 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Society-Inspired Approaches to Agentic AI Security: The 4C Framework
Feb 02, 2026AI is moving from domain-specific autonomy in closed, predictable settings to large-language-model-driven agents that plan and act in open, cross-organizational environments. As a result, the cybersecurity risk landscape is changing in fundamental ways. Agentic AI systems can plan, act, collaborate, and persist over time, functioning as participants in complex socio-technical ecosystems rather than as isolated software components. Although recent work has strengthened defenses against model and pipeline level vulnerabilities such as prompt injection, data poisoning, and tool misuse, these system centric approaches may fail to capture risks that arise from autonomy, interaction, and emergent behavior. This article introduces the 4C Framework for multi-agent AI security, inspired by societal governance. It organizes agentic risks across four interdependent dimensions: Core (system, infrastructure, and environmental integrity), Connection (communication, coordination, and trust), Cognition (belief, goal, and reasoning integrity), and Compliance (ethical, legal, and institutional governance). By shifting AI security from a narrow focus on system-centric protection to the broader preservation of behavioral integrity and intent, the framework complements existing AI security strategies and offers a principled foundation for building agentic AI systems that are trustworthy, governable, and aligned with human values.
Demo: TOSense -- What Did You Just Agree to?
Aug 01, 2025Online services often require users to agree to lengthy and obscure Terms of Service (ToS), leading to information asymmetry and legal risks. This paper proposes TOSense-a Chrome extension that allows users to ask questions about ToS in natural language and get concise answers in real time. The system combines (i) a crawler "tos-crawl" that automatically extracts ToS content, and (ii) a lightweight large language model pipeline: MiniLM for semantic retrieval and BART-encoder for answer relevance verification. To avoid expensive manual annotation, we present a novel Question Answering Evaluation Pipeline (QEP) that generates synthetic questions and verifies the correctness of answers using clustered topic matching. Experiments on five major platforms, Apple, Google, X (formerly Twitter), Microsoft, and Netflix, show the effectiveness of TOSense (with up to 44.5% accuracy) across varying number of topic clusters. During the demonstration, we will showcase TOSense in action. Attendees will be able to experience seamless extraction, interactive question answering, and instant indexing of new sites.
Nosy Layers, Noisy Fixes: Tackling DRAs in Federated Learning Systems using Explainable AI
May 16, 2025Federated Learning (FL) has emerged as a powerful paradigm for collaborative model training while keeping client data decentralized and private. However, it is vulnerable to Data Reconstruction Attacks (DRA) such as "LoKI" and "Robbing the Fed", where malicious models sent from the server to the client can reconstruct sensitive user data. To counter this, we introduce DRArmor, a novel defense mechanism that integrates Explainable AI with targeted detection and mitigation strategies for DRA. Unlike existing defenses that focus on the entire model, DRArmor identifies and addresses the root cause (i.e., malicious layers within the model that send gradients with malicious intent) by analyzing their contribution to the output and detecting inconsistencies in gradient values. Once these malicious layers are identified, DRArmor applies defense techniques such as noise injection, pixelation, and pruning to these layers rather than the whole model, minimizing the attack surface and preserving client data privacy. We evaluate DRArmor's performance against the advanced LoKI attack across diverse datasets, including MNIST, CIFAR-10, CIFAR-100, and ImageNet, in a 200-client FL setup. Our results demonstrate DRArmor's effectiveness in mitigating data leakage, achieving high True Positive and True Negative Rates of 0.910 and 0.890, respectively. Additionally, DRArmor maintains an average accuracy of 87%, effectively protecting client privacy without compromising model performance. Compared to existing defense mechanisms, DRArmor reduces the data leakage rate by 62.5% with datasets containing 500 samples per client.
