 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnTransformer: A Deep Generative Transformer for Multivariate Probabilistic Forecasting
Mar 12, 2026Reliable uncertainty quantification is critical in multivariate time series forecasting problems arising in domains such as energy systems and transportation networks, among many others. Although Transformer-based architectures have recently achieved strong performance for sequence modeling, most probabilistic forecasting approaches rely on restrictive parametric likelihoods or quantile-based objectives. They can struggle to capture complex joint predictive distributions across multiple correlated time series. This work proposes EnTransformer, a deep generative forecasting framework that integrates engression, a stochastic learning paradigm for modeling conditional distributions, with the expressive sequence modeling capabilities of Transformers. The proposed approach injects stochastic noise into the model representation and optimizes an energy-based scoring objective to directly learn the conditional predictive distribution without imposing parametric assumptions. This design enables EnTransformer to generate coherent multivariate forecast trajectories while preserving Transformers' capacity to effectively model long-range temporal dependencies and cross-series interactions. We evaluate our proposed EnTransformer on several widely used benchmarks for multivariate probabilistic forecasting, including Electricity, Traffic, Solar, Taxi, KDD-cup, and Wikipedia datasets. Experimental results demonstrate that EnTransformer produces well-calibrated probabilistic forecasts and consistently outperforms the benchmark models.
Demystifying the trend of the healthcare index: Is historical price a key driver?
Jan 20, 2026Healthcare sector indices consolidate the economic health of pharmaceutical, biotechnology, and healthcare service firms. The short-term movements in these indices are closely intertwined with capital allocation decisions affecting research and development investment, drug availability, and long-term health outcomes. This research investigates whether historical open-high-low-close (OHLC) index data contain sufficient information for predicting the directional movement of the opening index on the subsequent trading day. The problem is formulated as a supervised classification task involving a one-step-ahead rolling window. A diverse feature set is constructed, comprising original prices, volatility-based technical indicators, and a novel class of nowcasting features derived from mutual OHLC ratios. The framework is evaluated on data from healthcare indices in the U.S. and Indian markets over a five-year period spanning multiple economic phases, including the COVID-19 pandemic. The results demonstrate robust predictive performance, with accuracy exceeding 0.8 and Matthews correlation coefficients above 0.6. Notably, the proposed nowcasting features have emerged as a key determinant of the market movement. We have employed the Shapley-based explainability paradigm to further elucidate the contribution of the features: outcomes reveal the dominant role of the nowcasting features, followed by a more moderate contribution of original prices. This research offers a societal utility: the proposed features and model for short-term forecasting of healthcare indices can reduce information asymmetry and support a more stable and equitable health economy.
Salt-Rock Creep Deformation Forecasting Using Deep Neural Networks and Analytical Models for Subsurface Energy Storage Applications
Aug 07, 2025This study provides an in-depth analysis of time series forecasting methods to predict the time-dependent deformation trend (also known as creep) of salt rock under varying confining pressure conditions. Creep deformation assessment is essential for designing and operating underground storage facilities for nuclear waste, hydrogen energy, or radioactive materials. Salt rocks, known for their mechanical properties like low porosity, low permeability, high ductility, and exceptional creep and self-healing capacities, were examined using multi-stage triaxial (MSTL) creep data. After resampling, axial strain datasets were recorded at 5--10 second intervals under confining pressure levels ranging from 5 to 35 MPa over 5.8--21 days. Initial analyses, including Seasonal-Trend Decomposition (STL) and Granger causality tests, revealed minimal seasonality and causality between axial strain and temperature data. Further statistical tests, such as the Augmented Dickey-Fuller (ADF) test, confirmed the stationarity of the data with p-values less than 0.05, and wavelet coherence plot (WCP) analysis indicated repeating trends. A suite of deep neural network (DNN) models (Neural Basis Expansion Analysis for Time Series (N-BEATS), Temporal Convolutional Networks (TCN), Recurrent Neural Networks (RNN), and Transformers (TF)) was utilized and compared against statistical baseline models. Predictive performance was evaluated using Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Symmetric Mean Absolute Percentage Error (SMAPE). Results demonstrated that N-BEATS and TCN models outperformed others across various stress levels, respectively. DNN models, particularly N-BEATS and TCN, showed a 15--20\% improvement in accuracy over traditional analytical models, effectively capturing complex temporal dependencies and patterns.
