 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXCL: A Tool for Requirement Document Extraction and Classification
Apr 10, 2025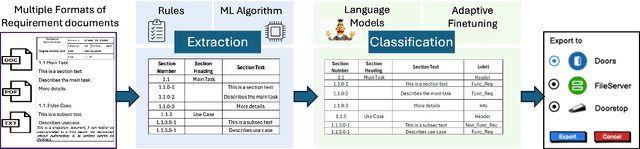
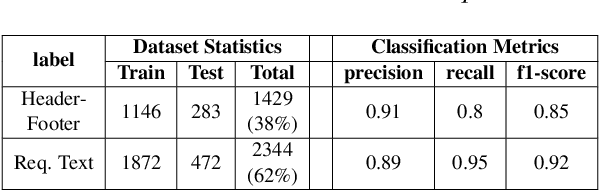
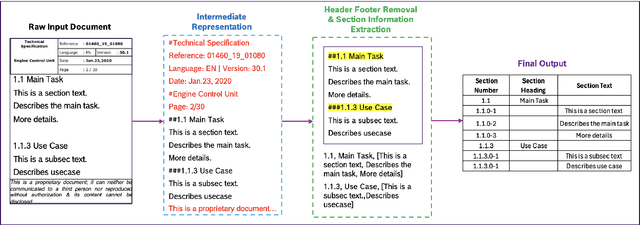
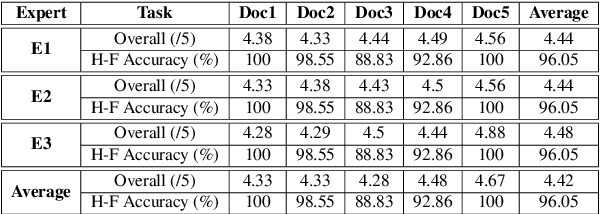
This paper presents the ReXCL tool, which automates the extraction and classification processes in requirement engineering, enhancing the software development lifecycle. The tool features two main modules: Extraction, which processes raw requirement documents into a predefined schema using heuristics and predictive modeling, and Classification, which assigns class labels to requirements using adaptive fine-tuning of encoder-based models. The final output can be exported to external requirement engineering tools. Performance evaluations indicate that ReXCL significantly improves efficiency and accuracy in managing requirements, marking a novel approach to automating the schematization of semi-structured requirement documents.
Selective Shot Learning for Code Explanation
Dec 17, 2024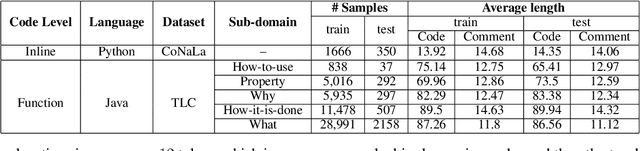
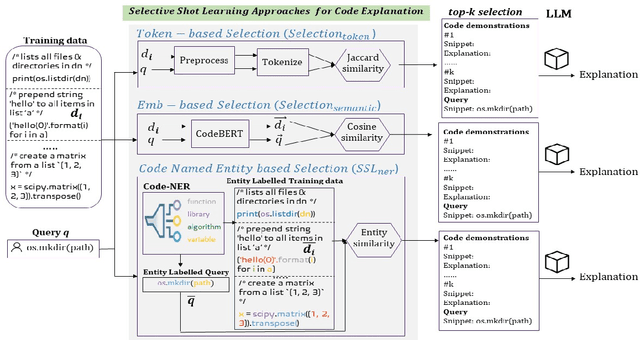
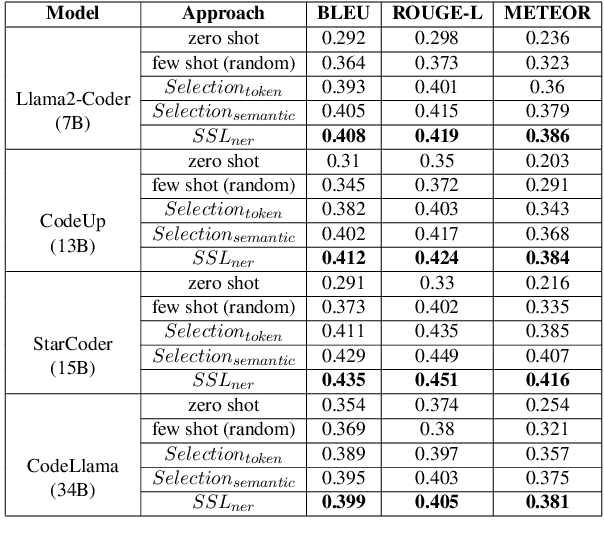
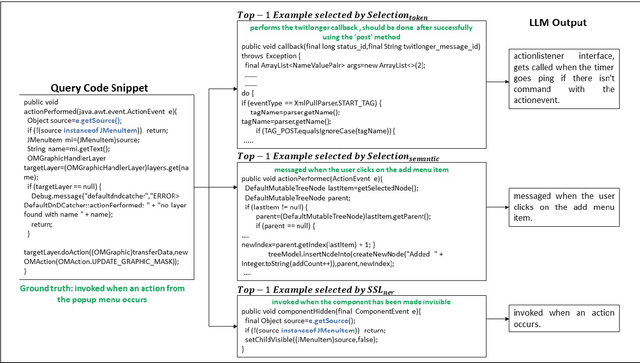
Code explanation plays a crucial role in the software engineering domain, aiding developers in grasping code functionality efficiently. Recent work shows that the performance of LLMs for code explanation improves in a few-shot setting, especially when the few-shot examples are selected intelligently. State-of-the-art approaches for such Selective Shot Learning (SSL) include token-based and embedding-based methods. However, these SSL approaches have been evaluated on proprietary LLMs, without much exploration on open-source Code-LLMs. Additionally, these methods lack consideration for programming language syntax. To bridge these gaps, we present a comparative study and propose a novel SSL method (SSL_ner) that utilizes entity information for few-shot example selection. We present several insights and show the effectiveness of SSL_ner approach over state-of-the-art methods across two datasets. To the best of our knowledge, this is the first systematic benchmarking of open-source Code-LLMs while assessing the performances of the various few-shot examples selection approaches for the code explanation task.
Exploring Large Language Models for Code Explanation
Oct 25, 2023


Automating code documentation through explanatory text can prove highly beneficial in code understanding. Large Language Models (LLMs) have made remarkable strides in Natural Language Processing, especially within software engineering tasks such as code generation and code summarization. This study specifically delves into the task of generating natural-language summaries for code snippets, using various LLMs. The findings indicate that Code LLMs outperform their generic counterparts, and zero-shot methods yield superior results when dealing with datasets with dissimilar distributions between training and testing sets.
