 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Case Document Similarity: You Need Both Network and Text
Sep 26, 2022
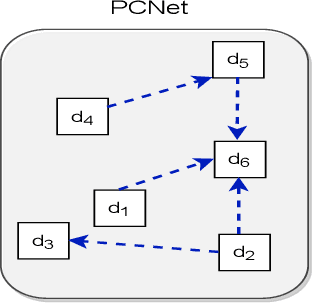

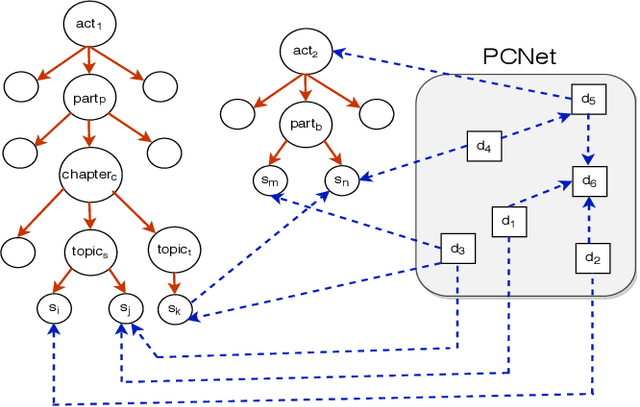
Estimating the similarity between two legal case documents is an important and challenging problem, having various downstream applications such as prior-case retrieval and citation recommendation. There are two broad approaches for the task -- citation network-based and text-based. Prior citation network-based approaches consider citations only to prior-cases (also called precedents) (PCNet). This approach misses important signals inherent in Statutes (written laws of a jurisdiction). In this work, we propose Hier-SPCNet that augments PCNet with a heterogeneous network of Statutes. We incorporate domain knowledge for legal document similarity into Hier-SPCNet, thereby obtaining state-of-the-art results for network-based legal document similarity. Both textual and network similarity provide important signals for legal case similarity; but till now, only trivial attempts have been made to unify the two signals. In this work, we apply several methods for combining textual and network information for estimating legal case similarity. We perform extensive experiments over legal case documents from the Indian judiciary, where the gold standard similarity between document-pairs is judged by law experts from two reputed Law institutes in India. Our experiments establish that our proposed network-based methods significantly improve the correlation with domain experts' opinion when compared to the existing methods for network-based legal document similarity. Our best-performing combination method (that combines network-based and text-based similarity) improves the correlation with domain experts' opinion by 11.8% over the best text-based method and 20.6\% over the best network-based method. We also establish that our best-performing method can be used to recommend / retrieve citable and similar cases for a source (query) case, which are well appreciated by legal experts.
Task Allocation using a Team of Robots
Jul 20, 2022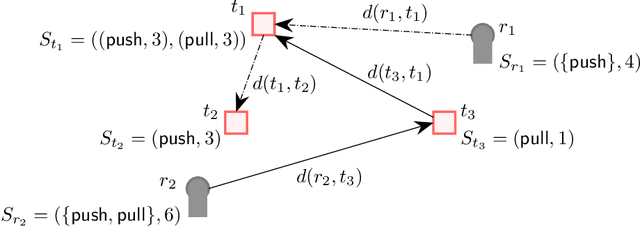
Task allocation using a team or coalition of robots is one of the most important problems in robotics, computer science, operational research, and artificial intelligence. In recent work, research has focused on handling complex objectives and feasibility constraints amongst other variations of the multi-robot task allocation problem. There are many examples of important research progress in these directions. We present a general formulation of the task allocation problem that generalizes several versions that are well-studied. Our formulation includes the states of robots, tasks, and the surrounding environment in which they operate. We describe how the problem can vary depending on the feasibility constraints, objective functions, and the level of dynamically changing information. In addition, we discuss existing solution approaches for the problem including optimization-based approaches, and market-based approaches.