Developing cholera outbreak forecasting through qualitative dynamics: Insights into Malawi case study
Mar 18, 2025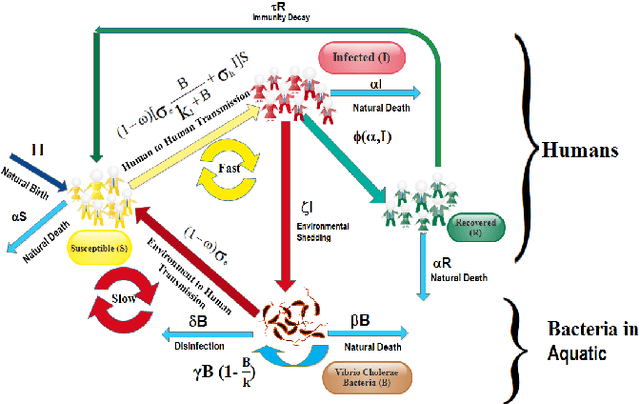
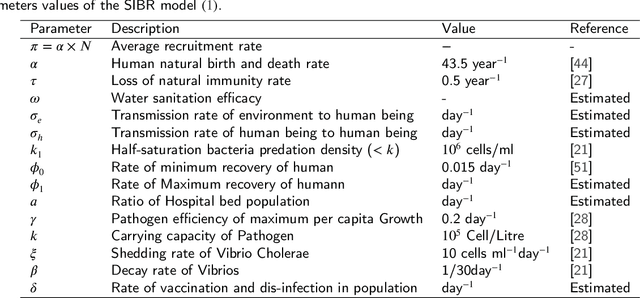
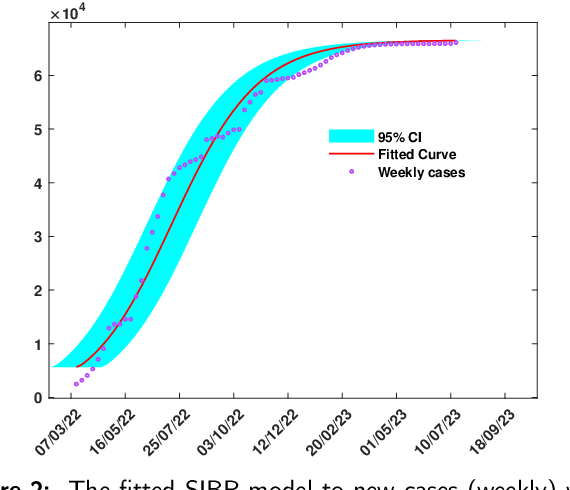
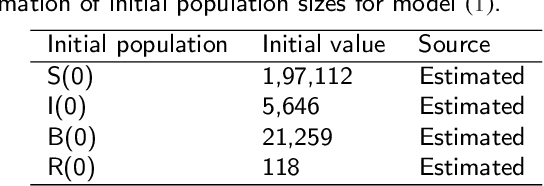
Cholera, an acute diarrheal disease, is a serious concern in developing and underdeveloped areas. A qualitative understanding of cholera epidemics aims to foresee transmission patterns based on reported data and mechanistic models. The mechanistic model is a crucial tool for capturing the dynamics of disease transmission and population spread. However, using real-time cholera cases is essential for forecasting the transmission trend. This prospective study seeks to furnish insights into transmission trends through qualitative dynamics followed by machine learning-based forecasting. The Monte Carlo Markov Chain approach is employed to calibrate the proposed mechanistic model. We identify critical parameters that illustrate the disease's dynamics using partial rank correlation coefficient-based sensitivity analysis. The basic reproduction number as a crucial threshold measures asymptotic dynamics. Furthermore, forward bifurcation directs the stability of the infection state, and Hopf bifurcation suggests that trends in transmission may become unpredictable as societal disinfection rates rise. Further, we develop epidemic-informed machine learning models by incorporating mechanistic cholera dynamics into autoregressive integrated moving averages and autoregressive neural networks. We forecast short-term future cholera cases in Malawi by implementing the proposed epidemic-informed machine learning models to support this. We assert that integrating temporal dynamics into the machine learning models can enhance the capabilities of cholera forecasting models. The execution of this mechanism can significantly influence future trends in cholera transmission. This evolving approach can also be beneficial for policymakers to interpret and respond to potential disease systems. Moreover, our methodology is replicable and adaptable, encouraging future research on disease dynamics.
