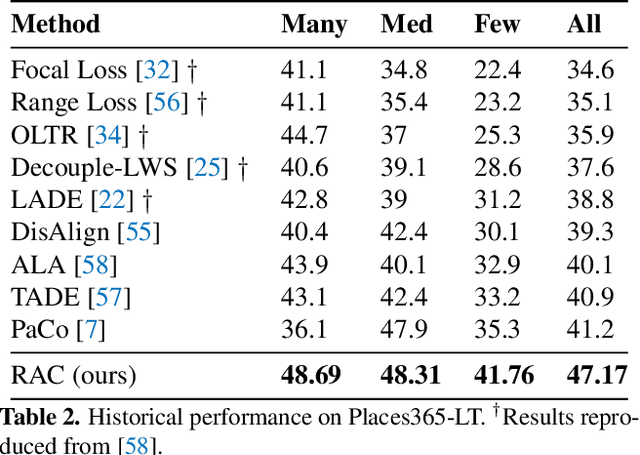
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Learning to generate new indoor scenes
Dec 10, 2019

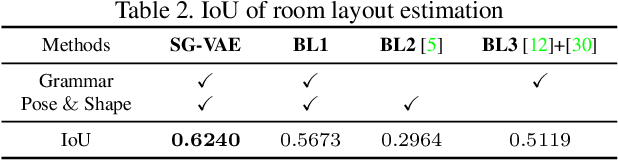
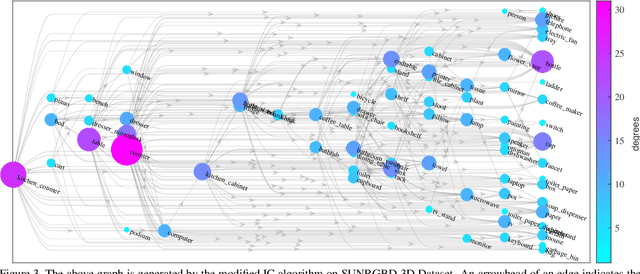
Deep generative models have been used in recent years to learn coherent latent representations in order to synthesize high quality images. In this work we propose a neural network to learn a generative model for sampling consistent indoor scene layouts. Our method learns the co-occurrences, and appearance parameters such as shape and pose, for different objects categories through a grammar-based auto-encoder, resulting in a compact and accurate representation for scene layouts. In contrast to existing grammar-based methods with a user-specified grammar, we construct the grammar automatically by extracting a set of production rules on reasoning about object co-occurrences in training data. The extracted grammar is able to represent a scene by an augmented parse tree. The proposed auto-encoder encodes these parse trees to a latent code, and decodes the latent code to a parse-tree, thereby ensuring the generated scene is always valid. We experimentally demonstrate that the proposed auto-encoder learns not only to generate valid scenes (i.e. the arrangements and appearances of objects), but it also learns coherent latent representations where nearby latent samples decode to similar scene outputs. The obtained generative model is applicable to several computer vision tasks such as 3D pose and layout estimation from RGB-D data.
NeuRoRA: Neural Robust Rotation Averaging
Dec 10, 2019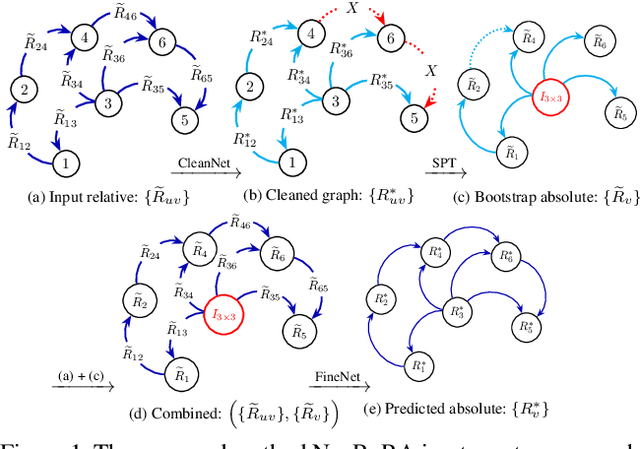
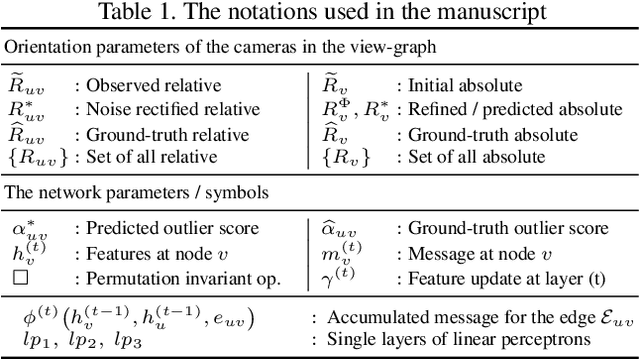