Adversarially Guided Stateful Defense Against Backdoor Attacks in Federated Deep Learning
Oct 15, 2024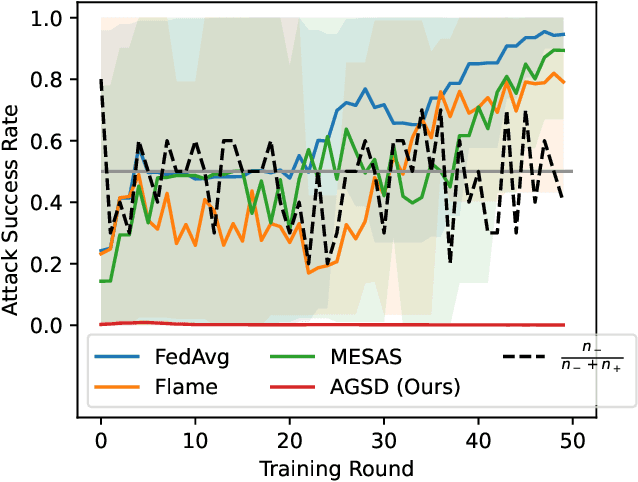
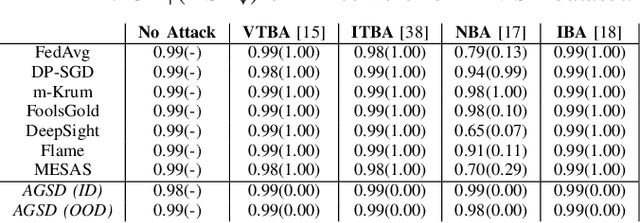
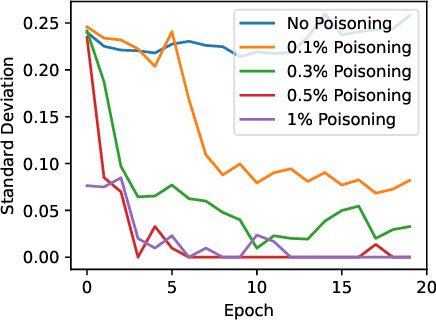
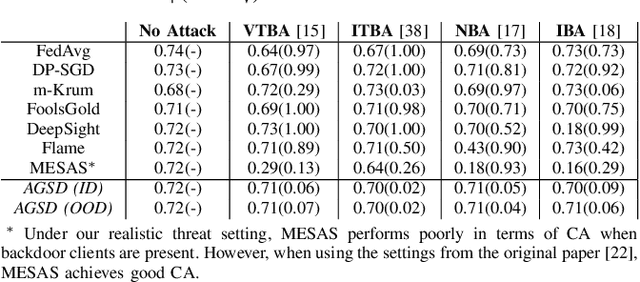
Recent works have shown that Federated Learning (FL) is vulnerable to backdoor attacks. Existing defenses cluster submitted updates from clients and select the best cluster for aggregation. However, they often rely on unrealistic assumptions regarding client submissions and sampled clients population while choosing the best cluster. We show that in realistic FL settings, state-of-the-art (SOTA) defenses struggle to perform well against backdoor attacks in FL. To address this, we highlight that backdoored submissions are adversarially biased and overconfident compared to clean submissions. We, therefore, propose an Adversarially Guided Stateful Defense (AGSD) against backdoor attacks on Deep Neural Networks (DNNs) in FL scenarios. AGSD employs adversarial perturbations to a small held-out dataset to compute a novel metric, called the trust index, that guides the cluster selection without relying on any unrealistic assumptions regarding client submissions. Moreover, AGSD maintains a trust state history of each client that adaptively penalizes backdoored clients and rewards clean clients. In realistic FL settings, where SOTA defenses mostly fail to resist attacks, AGSD mostly outperforms all SOTA defenses with minimal drop in clean accuracy (5% in the worst-case compared to best accuracy) even when (a) given a very small held-out dataset -- typically AGSD assumes 50 samples (<= 0.1% of the training data) and (b) no heldout dataset is available, and out-of-distribution data is used instead. For reproducibility, our code will be openly available at: https://github.com/hassanalikhatim/AGSD.