Wavelet-based Temporal Attention Improves Traffic Forecasting
Jul 05, 2024



Spatio-temporal forecasting of traffic flow data represents a typical problem in the field of machine learning, impacting urban traffic management systems. Traditional statistical and machine learning methods cannot adequately handle both the temporal and spatial dependencies in these complex traffic flow datasets. A prevalent approach in the field is to combine graph convolutional networks and multi-head attention mechanisms for spatio-temporal processing. This paper proposes a wavelet-based temporal attention model, namely a wavelet-based dynamic spatio-temporal aware graph neural network (W-DSTAGNN), for tackling the traffic forecasting problem. Benchmark experiments using several statistical metrics confirm that our proposal efficiently captures spatio-temporal correlations and outperforms ten state-of-the-art models on three different real-world traffic datasets. Our proposed ensemble data-driven method can handle dynamic temporal and spatial dependencies and make long-term forecasts in an efficient manner.
Footprints of Data in a Classifier Model: The Privacy Issues and Their Mitigation through Data Obfuscation
Jul 02, 2024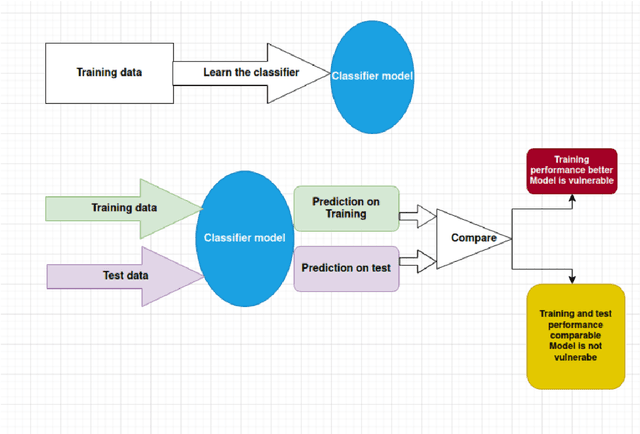
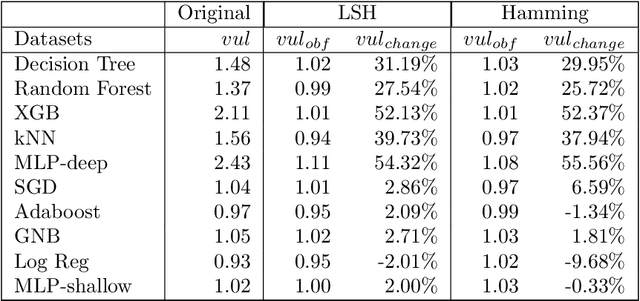
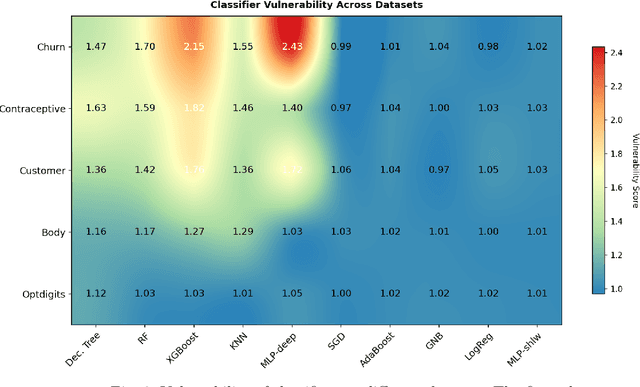
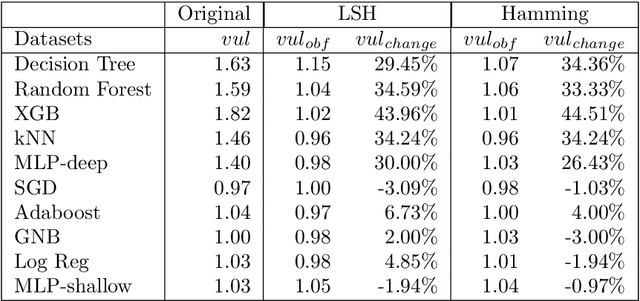