PhishSim: Aiding Phishing Website Detection with a Feature-Free Tool
Jul 13, 2022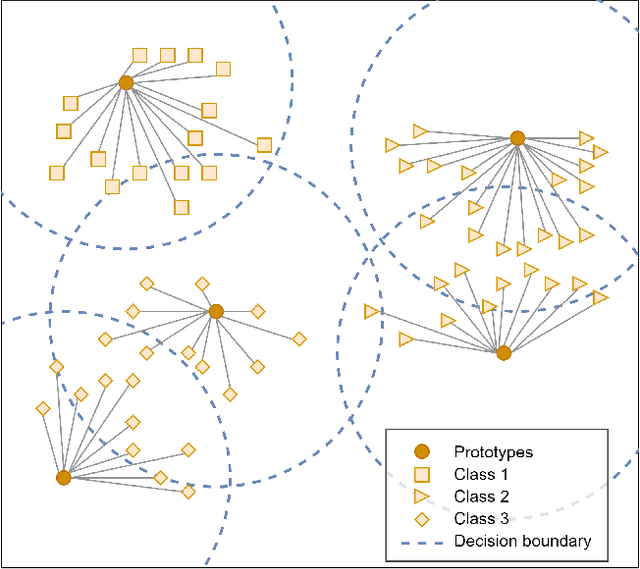

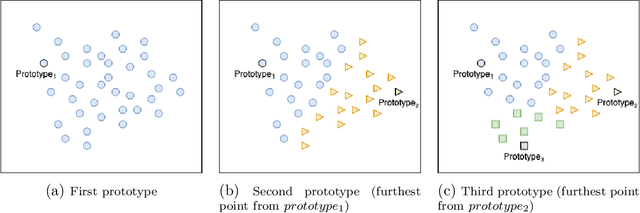
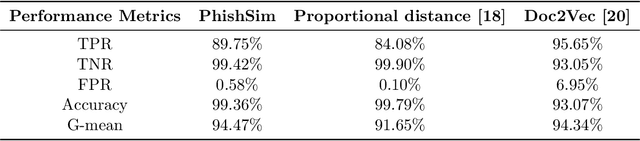
In this paper, we propose a feature-free method for detecting phishing websites using the Normalized Compression Distance (NCD), a parameter-free similarity measure which computes the similarity of two websites by compressing them, thus eliminating the need to perform any feature extraction. It also removes any dependence on a specific set of website features. This method examines the HTML of webpages and computes their similarity with known phishing websites, in order to classify them. We use the Furthest Point First algorithm to perform phishing prototype extractions, in order to select instances that are representative of a cluster of phishing webpages. We also introduce the use of an incremental learning algorithm as a framework for continuous and adaptive detection without extracting new features when concept drift occurs. On a large dataset, our proposed method significantly outperforms previous methods in detecting phishing websites, with an AUC score of 98.68%, a high true positive rate (TPR) of around 90%, while maintaining a low false positive rate (FPR) of 0.58%. Our approach uses prototypes, eliminating the need to retain long term data in the future, and is feasible to deploy in real systems with a processing time of roughly 0.3 seconds.
* 34 pages, 20 figures
Cascading Failures in Smart Grids under Random, Targeted and Adaptive Attacks
Jun 25, 2022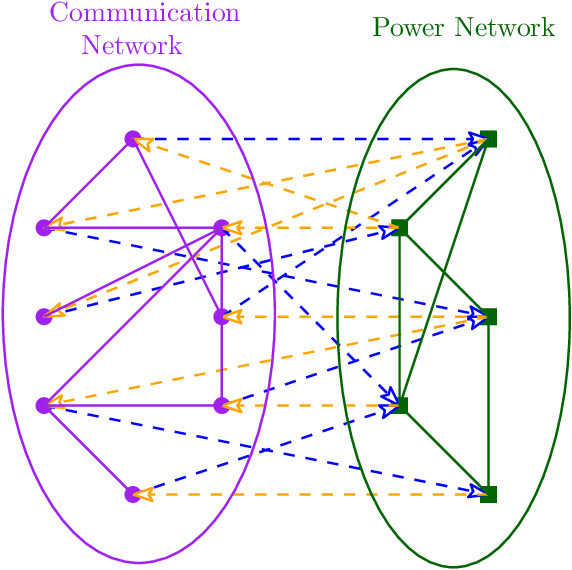
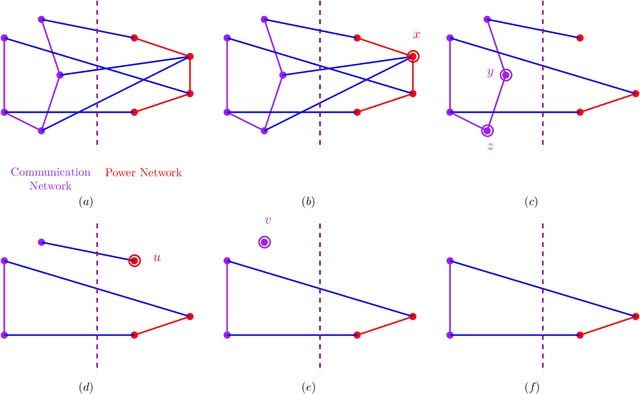
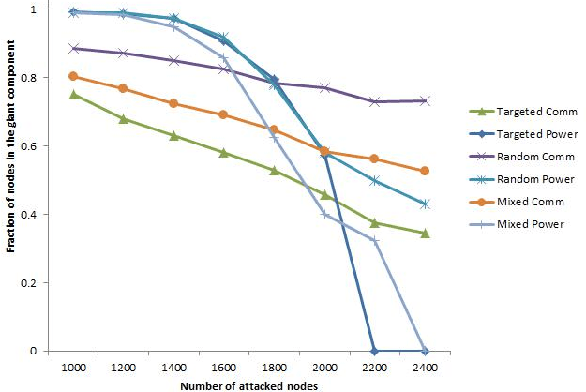
We study cascading failures in smart grids, where an attacker selectively compromises the nodes with probabilities proportional to their degrees, betweenness, or clustering coefficient. This implies that nodes with high degrees, betweenness, or clustering coefficients are attacked with higher probability. We mathematically and experimentally analyze the sizes of the giant components of the networks under different types of targeted attacks, and compare the results with the corresponding sizes under random attacks. We show that networks disintegrate faster for targeted attacks compared to random attacks. A targeted attack on a small fraction of high degree nodes disintegrates one or both of the networks, whereas both