Examining the Rat in the Tunnel: Interpretable Multi-Label Classification of Tor-based Malware
Sep 25, 2024
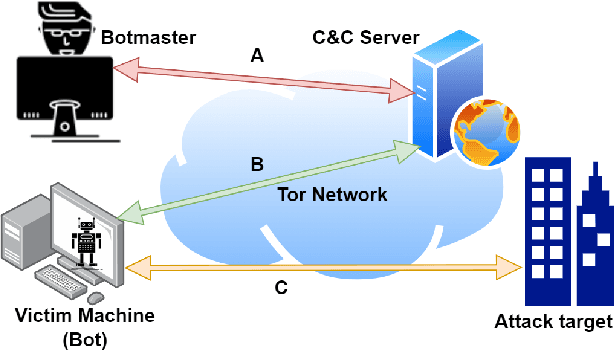
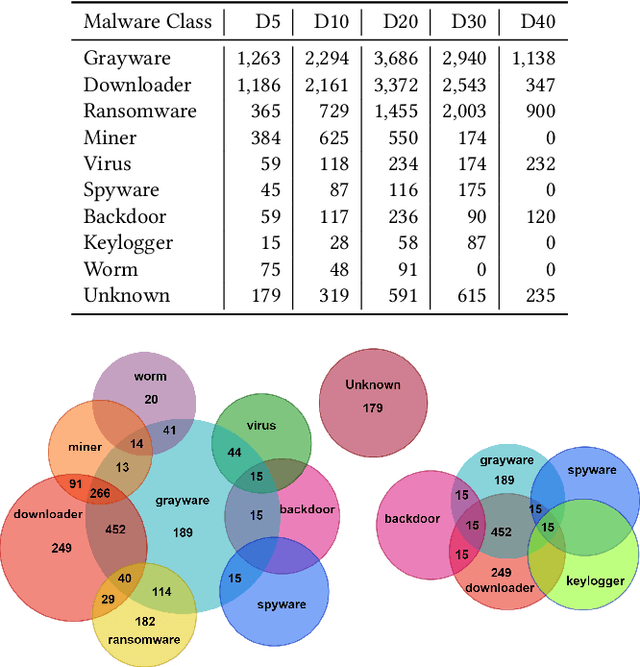

Despite being the most popular privacy-enhancing network, Tor is increasingly adopted by cybercriminals to obfuscate malicious traffic, hindering the identification of malware-related communications between compromised devices and Command and Control (C&C) servers. This malicious traffic can induce congestion and reduce Tor's performance, while encouraging network administrators to block Tor traffic. Recent research, however, demonstrates the potential for accurately classifying captured Tor traffic as malicious or benign. While existing efforts have addressed malware class identification, their performance remains limited, with micro-average precision and recall values around 70%. Accurately classifying specific malware classes is crucial for effective attack prevention and mitigation. Furthermore, understanding the unique patterns and attack vectors employed by different malware classes helps the development of robust and adaptable defence mechanisms. We utilise a multi-label classification technique based on Message-Passing Neural Networks, demonstrating its superiority over previous approaches such as Binary Relevance, Classifier Chains, and Label Powerset, by achieving micro-average precision (MAP) and recall (MAR) exceeding 90%. Compared to previous work, we significantly improve performance by 19.98%, 10.15%, and 59.21% in MAP, MAR, and Hamming Loss, respectively. Next, we employ Explainable Artificial Intelligence (XAI) techniques to interpret the decision-making process within these models. Finally, we assess the robustness of all techniques by crafting adversarial perturbations capable of manipulating classifier predictions and generating false positives and negatives.
AuditNet: A Conversational AI-based Security Assistant [DEMO]
Jul 19, 2024![Figure 1 for AuditNet: A Conversational AI-based Security Assistant [DEMO]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fa16debdf2346773669dd4ce81a2bdea6a20da580%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for AuditNet: A Conversational AI-based Security Assistant [DEMO]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fa16debdf2346773669dd4ce81a2bdea6a20da580%2F4-Figure2-1.png&w=640&q=75)
In the age of information overload, professionals across various fields face the challenge of navigating vast amounts of documentation and ever-evolving standards. Ensuring compliance with standards, regulations, and contractual obligations is a critical yet complex task across various professional fields. We propose a versatile conversational AI assistant framework designed to facilitate compliance checking on the go, in diverse domains, including but not limited to network infrastructure, legal contracts, educational standards, environmental regulations, and government policies. By leveraging retrieval-augmented generation using large language models, our framework automates the review, indexing, and retrieval of relevant, context-aware information, streamlining the process of verifying adherence to established guidelines and requirements. This AI assistant not only reduces the manual effort involved in compliance checks but also enhances accuracy and efficiency, supporting professionals in maintaining high standards of practice and ensuring regulatory compliance in their respective fields. We propose and demonstrate AuditNet, the first conversational AI security assistant designed to assist IoT network security experts by providing instant access to security standards, policies, and regulations.