The avalanche of AI deployment and its security-privacy concerns are two sides of the same coin. Article 17 of GDPR calls for the Right to Erasure; data has to be obliterated from a system to prevent its compromise. Extant research in this aspect focuses on effacing sensitive data attributes. However, several passive modes of data compromise are yet to be recognized and redressed. The embedding of footprints of training data in a prediction model is one such facet; the difference in performance quality in test and training data causes passive identification of data that have trained the model. This research focuses on addressing the vulnerability arising from the data footprints. The three main aspects are -- i] exploring the vulnerabilities of different classifiers (to segregate the vulnerable and the non-vulnerable ones), ii] reducing the vulnerability of vulnerable classifiers (through data obfuscation) to preserve model and data privacy, and iii] exploring the privacy-performance tradeoff to study the usability of the data obfuscation techniques. An empirical study is conducted on three datasets and eight classifiers to explore the above objectives. The results of the initial research identify the vulnerability in classifiers and segregate the vulnerable and non-vulnerable classifiers. The additional experiments on data obfuscation techniques reveal their utility to render data and model privacy and also their capability to chalk out a privacy-performance tradeoff in most scenarios. The results can aid the practitioners with their choice of classifiers in different scenarios and contexts.
WaveCatBoost for Probabilistic Forecasting of Regional Air Quality Data
Apr 08, 2024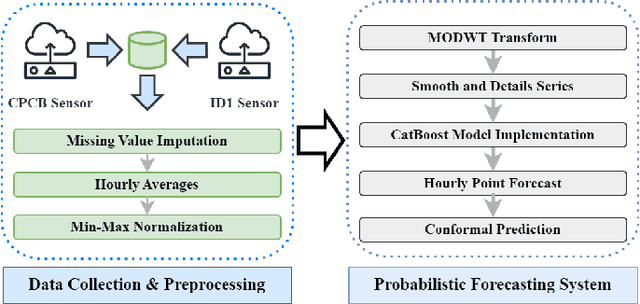

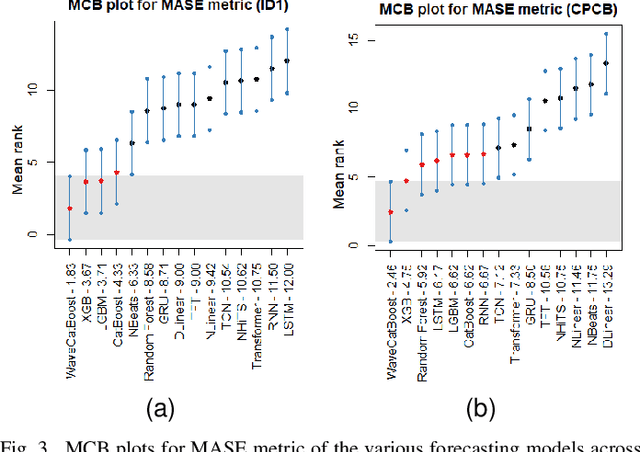
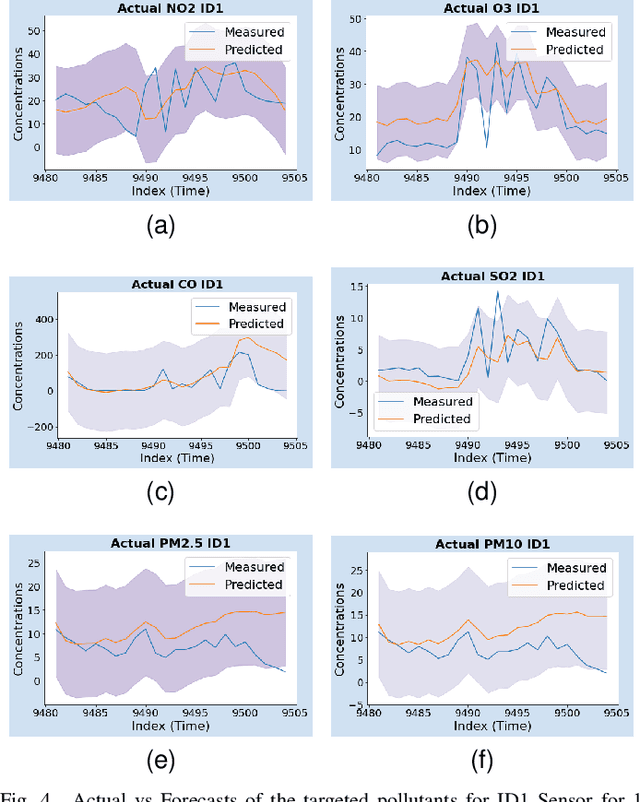
Accurate and reliable air quality forecasting is essential for protecting public health, sustainable development, pollution control, and enhanced urban planning. This letter presents a novel WaveCatBoost architecture designed to forecast the real-time concentrations of air pollutants by combining the maximal overlapping discrete wavelet transform (MODWT) with the CatBoost model. This hybrid approach efficiently transforms time series into high-frequency and low-frequency components, thereby extracting signal from noise and improving prediction accuracy and robustness. Evaluation of two distinct regional datasets, from the Central Air Pollution Control Board (CPCB) sensor network and a low-cost air quality sensor system (LAQS), underscores the superior performance of our proposed methodology in real-time forecasting compared to the state-of-the-art statistical and deep learning architectures. Moreover, we employ a conformal prediction strategy to provide probabilistic bands with our forecasts.
