 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADP-RME: A Trust-Adaptive Differential Privacy Framework for Enhancing Reliability of Data-Driven Systems
Apr 09, 2026Ensuring reliability in adversarial settings necessitates treating privacy as a foundational component of data-driven systems. While differential privacy and cryptographic protocols offer strong guarantees, existing schemes rely on a fixed privacy budget, leading to a rigid utility-privacy trade-off that fails under heterogeneous user trust. Moreover, noise-only differential privacy preserves geometric structure, which inference attacks exploit, causing privacy leakage. We propose TADP-RME (Trust-Adaptive Differential Privacy with Reverse Manifold Embedding), a framework that enhances reliability under varying levels of user trust. It introduces an inverse trust score in the range [0,1] to adaptively modulate the privacy budget, enabling smooth transitions between utility and privacy. Additionally, Reverse Manifold Embedding applies a nonlinear transformation to disrupt local geometric relationships while preserving formal differential privacy guarantees through post-processing. Theoretical and empirical results demonstrate improved privacy-utility trade-offs, reducing attack success rates by up to 3.1 percent without significant utility degradation. The framework consistently outperforms existing methods against inference attacks, providing a unified approach for reliable learning in adversarial environments.
Demystifying the trend of the healthcare index: Is historical price a key driver?
Jan 20, 2026Healthcare sector indices consolidate the economic health of pharmaceutical, biotechnology, and healthcare service firms. The short-term movements in these indices are closely intertwined with capital allocation decisions affecting research and development investment, drug availability, and long-term health outcomes. This research investigates whether historical open-high-low-close (OHLC) index data contain sufficient information for predicting the directional movement of the opening index on the subsequent trading day. The problem is formulated as a supervised classification task involving a one-step-ahead rolling window. A diverse feature set is constructed, comprising original prices, volatility-based technical indicators, and a novel class of nowcasting features derived from mutual OHLC ratios. The framework is evaluated on data from healthcare indices in the U.S. and Indian markets over a five-year period spanning multiple economic phases, including the COVID-19 pandemic. The results demonstrate robust predictive performance, with accuracy exceeding 0.8 and Matthews correlation coefficients above 0.6. Notably, the proposed nowcasting features have emerged as a key determinant of the market movement. We have employed the Shapley-based explainability paradigm to further elucidate the contribution of the features: outcomes reveal the dominant role of the nowcasting features, followed by a more moderate contribution of original prices. This research offers a societal utility: the proposed features and model for short-term forecasting of healthcare indices can reduce information asymmetry and support a more stable and equitable health economy.
Footprints of Data in a Classifier Model: The Privacy Issues and Their Mitigation through Data Obfuscation
Jul 02, 2024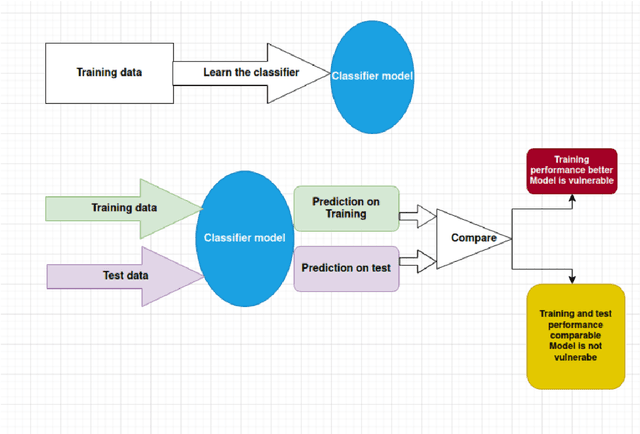
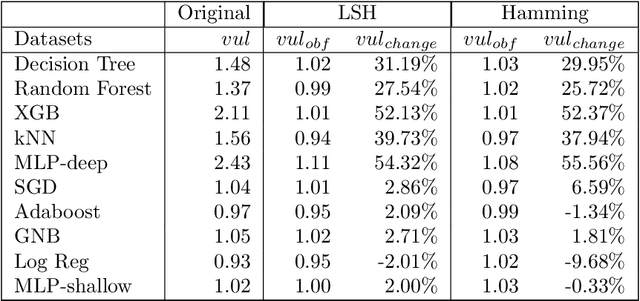
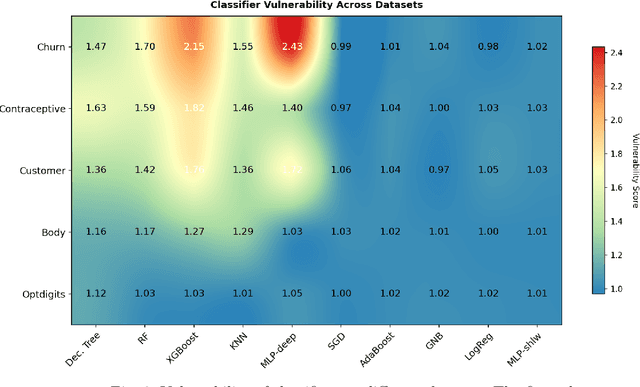
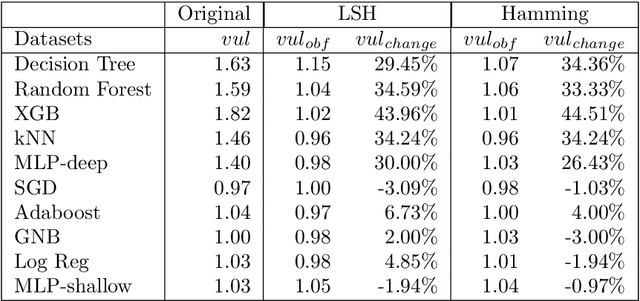
The avalanche of AI deployment and its security-privacy concerns are two sides of the same coin. Article 17 of GDPR calls for the Right to Erasure; data has to be obliterated from a system to prevent its compromise. Extant research in this aspect focuses on effacing sensitive data attributes. However, several passive modes of data compromise are yet to be recognized and redressed. The embedding of footprints of training data in a prediction model is one such facet; the difference in performance quality in test and training data causes passive identification of data that have trained the model. This research focuses on addressing the vulnerability arising from the data footprints. The three main aspects are -- i] exploring the vulnerabilities of different classifiers (to segregate the vulnerable and the non-vulnerable ones), ii] reducing the vulnerability of vulnerable classifiers (through data obfuscation) to preserve model and data privacy, and iii] exploring the privacy-performance tradeoff to study the usability of the data obfuscation techniques. An empirical study is conducted on three datasets and eight classifiers to explore the above objectives. The results of the initial research identify the vulnerability in classifiers and segregate the vulnerable and non-vulnerable classifiers. The additional experiments on data obfuscation techniques reveal their utility to render data and model privacy and also their capability to chalk out a privacy-performance tradeoff in most scenarios. The results can aid the practitioners with their choice of classifiers in different scenarios and contexts.