GLOBE: A High-quality English Corpus with Global Accents for Zero-shot Speaker Adaptive Text-to-Speech
Jun 21, 2024



This paper introduces GLOBE, a high-quality English corpus with worldwide accents, specifically designed to address the limitations of current zero-shot speaker adaptive Text-to-Speech (TTS) systems that exhibit poor generalizability in adapting to speakers with accents. Compared to commonly used English corpora, such as LibriTTS and VCTK, GLOBE is unique in its inclusion of utterances from 23,519 speakers and covers 164 accents worldwide, along with detailed metadata for these speakers. Compared to its original corpus, i.e., Common Voice, GLOBE significantly improves the quality of the speech data through rigorous filtering and enhancement processes, while also populating all missing speaker metadata. The final curated GLOBE corpus includes 535 hours of speech data at a 24 kHz sampling rate. Our benchmark results indicate that the speaker adaptive TTS model trained on the GLOBE corpus can synthesize speech with better speaker similarity and comparable naturalness than that trained on other popular corpora. We will release GLOBE publicly after acceptance. The GLOBE dataset is available at https://globecorpus.github.io/.
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Apr 28, 2024


Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as "instant" and "fine-grained" adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
* 15 pages, 13 figures. Copyright has been transferred to IEEE
Generalizable Zero-Shot Speaker Adaptive Speech Synthesis with Disentangled Representations
Aug 24, 2023While most research into speech synthesis has focused on synthesizing high-quality speech for in-dataset speakers, an equally essential yet unsolved problem is synthesizing speech for unseen speakers who are out-of-dataset with limited reference data, i.e., speaker adaptive speech synthesis. Many studies have proposed zero-shot speaker adaptive text-to-speech and voice conversion approaches aimed at this task. However, most current approaches suffer from the degradation of naturalness and speaker similarity when synthesizing speech for unseen speakers (i.e., speakers not in the training dataset) due to the poor generalizability of the model in out-of-distribution data. To address this problem, we propose GZS-TV, a generalizable zero-shot speaker adaptive text-to-speech and voice conversion model. GZS-TV introduces disentangled representation learning for both speaker embedding extraction and timbre transformation to improve model generalization and leverages the representation learning capability of the variational autoencoder to enhance the speaker encoder. Our experiments demonstrate that GZS-TV reduces performance degradation on unseen speakers and outperforms all baseline models in multiple datasets.
AutoLV: Automatic Lecture Video Generator
Sep 19, 2022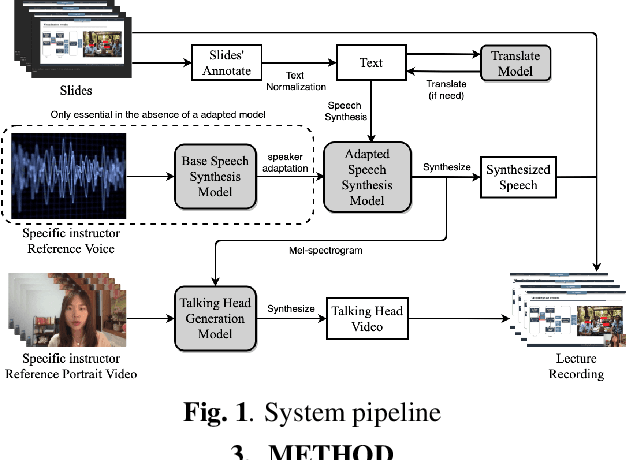
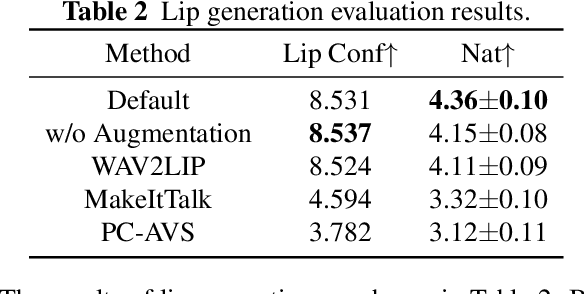


We propose an end-to-end lecture video generation system that can generate realistic and complete lecture videos directly from annotated slides, instructor's reference voice and instructor's reference portrait video. Our system is primarily composed of a speech synthesis module with few-shot speaker adaptation and an adversarial learning-based talking-head generation module. It is capable of not only reducing instructors' workload but also changing the language and accent which can help the students follow the lecture more easily and enable a wider dissemination of lecture contents. Our experimental results show that the proposed model outperforms other current approaches in terms of authenticity, naturalness and accuracy. Here is a video demonstration of how our system works, and the outcomes of the evaluation and comparison: https://youtu.be/cY6TYkI0cog.