Legal Case Document Summarization: Extractive and Abstractive Methods and their Evaluation
Oct 14, 2022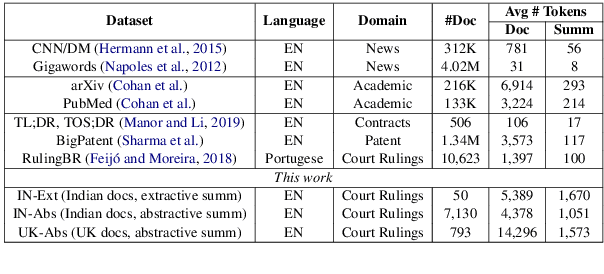
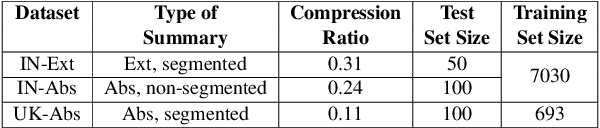
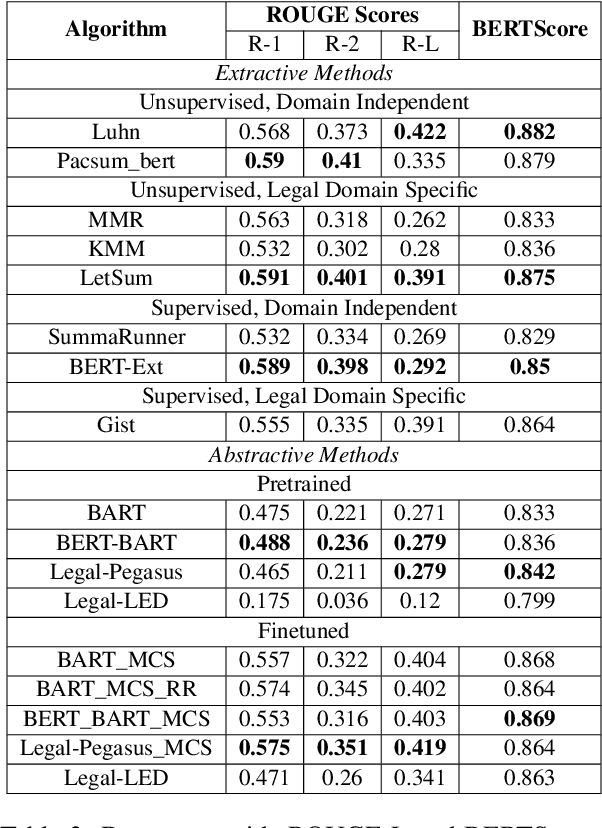
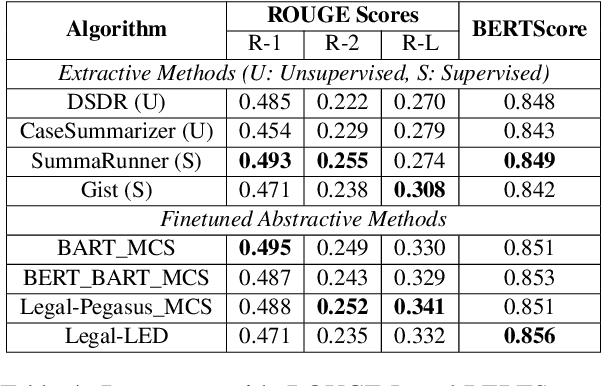
Summarization of legal case judgement documents is a challenging problem in Legal NLP. However, not much analyses exist on how different families of summarization models (e.g., extractive vs. abstractive) perform when applied to legal case documents. This question is particularly important since many recent transformer-based abstractive summarization models have restrictions on the number of input tokens, and legal documents are known to be very long. Also, it is an open question on how best to evaluate legal case document summarization systems. In this paper, we carry out extensive experiments with several extractive and abstractive summarization methods (both supervised and unsupervised) over three legal summarization datasets that we have developed. Our analyses, that includes evaluation by law practitioners, lead to several interesting insights on legal summarization in specific and long document summarization in general.
