 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention and Pooling based Sigmoid Colon Segmentation in 3D CT images
Sep 25, 2023



Segmentation of the sigmoid colon is a crucial aspect of treating diverticulitis. It enables accurate identification and localisation of inflammation, which in turn helps healthcare professionals make informed decisions about the most appropriate treatment options. This research presents a novel deep learning architecture for segmenting the sigmoid colon from Computed Tomography (CT) images using a modified 3D U-Net architecture. Several variations of the 3D U-Net model with modified hyper-parameters were examined in this study. Pyramid pooling (PyP) and channel-spatial Squeeze and Excitation (csSE) were also used to improve the model performance. The networks were trained using manually annotated sigmoid colon. A five-fold cross-validation procedure was used on a test dataset to evaluate the network's performance. As indicated by the maximum Dice similarity coefficient (DSC) of 56.92+/-1.42%, the application of PyP and csSE techniques improves segmentation precision. We explored ensemble methods including averaging, weighted averaging, majority voting, and max ensemble. The results show that average and majority voting approaches with a threshold value of 0.5 and consistent weight distribution among the top three models produced comparable and optimal results with DSC of 88.11+/-3.52%. The results indicate that the application of a modified 3D U-Net architecture is effective for segmenting the sigmoid colon in Computed Tomography (CT) images. In addition, the study highlights the potential benefits of integrating ensemble methods to improve segmentation precision.
PhishSim: Aiding Phishing Website Detection with a Feature-Free Tool
Jul 13, 2022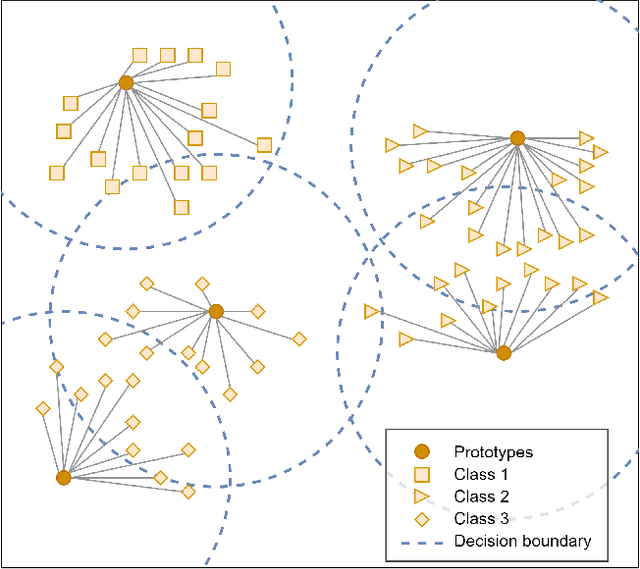

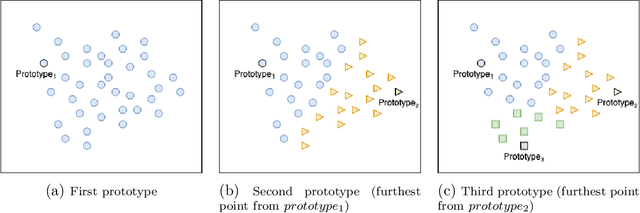
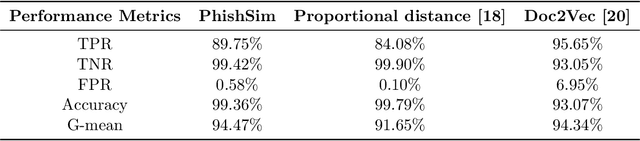
In this paper, we propose a feature-free method for detecting phishing websites using the Normalized Compression Distance (NCD), a parameter-free similarity measure which computes the similarity of two websites by compressing them, thus eliminating the need to perform any feature extraction. It also removes any dependence on a specific set of website features. This method examines the HTML of webpages and computes their similarity with known phishing websites, in order to classify them. We use the Furthest Point First algorithm to perform phishing prototype extractions, in order to select instances that are representative of a cluster of phishing webpages. We also introduce the use of an incremental learning algorithm as a framework for continuous and adaptive detection without extracting new features when concept drift occurs. On a large dataset, our proposed method significantly outperforms previous methods in detecting phishing websites, with an AUC score of 98.68%, a high true positive rate (TPR) of around 90%, while maintaining a low false positive rate (FPR) of 0.58%. Our approach uses prototypes, eliminating the need to retain long term data in the future, and is feasible to deploy in real systems with a processing time of roughly 0.3 seconds.
