 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhishSim: Aiding Phishing Website Detection with a Feature-Free Tool
Jul 13, 2022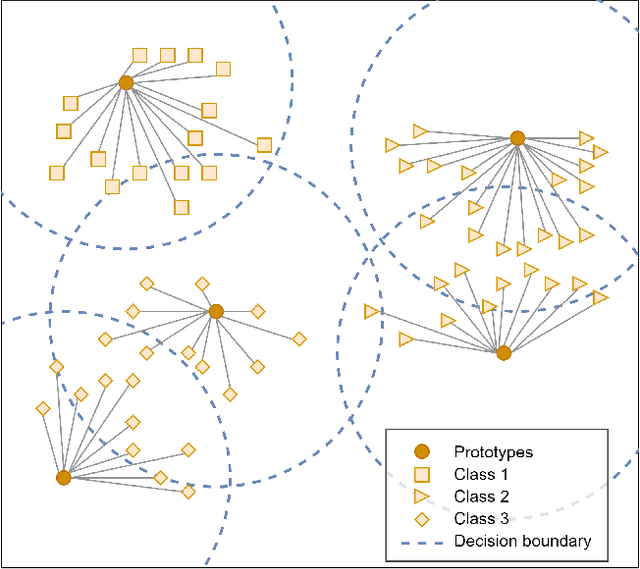

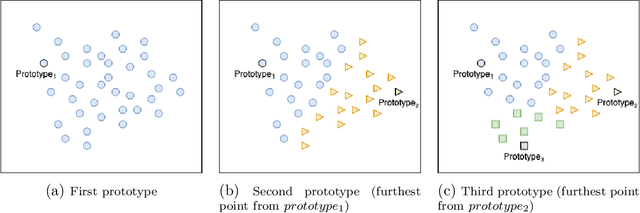
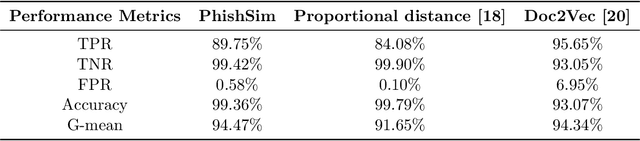
In this paper, we propose a feature-free method for detecting phishing websites using the Normalized Compression Distance (NCD), a parameter-free similarity measure which computes the similarity of two websites by compressing them, thus eliminating the need to perform any feature extraction. It also removes any dependence on a specific set of website features. This method examines the HTML of webpages and computes their similarity with known phishing websites, in order to classify them. We use the Furthest Point First algorithm to perform phishing prototype extractions, in order to select instances that are representative of a cluster of phishing webpages. We also introduce the use of an incremental learning algorithm as a framework for continuous and adaptive detection without extracting new features when concept drift occurs. On a large dataset, our proposed method significantly outperforms previous methods in detecting phishing websites, with an AUC score of 98.68%, a high true positive rate (TPR) of around 90%, while maintaining a low false positive rate (FPR) of 0.58%. Our approach uses prototypes, eliminating the need to retain long term data in the future, and is feasible to deploy in real systems with a processing time of roughly 0.3 seconds.
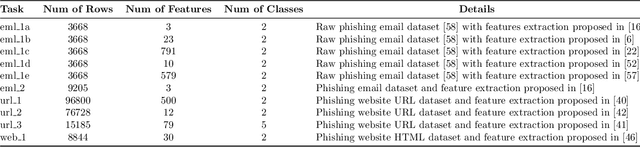
* 34 pages, 20 figures
Man versus Machine: AutoML and Human Experts' Role in Phishing Detection
Aug 27, 2021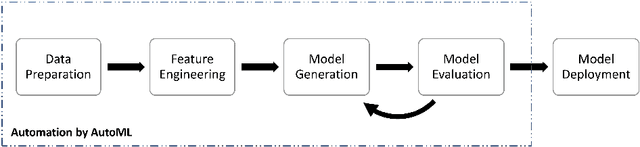


Machine learning (ML) has developed rapidly in the past few years and has successfully been utilized for a broad range of tasks, including phishing detection. However, building an effective ML-based detection system is not a trivial task, and requires data scientists with knowledge of the relevant domain. Automated Machine Learning (AutoML) frameworks have received a lot of attention in recent years, enabling non-ML experts in building a machine learning model. This brings to an intriguing question of whether AutoML can outperform the results achieved by human data scientists. Our paper compares the performances of six well-known, state-of-the-art AutoML frameworks on ten different phishing datasets to see whether AutoML-based models can outperform manually crafted machine learning models. Our results indicate that AutoML-based models are able to outperform manually developed machine learning models in complex classification tasks, specifically in datasets where the features are not quite discriminative, and datasets with overlapping classes or relatively high degrees of non-linearity. Challenges also remain in building a real-world phishing detection system using AutoML frameworks due to the current support only on supervised classification problems, leading to the need for labeled data, and the inability to update the AutoML-based models incrementally. This indicates that experts with knowledge in the domain of phishing and cybersecurity are still essential in the loop of the phishing detection pipeline.