the networks contain giant components for random attack on the same fraction of nodes. An important observation is that an attacker has an advantage if it compromises nodes based on their betweenness, rather than based on degree or clustering coefficient. We next study adaptive attacks, where an attacker compromises nodes in rounds. Here, some nodes are compromised in each round based on their degree, betweenness or clustering coefficients, instead of compromising all nodes together. In this case, the degree, betweenness, or clustering coefficient is calculated before the start of each round, instead of at the beginning. We show experimentally that an adversary has an advantage in this adaptive approach, compared to compromising the same number of nodes all at once.
Man versus Machine: AutoML and Human Experts' Role in Phishing Detection
Aug 27, 2021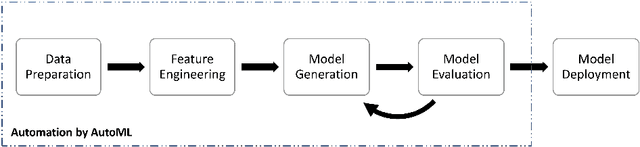


Machine learning (ML) has developed rapidly in the past few years and has successfully been utilized for a broad range of tasks, including phishing detection. However, building an effective ML-based detection system is not a trivial task, and requires data scientists with knowledge of the relevant domain. Automated Machine Learning (AutoML) frameworks have received a lot of attention in recent years, enabling non-ML experts in building a machine learning model. This brings to an intriguing question of whether AutoML can outperform the results achieved by human data scientists. Our paper compares the performances of six well-known, state-of-the-art AutoML frameworks on ten different phishing datasets to see whether AutoML-based models can outperform manually crafted machine learning models. Our results indicate that AutoML-based models are able to outperform manually developed machine learning models in complex classification tasks, specifically in datasets where the features are not quite discriminative, and datasets with overlapping classes or relatively high degrees of non-linearity. Challenges also remain in building a real-world phishing detection system using AutoML frameworks due to the current support only on supervised classification problems, leading to the need for labeled data, and the inability to update the AutoML-based models incrementally. This indicates that experts with knowledge in the domain of phishing and cybersecurity are still essential in the loop of the phishing detection pipeline.