Legal Case Document Similarity: You Need Both Network and Text
Sep 26, 2022
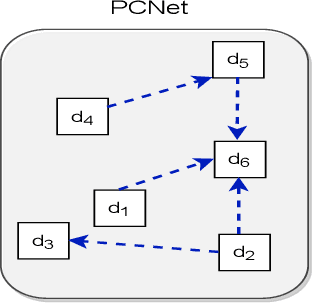

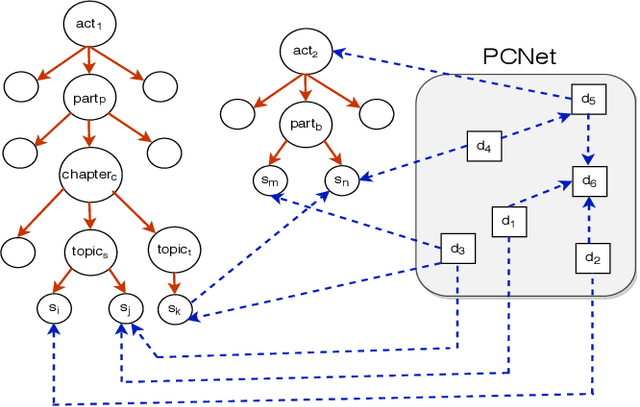
Estimating the similarity between two legal case documents is an important and challenging problem, having various downstream applications such as prior-case retrieval and citation recommendation. There are two broad approaches for the task -- citation network-based and text-based. Prior citation network-based approaches consider citations only to prior-cases (also called precedents) (PCNet). This approach misses important signals inherent in Statutes (written laws of a jurisdiction). In this work, we propose Hier-SPCNet that augments PCNet with a heterogeneous network of Statutes. We incorporate domain knowledge for legal document similarity into Hier-SPCNet, thereby obtaining state-of-the-art results for network-based legal document similarity. Both textual and network similarity provide important signals for legal case similarity; but till now, only trivial attempts have been made to unify the two signals. In this work, we apply several methods for combining textual and network information for estimating legal case similarity. We perform extensive experiments over legal case documents from the Indian judiciary, where the gold standard similarity between document-pairs is judged by law experts from two reputed Law institutes in India. Our experiments establish that our proposed network-based methods significantly improve the correlation with domain experts' opinion when compared to the existing methods for network-based legal document similarity. Our best-performing combination method (that combines network-based and text-based similarity) improves the correlation with domain experts' opinion by 11.8% over the best text-based method and 20.6\% over the best network-based method. We also establish that our best-performing method can be used to recommend / retrieve citable and similar cases for a source (query) case, which are well appreciated by legal experts.
Incorporating Domain Knowledge for Extractive Summarization of Legal Case Documents
Jun 30, 2021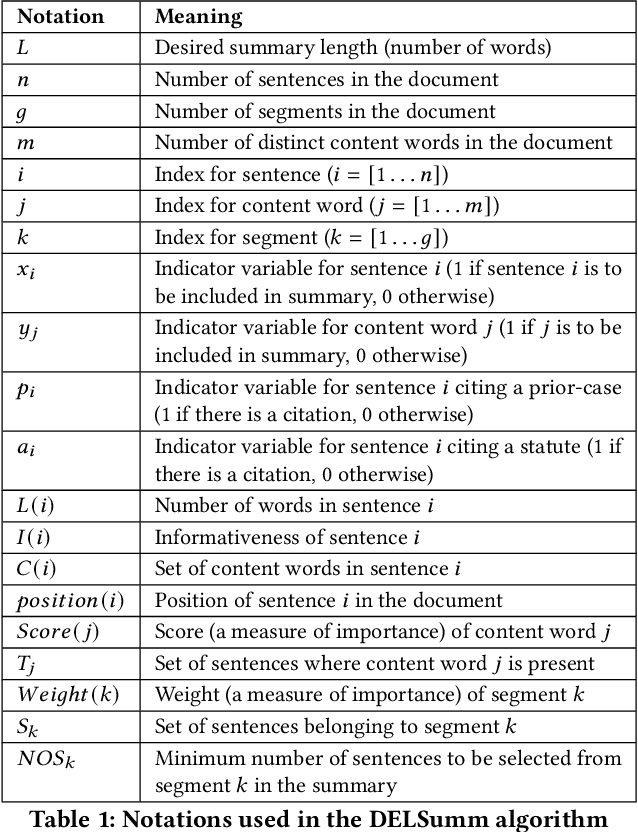
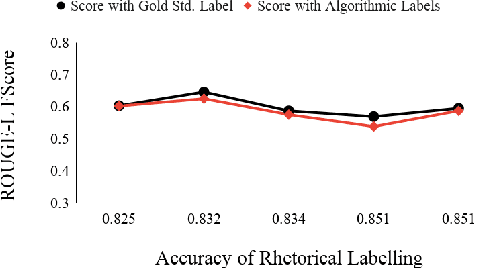


Automatic summarization of legal case documents is an important and practical challenge. Apart from many domain-independent text summarization algorithms that can be used for this purpose, several algorithms have been developed specifically for summarizing legal case documents. However, most of the existing algorithms do not systematically incorporate domain knowledge that specifies what information should ideally be present in a legal case document summary. To address this gap, we propose an unsupervised summarization algorithm DELSumm which is designed to systematically incorporate guidelines from legal experts into an optimization setup. We conduct detailed experiments over case documents from the Indian Supreme Court. The experiments show that our proposed unsupervised method outperforms several strong baselines in terms of ROUGE scores, including both general summarization algorithms and legal-specific ones. In fact, though our proposed algorithm is unsupervised, it outperforms several supervised summarization models that are trained over thousands of document-summary pairs.