Survival modeling using deep learning, machine learning and statistical methods: A comparative analysis for predicting mortality after hospital admission
Mar 04, 2024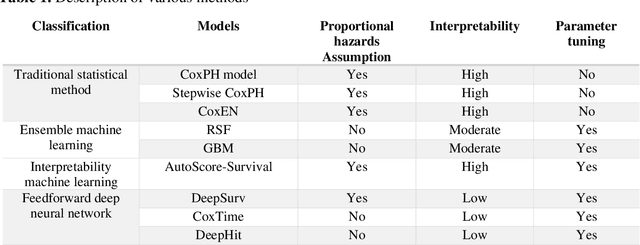
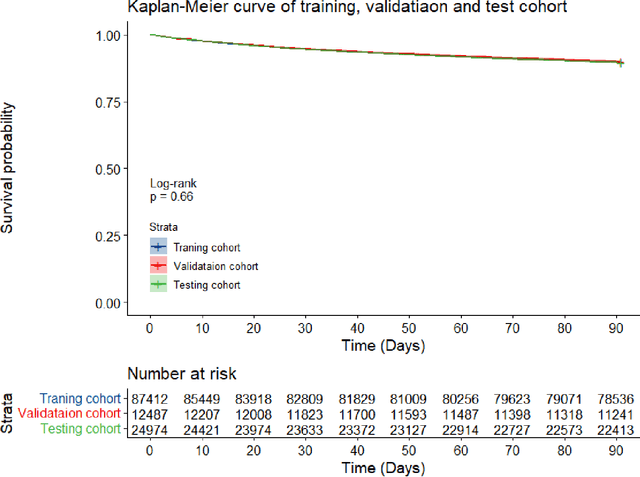
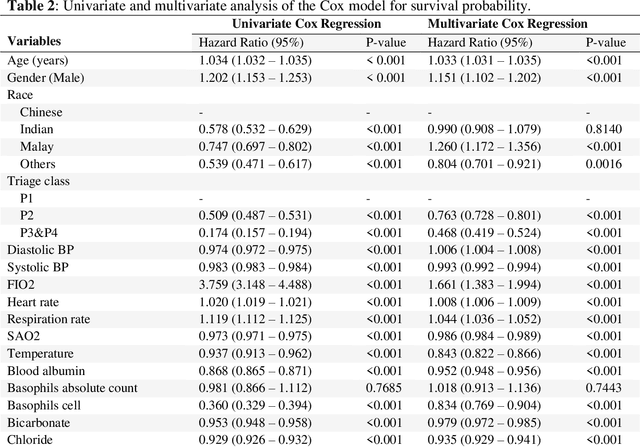
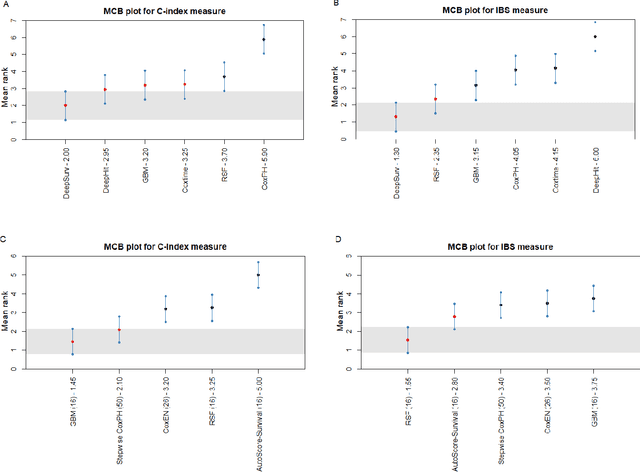
Survival analysis is essential for studying time-to-event outcomes and providing a dynamic understanding of the probability of an event occurring over time. Various survival analysis techniques, from traditional statistical models to state-of-the-art machine learning algorithms, support healthcare intervention and policy decisions. However, there remains ongoing discussion about their comparative performance. We conducted a comparative study of several survival analysis methods, including Cox proportional hazards (CoxPH), stepwise CoxPH, elastic net penalized Cox model, Random Survival Forests (RSF), Gradient Boosting machine (GBM) learning, AutoScore-Survival, DeepSurv, time-dependent Cox model based on neural network (CoxTime), and DeepHit survival neural network. We applied the concordance index (C-index) for model goodness-of-fit, and integral Brier scores (IBS) for calibration, and considered the model interpretability. As a case study, we performed a retrospective analysis of patients admitted through the emergency department of a tertiary hospital from 2017 to 2019, predicting 90-day all-cause mortality based on patient demographics, clinicopathological features, and historical data. The results of the C-index indicate that deep learning achieved comparable performance, with DeepSurv producing the best discrimination (DeepSurv: 0.893; CoxTime: 0.892; DeepHit: 0.891). The calibration of DeepSurv (IBS: 0.041) performed the best, followed by RSF (IBS: 0.042) and GBM (IBS: 0.0421), all using the full variables. Moreover, AutoScore-Survival, using a minimal variable subset, is easy to interpret, and can achieve good discrimination and calibration (C-index: 0.867; IBS: 0.044). While all models were satisfactory, DeepSurv exhibited the best discrimination and calibration. In addition, AutoScore-Survival offers a more parsimonious model and excellent interpretability.