* 34 pages, 20 figures
Fast and Data Efficient Reinforcement Learning from Pixels via Non-Parametric Value Approximation
Mar 07, 2022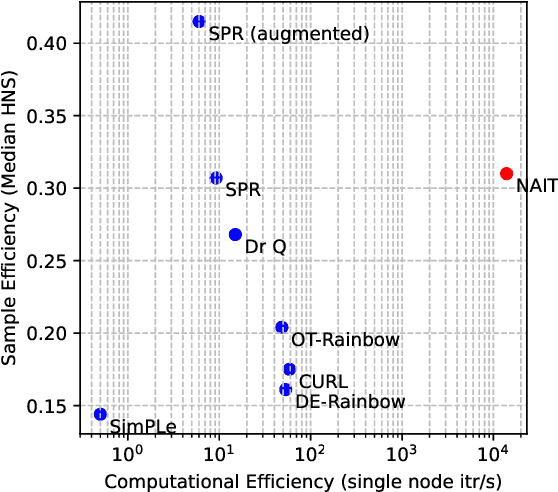
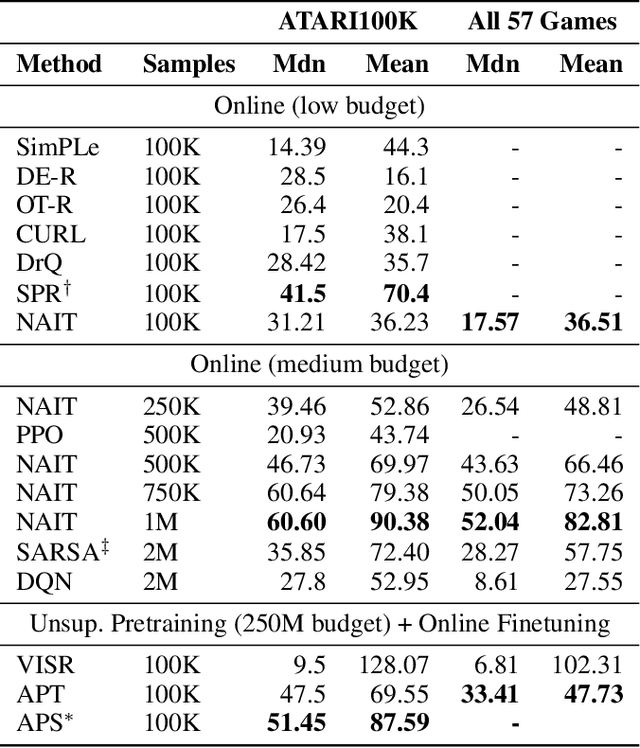
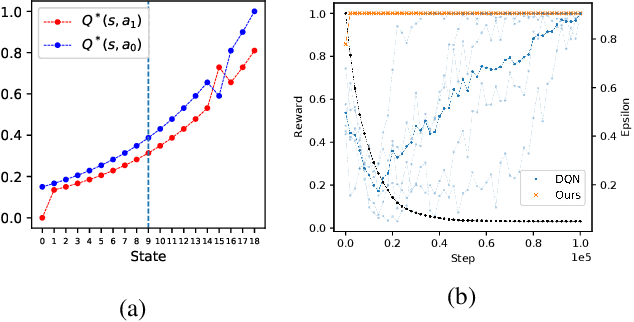
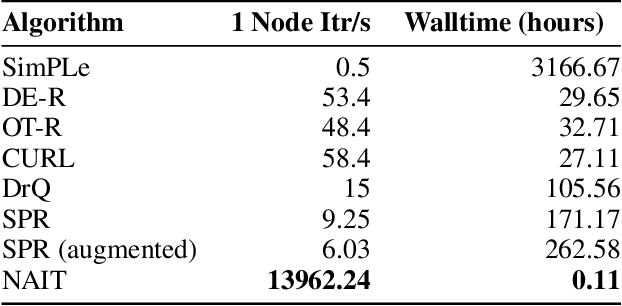
We present Nonparametric Approximation of Inter-Trace returns (NAIT), a Reinforcement Learning algorithm for discrete action, pixel-based environments that is both highly sample and computation efficient. NAIT is a lazy-learning approach with an update that is equivalent to episodic Monte-Carlo on episode completion, but that allows the stable incorporation of rewards while an episode is ongoing. We make use of a fixed domain-agnostic representation, simple distance based exploration and a proximity graph-based lookup to facilitate extremely fast execution. We empirically evaluate NAIT on both the 26 and 57 game variants of ATARI100k where, despite its simplicity, it achieves competitive performance in the online setting with greater than 100x speedup in wall-time.