Methods for Computing Legal Document Similarity: A Comparative Study
Apr 26, 2020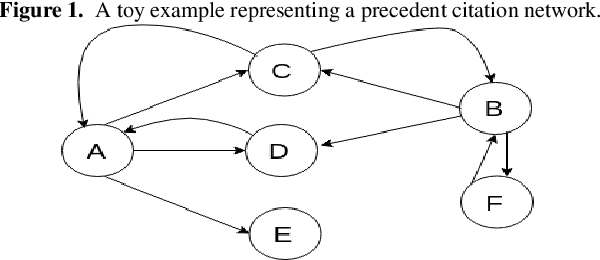
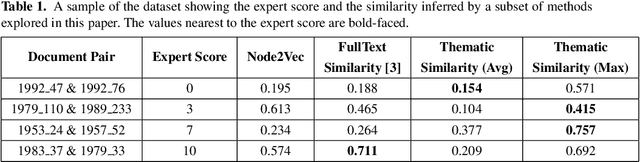
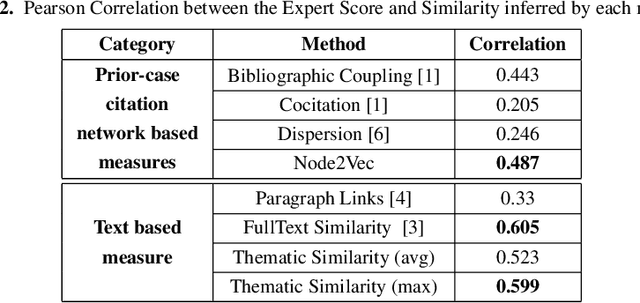
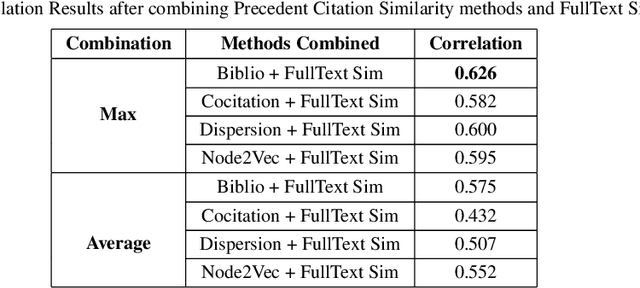
Computing similarity between two legal documents is an important and challenging task in the domain of Legal Information Retrieval. Finding similar legal documents has many applications in downstream tasks, including prior-case retrieval, recommendation of legal articles, and so on. Prior works have proposed two broad ways of measuring similarity between legal documents - analyzing the precedent citation network, and measuring similarity based on textual content similarity measures. But there has not been a comprehensive comparison of these existing methods on a common platform. In this paper, we perform the first systematic analysis of the existing methods. In addition, we explore two promising new similarity computation methods - one text-based and the other based on network embeddings, which have not been considered till now.