PhishZip: A New Compression-based Algorithm for Detecting Phishing Websites
Jul 22, 2020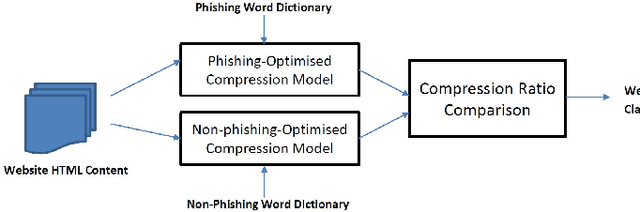
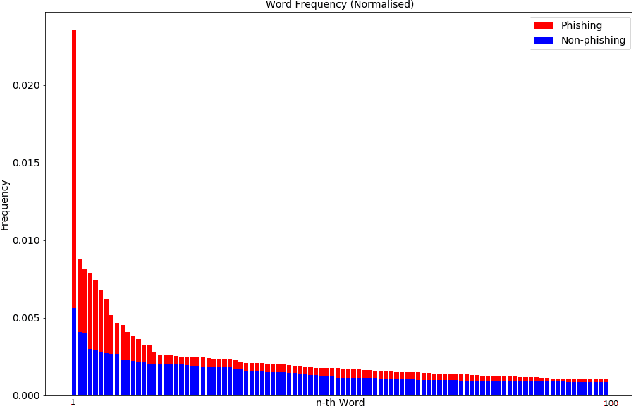
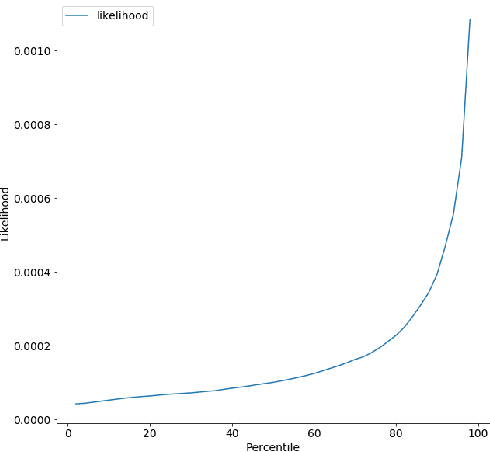
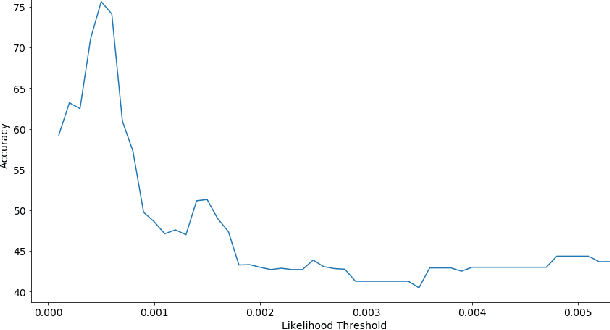
Phishing has grown significantly in the past few years and is predicted to further increase in the future. The dynamics of phishing introduce challenges in implementing a robust phishing detection system and selecting features which can represent phishing despite the change of attack. In this paper, we propose PhishZip which is a novel phishing detection approach using a compression algorithm to perform website classification and demonstrate a systematic way to construct the word dictionaries for the compression models using word occurrence likelihood analysis. PhishZip outperforms the use of best-performing HTML-based features in past studies, with a true positive rate of 80.04%. We also propose the use of compression ratio as a novel machine learning feature which significantly improves machine learning based phishing detection over previous studies. Using compression ratios as additional features, the true positive rate significantly improves by 30.3% (from 51.47% to 81.77%), while the accuracy increases by 11.84% (from 71.20% to 83.04%).