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022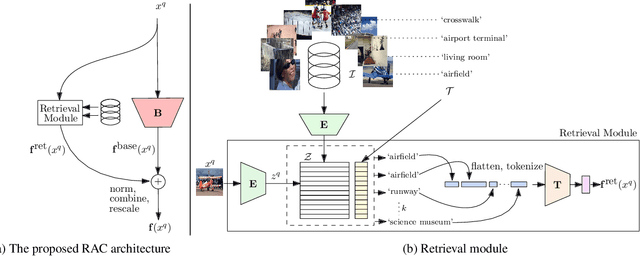
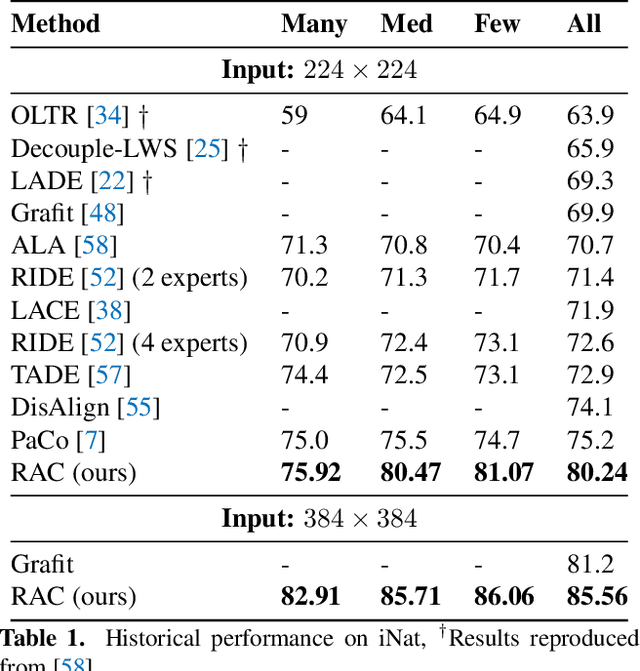
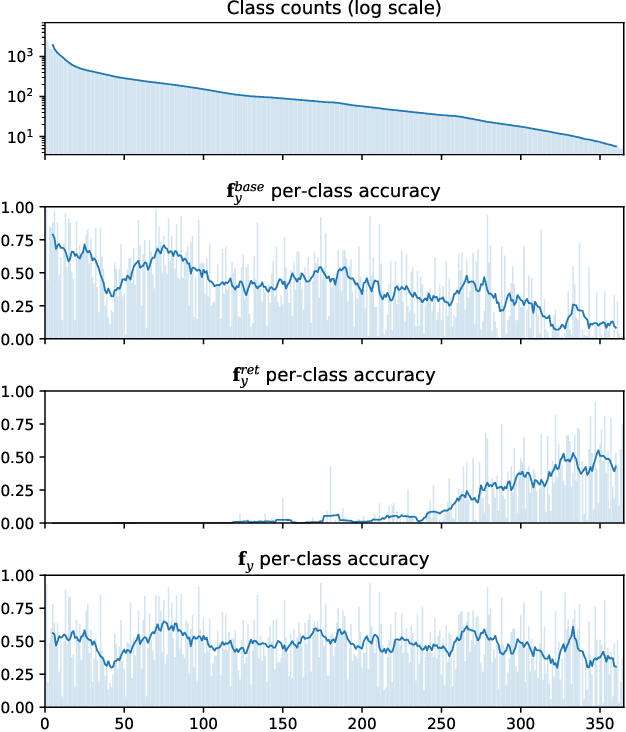
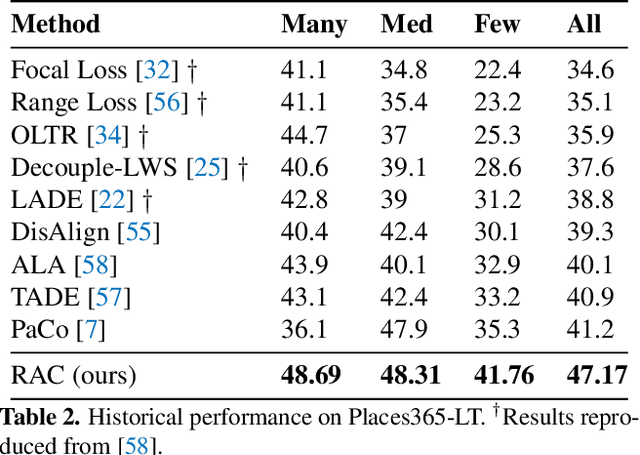
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Organ localisation using supervised and semi supervised approaches combining reinforcement learning with imitation learning
Dec 06, 2021
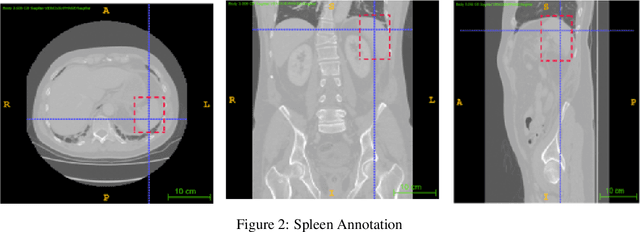
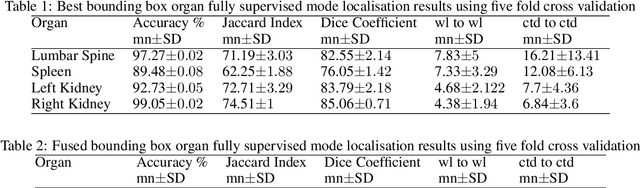
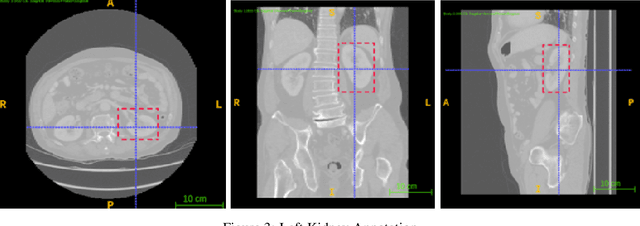
Computer aided diagnostics often requires analysis of a region of interest (ROI) within a radiology scan, and the ROI may be an organ or a suborgan. Although deep learning algorithms have the ability to outperform other methods, they rely on the availability of a large amount of annotated data. Motivated by the need to address this limitation, an approach to localisation and detection of multiple organs based on supervised and semi-supervised learning is presented here. It draws upon previous work by the authors on localising the thoracic and lumbar spine region in CT images. The method generates six bounding boxes of organs of interest, which are then fused to a single bounding box. The results of experiments on localisation of the Spleen, Left and Right Kidneys in CT Images using supervised and semi supervised learning (SSL) demonstrate the ability to address data limitations with a much smaller data set and fewer annotations, compared to other state-of-the-art methods. The SSL performance was evaluated using three different mixes of labelled and unlabelled data (i.e.30:70,35:65,40:60) for each of lumbar spine, spleen left and right kidneys respectively. The results indicate that SSL provides a workable alternative especially in medical imaging where it is difficult to obtain annotated data.