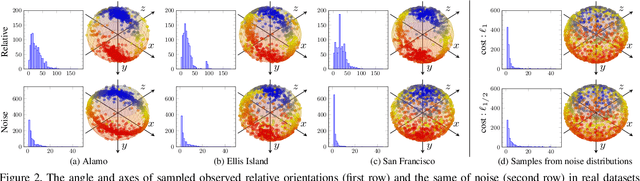
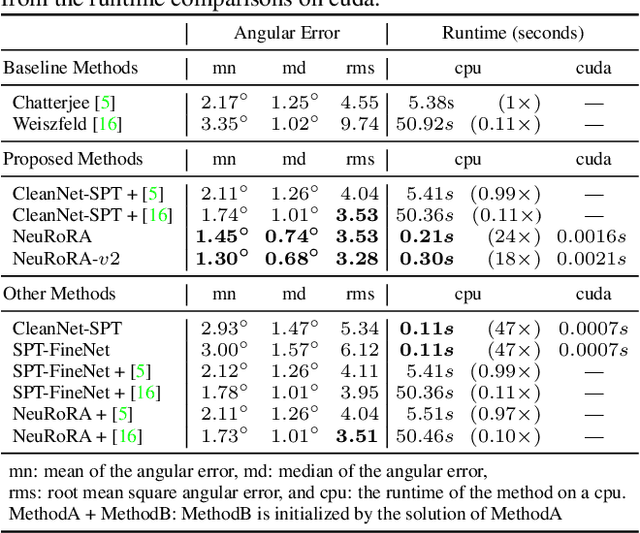
Multiple rotation averaging is an essential task for structure from motion, mapping, and robot navigation. The task is to estimate the absolute orientations of several cameras given some of their noisy relative orientation measurements. The conventional methods for this task seek parameters of the absolute orientations that agree best with the observed noisy measurements according to a robust cost function. These robust cost functions are highly nonlinear and are designed based on certain assumptions about the noise and outlier distributions. In this work, we aim to build a neural network that learns the noise patterns from the data and predict/regress the model parameters from the noisy relative orientations. The proposed network is a combination of two networks: (1) a view-graph cleaning network, which detects outlier edges in the view-graph and rectifies noisy measurements; and (2) a fine-tuning network, which fine-tunes an initialization of absolute orientations bootstrapped from the cleaned graph, in a single step. The proposed combined network is very fast, moreover, being trained on a large number of synthetic graphs, it is more accurate than the conventional iterative optimization methods. Although the idea of replacing robust optimization methods by a graph-based network is demonstrated only for multiple rotation averaging, it could easily be extended to other graph-based geometric problems, for example, pose-graph optimization.
Resolving Marker Pose Ambiguity by Robust Rotation Averaging with Clique Constraints
Sep 26, 2019
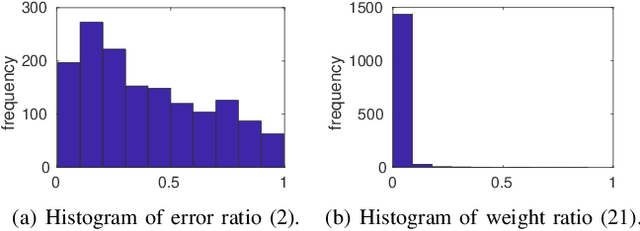
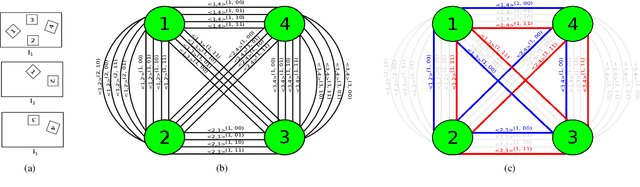

