 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Case Document Similarity: You Need Both Network and Text
Paper and Code

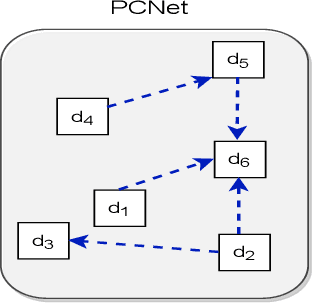

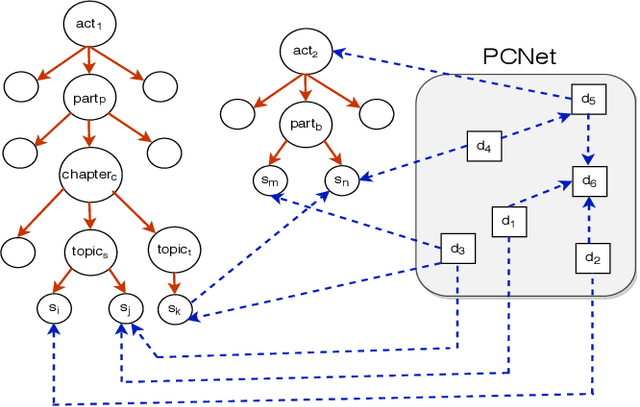
Estimating the similarity between two legal case documents is an important and challenging problem, having various downstream applications such as prior-case retrieval and citation recommendation. There are two broad approaches for the task -- citation network-based and text-based. Prior citation network-based approaches consider citations only to prior-cases (also called precedents) (PCNet). This approach misses important signals inherent in Statutes (written laws of a jurisdiction). In this work, we propose Hier-SPCNet that augments PCNet with a heterogeneous network of Statutes. We incorporate domain knowledge for legal document similarity into Hier-SPCNet, thereby obtaining state-of-the-art results for network-based legal document similarity. Both textual and network similarity provide important signals for legal case similarity; but till now, only trivial attempts have been made to unify the two signals. In this work, we apply several methods for combining textual and network information for estimating legal case similarity. We perform extensive experiments over legal case documents from the Indian judiciary, where the gold standard similarity between document-pairs is judged by law experts from two reputed Law institutes in India. Our experiments establish that our proposed network-based methods significantly improve the correlation with domain experts' opinion when compared to the existing methods for network-based legal document similarity. Our best-performing combination method (that combines network-based and text-based similarity) improves the correlation with domain experts' opinion by 11.8% over the best text-based method and 20.6\% over the best network-based method. We also establish that our best-performing method can be used to recommend / retrieve citable and similar cases for a source (query) case, which are well appreciated by legal experts.