Man versus Machine: AutoML and Human Experts' Role in Phishing Detection
Aug 27, 2021
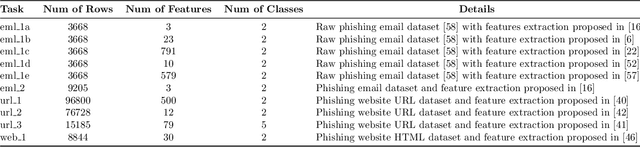


Machine learning (ML) has developed rapidly in the past few years and has successfully been utilized for a broad range of tasks, including phishing detection. However, building an effective ML-based detection system is not a trivial task, and requires data scientists with knowledge of the relevant domain. Automated Machine Learning (AutoML) frameworks have received a lot of attention in recent years, enabling non-ML experts in building a machine learning model. This brings to an intriguing question of whether AutoML can outperform the results achieved by human data scientists. Our paper compares the performances of six well-known, state-of-the-art AutoML frameworks on ten different phishing datasets to see whether AutoML-based models can outperform manually crafted machine learning models. Our results indicate that AutoML-based models are able to outperform manually developed machine learning models in complex classification tasks, specifically in datasets where the features are not quite discriminative, and datasets with overlapping classes or relatively high degrees of non-linearity. Challenges also remain in building a real-world phishing detection system using AutoML frameworks due to the current support only on supervised classification problems, leading to the need for labeled data, and the inability to update the AutoML-based models incrementally. This indicates that experts with knowledge in the domain of phishing and cybersecurity are still essential in the loop of the phishing detection pipeline.
Eccentric Regularization: Minimizing Hyperspherical Energy without explicit projection
Apr 23, 2021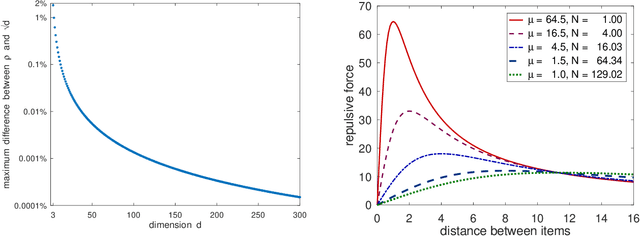
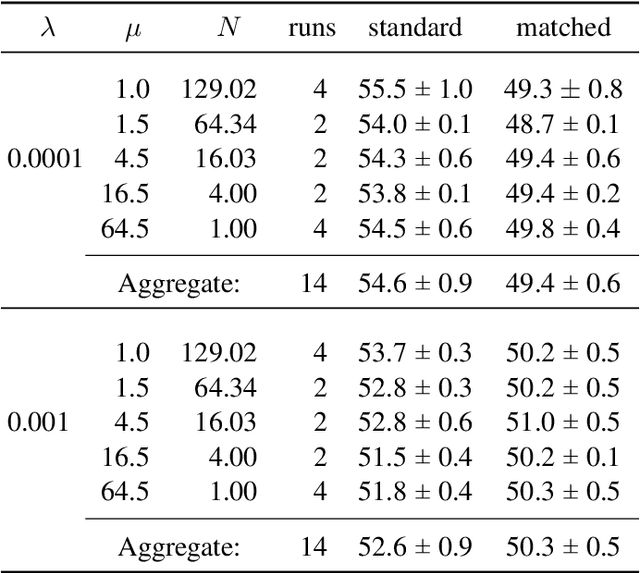
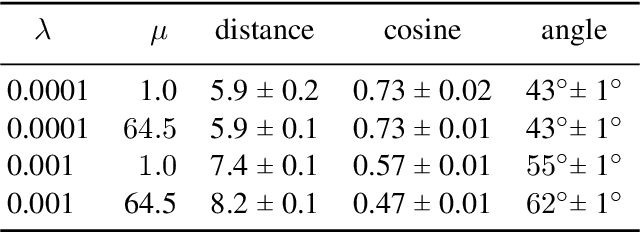
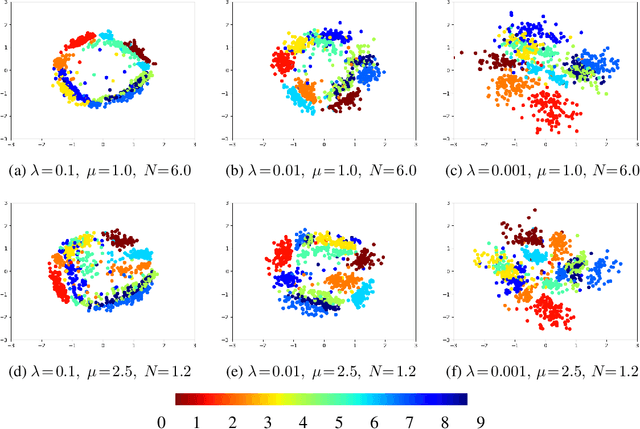