Planar markers are useful in robotics and computer vision for mapping and localisation. Given a detected marker in an image, a frequent task is to estimate the 6DOF pose of the marker relative to the camera, which is an instance of planar pose estimation (PPE). Although there are mature techniques, PPE suffers from a fundamental ambiguity problem, in that there can be more than one plausible pose solutions for a PPE instance. Especially when localisation of the marker corners is noisy, it is often difficult to disambiguate the pose solutions based on reprojection error alone. Previous methods choose between the possible solutions using a heuristic criteria, or simply ignore ambiguous markers. We propose to resolve the ambiguities by examining the consistencies of a set of markers across multiple views. Our specific contributions include a novel rotation averaging formulation that incorporates long-range dependencies between possible marker orientation solutions that arise from PPE ambiguities. We analyse the combinatorial complexity of the problem, and develop a novel lifted algorithm to effectively resolve marker pose ambiguities, without discarding any marker observations. Results on real and synthetic data show that our method is able to handle highly ambiguous inputs, and provides more accurate and/or complete marker-based mapping and localisation.
Seeing Behind Things: Extending Semantic Segmentation to Occluded Regions
Jun 07, 2019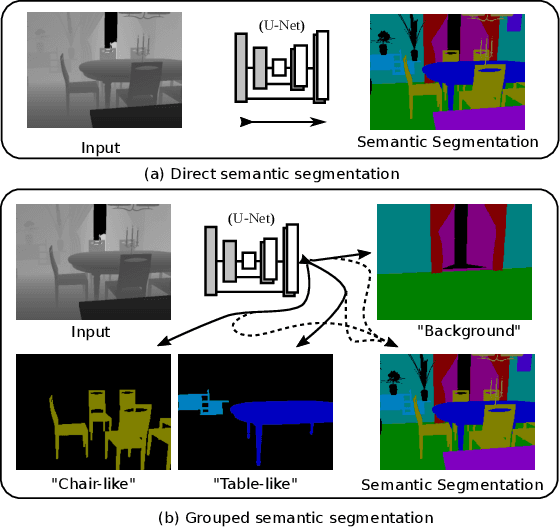

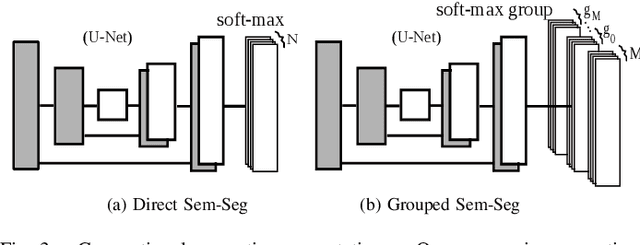

Semantic segmentation and instance level segmentation made substantial progress in recent years due to the emergence of deep neural networks (DNNs). A number of deep architectures with Convolution Neural Networks (CNNs) were proposed that surpass the traditional machine learning approaches for segmentation by a large margin. These architectures predict the directly observable semantic category of each pixel by usually optimizing a cross entropy loss. In this work we push the limit of semantic segmentation towards predicting semantic labels of directly visible as well as occluded objects or objects parts, where the network's input is a single depth image. We group the semantic categories into one background and multiple foreground object groups, and we propose a modification of the standard cross-entropy loss to cope with the settings. In our experiments we demonstrate that a CNN trained by minimizing the proposed loss is able to predict semantic categories for visible and occluded object parts without requiring to increase the network size (compared to a standard segmentation task). The results are validated on a newly generated dataset (augmented from SUNCG) dataset.
Morphological Networks for Image De-raining
Jan 08, 2019

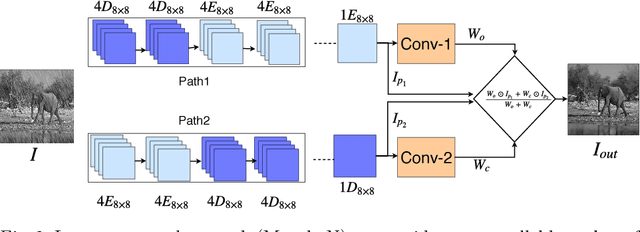

Mathematical morphological methods have successfully been applied to filter out (emphasize or remove) different structures of an image. However, it is argued that these methods could be suitable for the task only if the type and order of the filter(s) as well as the shape and size of operator kernel are designed properly. Thus the existing filtering operators are problem (instance) specific and are designed by the domain experts. In this work we propose a morphological network that emulates classical morphological filtering consisting of a series of erosion and dilation operators with trainable structuring elements. We evaluate the proposed network for image de-raining task where the SSIM and mean absolute error (MAE) loss corresponding to predicted and ground-truth clean image is back-propagated through the network to train the structuring elements. We observe that a single morphological network can de-rain an image with any arbitrary shaped rain-droplets and achieves similar performance with the contemporary CNNs for this task with a fraction of trainable parameters (network size). The proposed morphological network(MorphoN) is not designed specifically for de-raining and can readily be applied to similar filtering / noise cleaning tasks. The source code can be found here https://github.com/ranjanZ/2D-Morphological-Network
* Mathematical Morphology \and Optimization \and Morphological Network \and Image Filtering