PhishZip: A New Compression-based Algorithm for Detecting Phishing Websites
Jul 22, 2020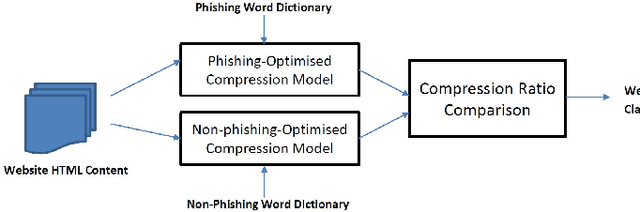
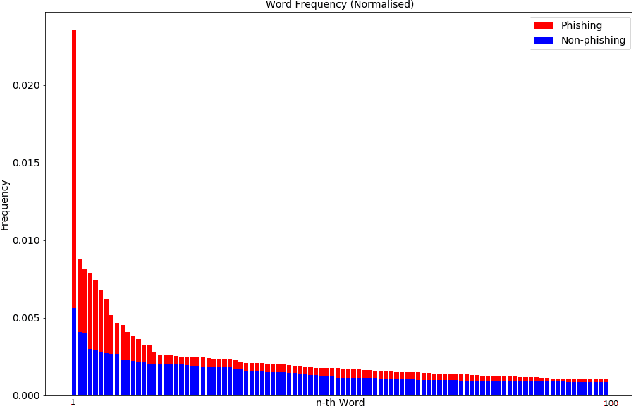
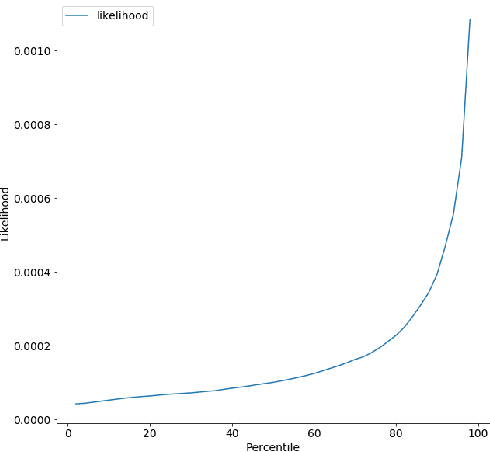
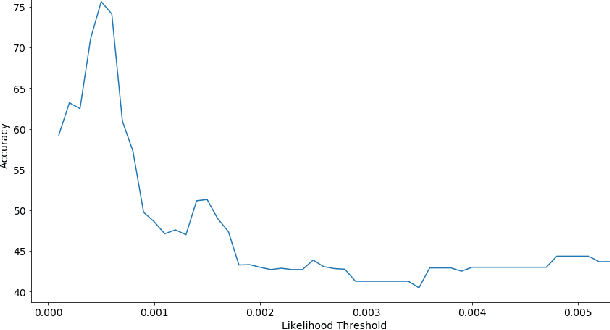
Phishing has grown significantly in the past few years and is predicted to further increase in the future. The dynamics of phishing introduce challenges in implementing a robust phishing detection system and selecting features which can represent phishing despite the change of attack. In this paper, we propose PhishZip which is a novel phishing detection approach using a compression algorithm to perform website classification and demonstrate a systematic way to construct the word dictionaries for the compression models using word occurrence likelihood analysis. PhishZip outperforms the use of best-performing HTML-based features in past studies, with a true positive rate of 80.04%. We also propose the use of compression ratio as a novel machine learning feature which significantly improves machine learning based phishing detection over previous studies. Using compression ratios as additional features, the true positive rate significantly improves by 30.3% (from 51.47% to 81.77%), while the accuracy increases by 11.84% (from 71.20% to 83.04%).
Identification, Tracking and Impact: Understanding the trade secret of catchphrases
Jul 20, 2020

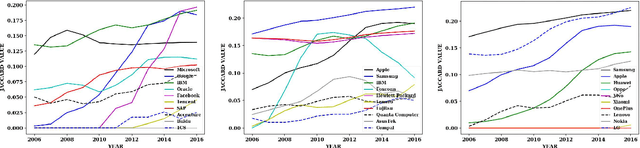
Understanding the topical evolution in industrial innovation is a challenging problem. With the advancement in the digital repositories in the form of patent documents, it is becoming increasingly more feasible to understand the innovation secrets -- "catchphrases" of organizations. However, searching and understanding this enormous textual information is a natural bottleneck. In this paper, we propose an unsupervised method for the extraction of catchphrases from the abstracts of patents granted by the U.S. Patent and Trademark Office over the years. Our proposed system achieves substantial improvement, both in terms of precision and recall, against state-of-the-art techniques. As a second objective, we conduct an extensive empirical study to understand the temporal evolution of the catchphrases across various organizations. We also show how the overall innovation evolution in the form of introduction of newer catchphrases in an organization's patents correlates with the future citations received by the patents filed by that organization. Our code and data sets will be placed in the public domain soon.
