 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Judge a Book by its Cover: Testing LLMs' Robustness Under Logical Obfuscation
Feb 01, 2026Tasks such as solving arithmetic equations, evaluating truth tables, and completing syllogisms are handled well by large language models (LLMs) in their standard form, but they often fail when the same problems are posed in logically equivalent yet obfuscated formats. To study this vulnerability, we introduce Logifus, a structure-preserving logical obfuscation framework, and, utilizing this, we present LogiQAte, a first-of-its-kind diagnostic benchmark with 1,108 questions across four reasoning tasks: (i) Obfus FOL (first-order logic entailment under equivalence-preserving rewrites), (ii) Obfus Blood Relation (family-graph entailment under indirect relational chains), (iii) Obfus Number Series (pattern induction under symbolic substitutions), and (iv) Obfus Direction Sense (navigation reasoning under altered directions and reference frames). Across all the tasks, evaluating six state-of-the-art models, we find that obfuscation severely degrades zero-shot performance, with performance dropping on average by 47% for GPT-4o, 27% for GPT-5, and 22% for reasoning model, o4-mini. Our findings reveal that current LLMs parse questions without deep understanding, highlighting the urgency of building models that genuinely comprehend and preserve meaning beyond surface form.
ReGal: A First Look at PPO-based Legal AI for Judgment Prediction and Summarization in India
Dec 19, 2025This paper presents an early exploration of reinforcement learning methodologies for legal AI in the Indian context. We introduce Reinforcement Learning-based Legal Reasoning (ReGal), a framework that integrates Multi-Task Instruction Tuning with Reinforcement Learning from AI Feedback (RLAIF) using Proximal Policy Optimization (PPO). Our approach is evaluated across two critical legal tasks: (i) Court Judgment Prediction and Explanation (CJPE), and (ii) Legal Document Summarization. Although the framework underperforms on standard evaluation metrics compared to supervised and proprietary models, it provides valuable insights into the challenges of applying RL to legal texts. These challenges include reward model alignment, legal language complexity, and domain-specific adaptation. Through empirical and qualitative analysis, we demonstrate how RL can be repurposed for high-stakes, long-document tasks in law. Our findings establish a foundation for future work on optimizing legal reasoning pipelines using reinforcement learning, with broader implications for building interpretable and adaptive legal AI systems.
Causal Reasoning Favors Encoders: On The Limits of Decoder-Only Models
Dec 11, 2025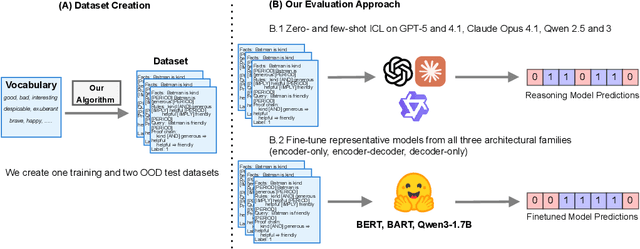



In context learning (ICL) underpins recent advances in large language models (LLMs), although its role and performance in causal reasoning remains unclear. Causal reasoning demands multihop composition and strict conjunctive control, and reliance on spurious lexical relations of the input could provide misleading results. We hypothesize that, due to their ability to project the input into a latent space, encoder and encoder decoder architectures are better suited for said multihop conjunctive reasoning versus decoder only models. To do this, we compare fine-tuned versions of all the aforementioned architectures with zero and few shot ICL in both natural language and non natural language scenarios. We find that ICL alone is insufficient for reliable causal reasoning, often overfocusing on irrelevant input features. In particular, decoder only models are noticeably brittle to distributional shifts, while finetuned encoder and encoder decoder models can generalize more robustly across our tests, including the non natural language split. Both architectures are only matched or surpassed by decoder only architectures at large scales. We conclude by noting that for cost effective, short horizon robust causal reasoning, encoder or encoder decoder architectures with targeted finetuning are preferable.
SMITE: Enhancing Fairness in LLMs through Optimal In-Context Example Selection via Dynamic Validation
Aug 25, 2025Large Language Models (LLMs) are widely used for downstream tasks such as tabular classification, where ensuring fairness in their outputs is critical for inclusivity, equal representation, and responsible AI deployment. This study introduces a novel approach to enhancing LLM performance and fairness through the concept of a dynamic validation set, which evolves alongside the test set, replacing the traditional static validation approach. We also propose an iterative algorithm, SMITE, to select optimal in-context examples, with each example set validated against its corresponding dynamic validation set. The in-context set with the lowest total error is used as the final demonstration set. Our experiments across four different LLMs show that our proposed techniques significantly improve both predictive accuracy and fairness compared to baseline methods. To our knowledge, this is the first study to apply dynamic validation in the context of in-context learning for LLMs.