Several regularization methods have recently been introduced which force the latent activations of an autoencoder or deep neural network to conform to either a Gaussian or hyperspherical distribution, or to minimize the implicit rank of the distribution in latent space. In the present work, we introduce a novel regularizing loss function which simulates a pairwise repulsive force between items and an attractive force of each item toward the origin. We show that minimizing this loss function in isolation achieves a hyperspherical distribution. Moreover, when used as a regularizing term, the scaling factor can be adjusted to allow greater flexibility and tolerance of eccentricity, thus allowing the latent variables to be stratified according to their relative importance, while still promoting diversity. We apply this method of Eccentric Regularization to an autoencoder, and demonstrate its effectiveness in image generation, representation learning and downstream classification tasks.
Epigenetic evolution of deep convolutional models
Apr 12, 2021
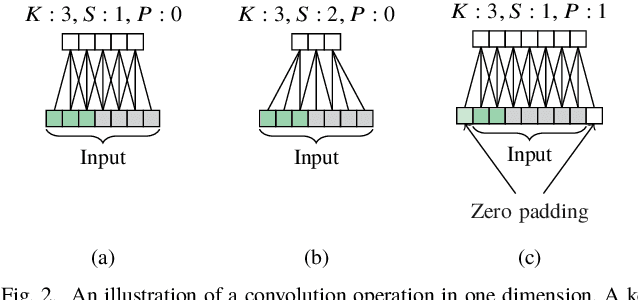

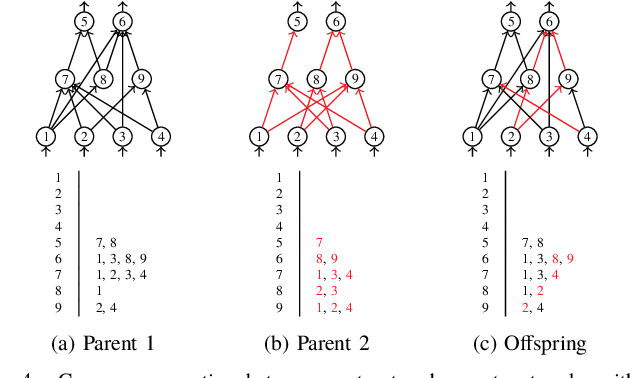
In this study, we build upon a previously proposed neuroevolution framework to evolve deep convolutional models. Specifically, the genome encoding and the crossover operator are extended to make them applicable to layered networks. We also propose a convolutional layer layout which allows kernels of different shapes and sizes to coexist within the same layer, and present an argument as to why this may be beneficial. The proposed layout enables the size and shape of individual kernels within a convolutional layer to be evolved with a corresponding new mutation operator. The proposed framework employs a hybrid optimisation strategy involving structural changes through epigenetic evolution and weight update through backpropagation in a population-based setting. Experiments on several image classification benchmarks demonstrate that the crossover operator is sufficiently robust to produce increasingly performant offspring even when the parents are trained on only a small random subset of the training dataset in each epoch, thus providing direct confirmation that learned features and behaviour can be successfully transferred from parent networks to offspring in the next generation.