Methods for Computing Legal Document Similarity: A Comparative Study
Apr 26, 2020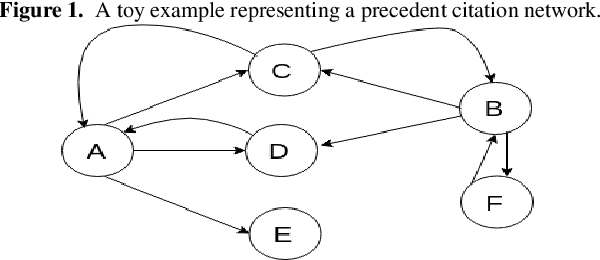
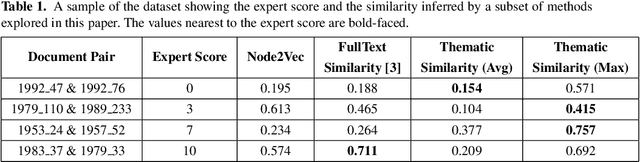
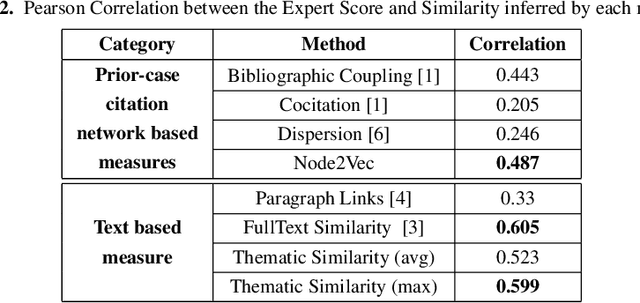
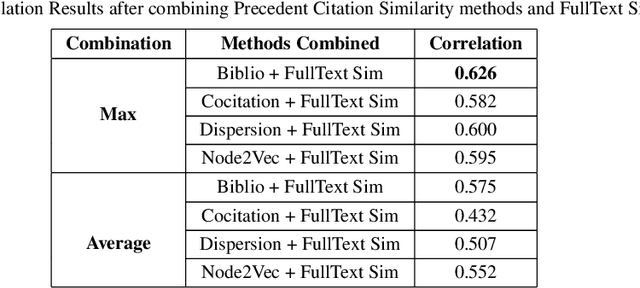
Computing similarity between two legal documents is an important and challenging task in the domain of Legal Information Retrieval. Finding similar legal documents has many applications in downstream tasks, including prior-case retrieval, recommendation of legal articles, and so on. Prior works have proposed two broad ways of measuring similarity between legal documents - analyzing the precedent citation network, and measuring similarity based on textual content similarity measures. But there has not been a comprehensive comparison of these existing methods on a common platform. In this paper, we perform the first systematic analysis of the existing methods. In addition, we explore two promising new similarity computation methods - one text-based and the other based on network embeddings, which have not been considered till now.
BB_Evac: Fast Location-Sensitive Behavior-Based Building Evacuation
Feb 19, 2020
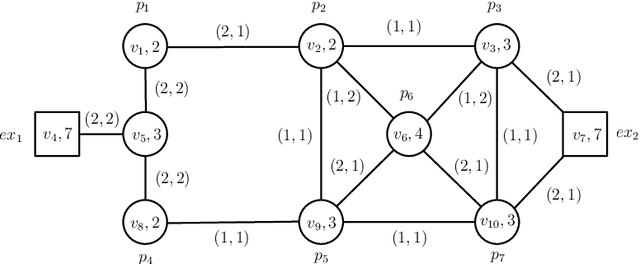
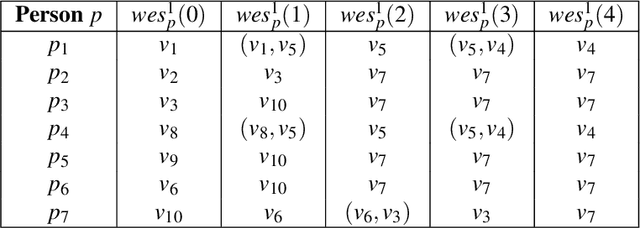
Past work on evacuation planning assumes that evacuees will follow instructions -- however, there is ample evidence that this is not the case. While some people will follow instructions, others will follow their own desires. In this paper, we present a formal definition of a behavior-based evacuation problem (BBEP) in which a human behavior model is taken into account when planning an evacuation. We show that a specific form of constraints can be used to express such behaviors. We show that BBEPs can be solved exactly via an integer program called BB_IP, and inexactly by a much faster algorithm that we call BB_Evac. We conducted a detailed experimental evaluation of both algorithms applied to buildings (though in principle the algorithms can be applied to any graphs) and show that the latter is an order of magnitude faster than BB_IP while producing results that are almost as good on one real-world building graph and as well as on several synthetically generated graphs.