ObfusQAte: A Proposed Framework to Evaluate LLM Robustness on Obfuscated Factual Question Answering
Aug 10, 2025The rapid proliferation of Large Language Models (LLMs) has significantly contributed to the development of equitable AI systems capable of factual question-answering (QA). However, no known study tests the LLMs' robustness when presented with obfuscated versions of questions. To systematically evaluate these limitations, we propose a novel technique, ObfusQAte and, leveraging the same, introduce ObfusQA, a comprehensive, first of its kind, framework with multi-tiered obfuscation levels designed to examine LLM capabilities across three distinct dimensions: (i) Named-Entity Indirection, (ii) Distractor Indirection, and (iii) Contextual Overload. By capturing these fine-grained distinctions in language, ObfusQA provides a comprehensive benchmark for evaluating LLM robustness and adaptability. Our study observes that LLMs exhibit a tendency to fail or generate hallucinated responses when confronted with these increasingly nuanced variations. To foster research in this direction, we make ObfusQAte publicly available.
NyayaRAG: Realistic Legal Judgment Prediction with RAG under the Indian Common Law System
Aug 01, 2025Legal Judgment Prediction (LJP) has emerged as a key area in AI for law, aiming to automate judicial outcome forecasting and enhance interpretability in legal reasoning. While previous approaches in the Indian context have relied on internal case content such as facts, issues, and reasoning, they often overlook a core element of common law systems, which is reliance on statutory provisions and judicial precedents. In this work, we propose NyayaRAG, a Retrieval-Augmented Generation (RAG) framework that simulates realistic courtroom scenarios by providing models with factual case descriptions, relevant legal statutes, and semantically retrieved prior cases. NyayaRAG evaluates the effectiveness of these combined inputs in predicting court decisions and generating legal explanations using a domain-specific pipeline tailored to the Indian legal system. We assess performance across various input configurations using both standard lexical and semantic metrics as well as LLM-based evaluators such as G-Eval. Our results show that augmenting factual inputs with structured legal knowledge significantly improves both predictive accuracy and explanation quality.
SELF-PERCEPT: Introspection Improves Large Language Models' Detection of Multi-Person Mental Manipulation in Conversations
May 27, 2025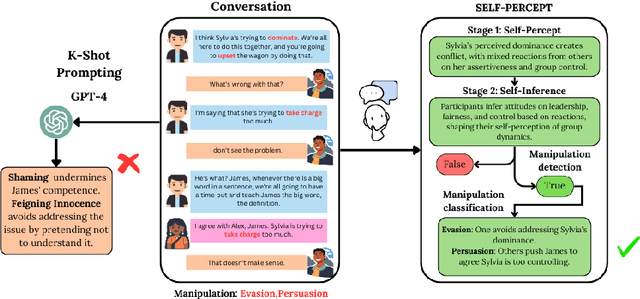
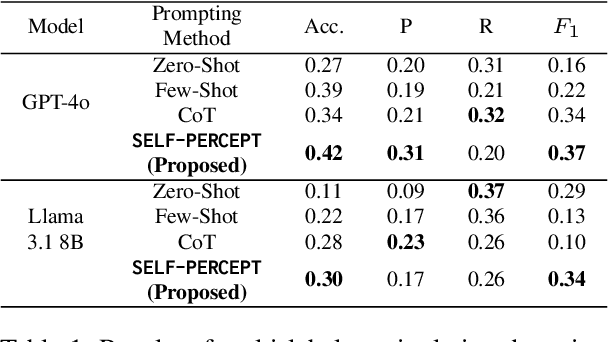
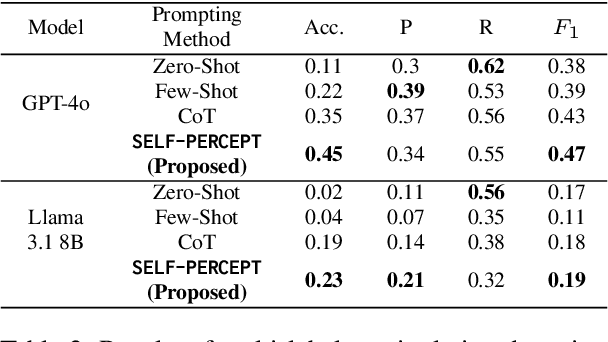
Mental manipulation is a subtle yet pervasive form of abuse in interpersonal communication, making its detection critical for safeguarding potential victims. However, due to manipulation's nuanced and context-specific nature, identifying manipulative language in complex, multi-turn, and multi-person conversations remains a significant challenge for large language models (LLMs). To address this gap, we introduce the MultiManip dataset, comprising 220 multi-turn, multi-person dialogues balanced between manipulative and non-manipulative interactions, all drawn from reality shows that mimic real-world scenarios. For manipulative interactions, it includes 11 distinct manipulations depicting real-life scenarios. We conduct extensive evaluations of state-of-the-art LLMs, such as GPT-4o and Llama-3.1-8B, employing various prompting strategies. Despite their capabilities, these models often struggle to detect manipulation effectively. To overcome this limitation, we propose SELF-PERCEPT, a novel, two-stage prompting framework inspired by Self-Perception Theory, demonstrating strong performance in detecting multi-person, multi-turn mental manipulation. Our code and data are publicly available at https://github.com/danushkhanna/self-percept .