UsingWord Embeddings for Query Translation for Hindi to English Cross Language Information Retrieval
Aug 04, 2016
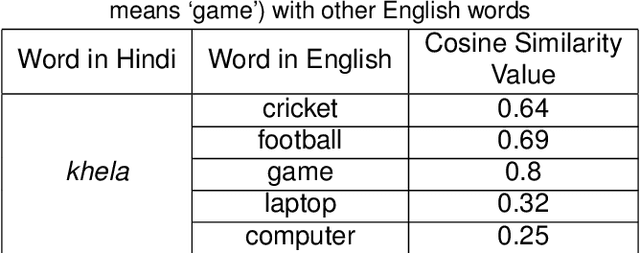
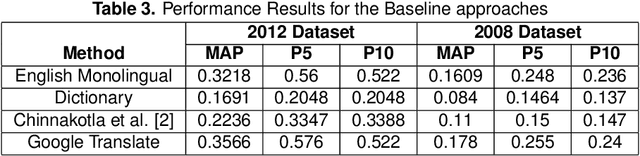
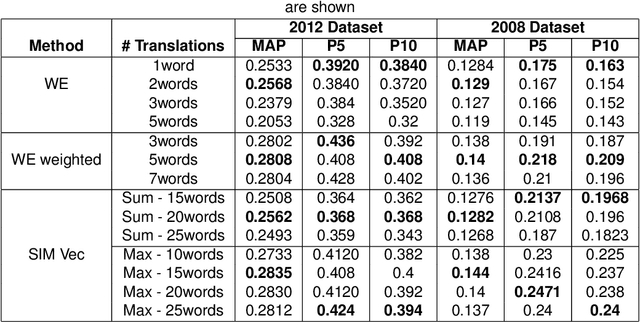
Cross-Language Information Retrieval (CLIR) has become an important problem to solve in the recent years due to the growth of content in multiple languages in the Web. One of the standard methods is to use query translation from source to target language. In this paper, we propose an approach based on word embeddings, a method that captures contextual clues for a particular word in the source language and gives those words as translations that occur in a similar context in the target language. Once we obtain the word embeddings of the source and target language pairs, we learn a projection from source to target word embeddings, making use of a dictionary with word translation pairs.We then propose various methods of query translation and aggregation. The advantage of this approach is that it does not require the corpora to be aligned (which is difficult to obtain for resource-scarce languages), a dictionary with word translation pairs is enough to train the word vectors for translation. We experiment with Forum for Information Retrieval and Evaluation (FIRE) 2008 and 2012 datasets for Hindi to English CLIR. The proposed word embedding based approach outperforms the basic dictionary based approach by 70% and when the word embeddings are combined with the dictionary, the hybrid approach beats the baseline dictionary based method by 77%. It outperforms the English monolingual baseline by 15%, when combined with the translations obtained from Google Translate and Dictionary.
Evolution of the Modern Phase of Written Bangla: A Statistical Study
Oct 06, 2013
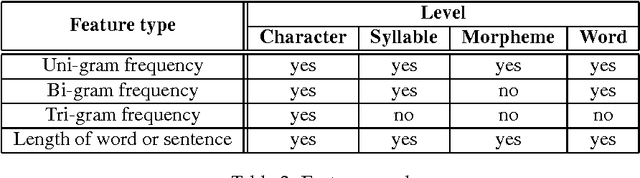


Active languages such as Bangla (or Bengali) evolve over time due to a variety of social, cultural, economic, and political issues. In this paper, we analyze the change in the written form of the modern phase of Bangla quantitatively in terms of character-level, syllable-level, morpheme-level and word-level features. We collect three different types of corpora---classical, newspapers and blogs---and test whether the differences in their features are statistically significant. Results suggest that there are significant changes in the length of a word when measured in terms of characters, but there is not much difference in usage of different characters, syllables and morphemes in a word or of different words in a sentence. To the best of our knowledge, this is the first work on Bangla of this kind.