* 8 pages
Simeon -- Secure Federated Machine Learning Through Iterative Filtering
Mar 13, 2021
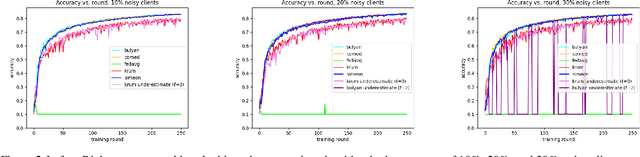


Federated learning enables a global machine learning model to be trained collaboratively by distributed, mutually non-trusting learning agents who desire to maintain the privacy of their training data and their hardware. A global model is distributed to clients, who perform training, and submit their newly-trained model to be aggregated into a superior model. However, federated learning systems are vulnerable to interference from malicious learning agents who may desire to prevent training or induce targeted misclassification in the resulting global model. A class of Byzantine-tolerant aggregation algorithms has emerged, offering varying degrees of robustness against these attacks, often with the caveat that the number of attackers is bounded by some quantity known prior to training. This paper presents Simeon: a novel approach to aggregation that applies a reputation-based iterative filtering technique to achieve robustness even in the presence of attackers who can exhibit arbitrary behaviour. We compare Simeon to state-of-the-art aggregation techniques and find that Simeon achieves comparable or superior robustness to a variety of attacks. Notably, we show that Simeon is tolerant to sybil attacks, where other algorithms are not, presenting a key advantage of our approach.
Complexity-based speciation and genotype representation for neuroevolution
Oct 11, 2020

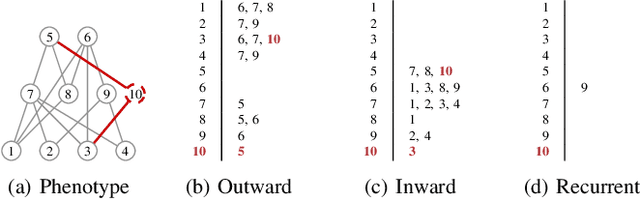
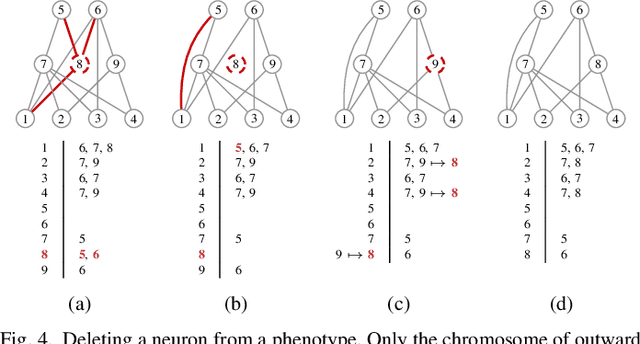
This paper introduces a speciation principle for neuroevolution where evolving networks are grouped into species based on the number of hidden neurons, which is indicative of the complexity of the search space. This speciation principle is indivisibly coupled with a novel genotype representation which is characterised by zero genome redundancy, high resilience to bloat, explicit marking of recurrent connections, as well as an efficient and reproducible stack-based evaluation procedure for networks with arbitrary topology. Furthermore, the proposed speciation principle is employed in several techniques designed to promote and preserve diversity within species and in the ecosystem as a whole. The competitive performance of the proposed framework, named Cortex, is demonstrated through experiments. A highly customisable software platform which implements the concepts proposed in this study is also introduced in the hope that it will serve as a useful and reliable tool for experimentation in the field of neuroevolution.