TathyaNyaya and FactLegalLlama: Advancing Factual Judgment Prediction and Explanation in the Indian Legal Context
Apr 07, 2025In the landscape of Fact-based Judgment Prediction and Explanation (FJPE), reliance on factual data is essential for developing robust and realistic AI-driven decision-making tools. This paper introduces TathyaNyaya, the largest annotated dataset for FJPE tailored to the Indian legal context, encompassing judgments from the Supreme Court of India and various High Courts. Derived from the Hindi terms "Tathya" (fact) and "Nyaya" (justice), the TathyaNyaya dataset is uniquely designed to focus on factual statements rather than complete legal texts, reflecting real-world judicial processes where factual data drives outcomes. Complementing this dataset, we present FactLegalLlama, an instruction-tuned variant of the LLaMa-3-8B Large Language Model (LLM), optimized for generating high-quality explanations in FJPE tasks. Finetuned on the factual data in TathyaNyaya, FactLegalLlama integrates predictive accuracy with coherent, contextually relevant explanations, addressing the critical need for transparency and interpretability in AI-assisted legal systems. Our methodology combines transformers for binary judgment prediction with FactLegalLlama for explanation generation, creating a robust framework for advancing FJPE in the Indian legal domain. TathyaNyaya not only surpasses existing datasets in scale and diversity but also establishes a benchmark for building explainable AI systems in legal analysis. The findings underscore the importance of factual precision and domain-specific tuning in enhancing predictive performance and interpretability, positioning TathyaNyaya and FactLegalLlama as foundational resources for AI-assisted legal decision-making.
Structured Legal Document Generation in India: A Model-Agnostic Wrapper Approach with VidhikDastaavej
Apr 04, 2025Automating legal document drafting can significantly enhance efficiency, reduce manual effort, and streamline legal workflows. While prior research has explored tasks such as judgment prediction and case summarization, the structured generation of private legal documents in the Indian legal domain remains largely unaddressed. To bridge this gap, we introduce VidhikDastaavej, a novel, anonymized dataset of private legal documents, and develop NyayaShilp, a fine-tuned legal document generation model specifically adapted to Indian legal texts. We propose a Model-Agnostic Wrapper (MAW), a two-step framework that first generates structured section titles and then iteratively produces content while leveraging retrieval-based mechanisms to ensure coherence and factual accuracy. We benchmark multiple open-source LLMs, including instruction-tuned and domain-adapted versions, alongside proprietary models for comparison. Our findings indicate that while direct fine-tuning on small datasets does not always yield improvements, our structured wrapper significantly enhances coherence, factual adherence, and overall document quality while mitigating hallucinations. To ensure real-world applicability, we developed a Human-in-the-Loop (HITL) Document Generation System, an interactive user interface that enables users to specify document types, refine section details, and generate structured legal drafts. This tool allows legal professionals and researchers to generate, validate, and refine AI-generated legal documents efficiently. Extensive evaluations, including expert assessments, confirm that our framework achieves high reliability in structured legal drafting. This research establishes a scalable and adaptable foundation for AI-assisted legal drafting in India, offering an effective approach to structured legal document generation.
LegalSeg: Unlocking the Structure of Indian Legal Judgments Through Rhetorical Role Classification
Feb 09, 2025In this paper, we address the task of semantic segmentation of legal documents through rhetorical role classification, with a focus on Indian legal judgments. We introduce LegalSeg, the largest annotated dataset for this task, comprising over 7,000 documents and 1.4 million sentences, labeled with 7 rhetorical roles. To benchmark performance, we evaluate multiple state-of-the-art models, including Hierarchical BiLSTM-CRF, TransformerOverInLegalBERT (ToInLegalBERT), Graph Neural Networks (GNNs), and Role-Aware Transformers, alongside an exploratory RhetoricLLaMA, an instruction-tuned large language model. Our results demonstrate that models incorporating broader context, structural relationships, and sequential sentence information outperform those relying solely on sentence-level features. Additionally, we conducted experiments using surrounding context and predicted or actual labels of neighboring sentences to assess their impact on classification accuracy. Despite these advancements, challenges persist in distinguishing between closely related roles and addressing class imbalance. Our work underscores the potential of advanced techniques for improving legal document understanding and sets a strong foundation for future research in legal NLP.