When Geoscience Meets Generative AI and Large Language Models: Foundations, Trends, and Future Challenges
Jan 25, 2024Generative Artificial Intelligence (GAI) represents an emerging field that promises the creation of synthetic data and outputs in different modalities. GAI has recently shown impressive results across a large spectrum of applications ranging from biology, medicine, education, legislation, computer science, and finance. As one strives for enhanced safety, efficiency, and sustainability, generative AI indeed emerges as a key differentiator and promises a paradigm shift in the field. This paper explores the potential applications of generative AI and large language models in geoscience. The recent developments in the field of machine learning and deep learning have enabled the generative model's utility for tackling diverse prediction problems, simulation, and multi-criteria decision-making challenges related to geoscience and Earth system dynamics. This survey discusses several GAI models that have been used in geoscience comprising generative adversarial networks (GANs), physics-informed neural networks (PINNs), and generative pre-trained transformer (GPT)-based structures. These tools have helped the geoscience community in several applications, including (but not limited to) data generation/augmentation, super-resolution, panchromatic sharpening, haze removal, restoration, and land surface changing. Some challenges still remain such as ensuring physical interpretation, nefarious use cases, and trustworthiness. Beyond that, GAI models show promises to the geoscience community, especially with the support to climate change, urban science, atmospheric science, marine science, and planetary science through their extraordinary ability to data-driven modeling and uncertainty quantification.
Skew Probabilistic Neural Networks for Learning from Imbalanced Data
Dec 10, 2023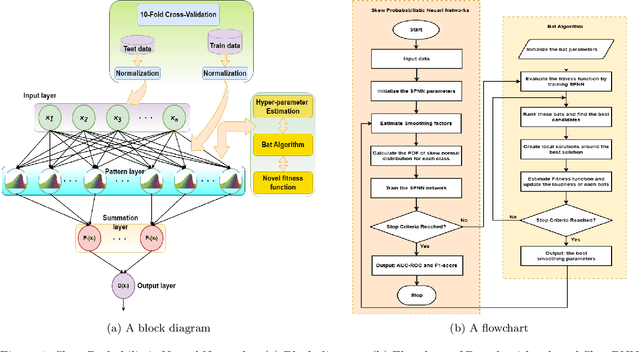



Real-world datasets often exhibit imbalanced data distribution, where certain class levels are severely underrepresented. In such cases, traditional pattern classifiers have shown a bias towards the majority class, impeding accurate predictions for the minority class. This paper introduces an imbalanced data-oriented approach using probabilistic neural networks (PNNs) with a skew normal probability kernel to address this major challenge. PNNs are known for providing probabilistic outputs, enabling quantification of prediction confidence and uncertainty handling. By leveraging the skew normal distribution, which offers increased flexibility, particularly for imbalanced and non-symmetric data, our proposed Skew Probabilistic Neural Networks (SkewPNNs) can better represent underlying class densities. To optimize the performance of the proposed approach on imbalanced datasets, hyperparameter fine-tuning is imperative. To this end, we employ a population-based heuristic algorithm, Bat optimization algorithms, for effectively exploring the hyperparameter space. We also prove the statistical consistency of the density estimates which suggests that the true distribution will be approached smoothly as the sample size increases. Experimental simulations have been conducted on different synthetic datasets, comparing various benchmark-imbalanced learners. Our real-data analysis shows that SkewPNNs substantially outperform state-of-the-art machine learning methods for both balanced and imbalanced datasets in most experimental settings.