Reconnoitering the class distinguishing abilities of the features, to know them better
Nov 23, 2022



The relevance of machine learning (ML) in our daily lives is closely intertwined with its explainability. Explainability can allow end-users to have a transparent and humane reckoning of a ML scheme's capability and utility. It will also foster the user's confidence in the automated decisions of a system. Explaining the variables or features to explain a model's decision is a need of the present times. We could not really find any work, which explains the features on the basis of their class-distinguishing abilities (specially when the real world data are mostly of multi-class nature). In any given dataset, a feature is not equally good at making distinctions between the different possible categorizations (or classes) of the data points. In this work, we explain the features on the basis of their class or category-distinguishing capabilities. We particularly estimate the class-distinguishing capabilities (scores) of the variables for pair-wise class combinations. We validate the explainability given by our scheme empirically on several real-world, multi-class datasets. We further utilize the class-distinguishing scores in a latent feature context and propose a novel decision making protocol. Another novelty of this work lies with a \emph{refuse to render decision} option when the latent variable (of the test point) has a high class-distinguishing potential for the likely classes.
Random Walk-steered Majority Undersampling
Sep 25, 2021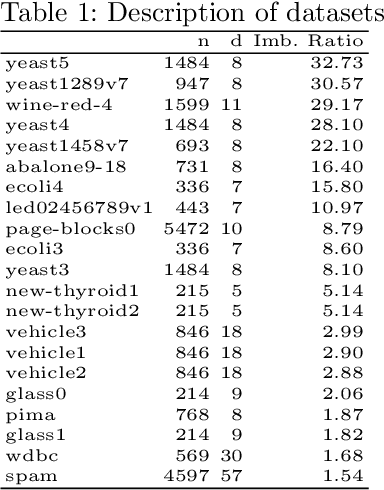
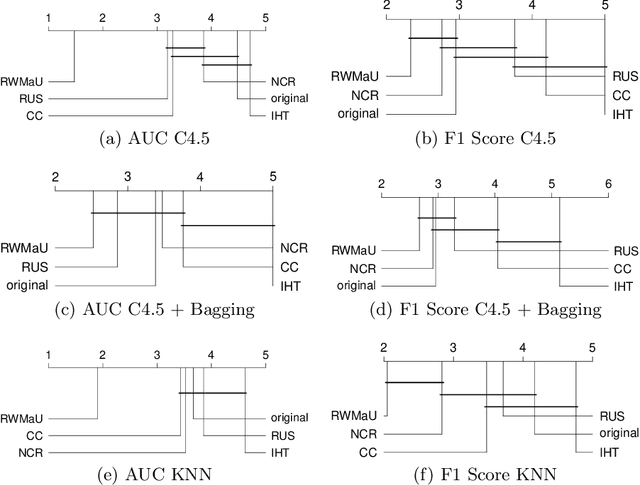
In this work, we propose Random Walk-steered Majority Undersampling (RWMaU), which undersamples the majority points of a class imbalanced dataset, in order to balance the classes. Rather than marking the majority points which belong to the neighborhood of a few minority points, we are interested to perceive the closeness of the majority points to the minority class. Random walk, a powerful tool for perceiving the proximities of connected points in a graph, is used to identify the majority points which lie close to the minority class of a class-imbalanced dataset. The visit frequencies and the order of visits of the majority points in the walks enable us to perceive an overall closeness of the majority points to the minority class. The ones lying close to the minority class are subsequently undersampled. Empirical evaluation on 21 datasets and 3 classifiers demonstrate substantial improvement in performance of RWMaU over the competing methods.
Integrating Unsupervised Clustering and Label-specific Oversampling to Tackle Imbalanced Multi-label Data
Sep 25, 2021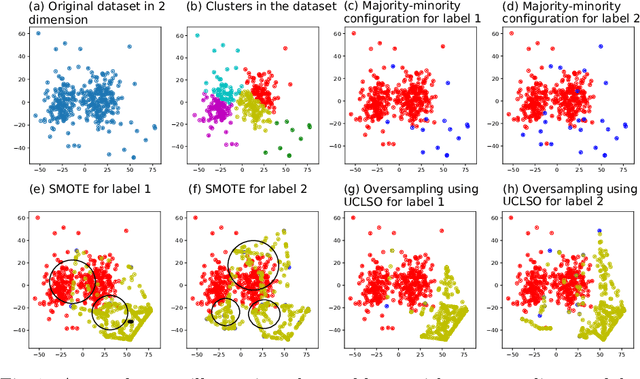
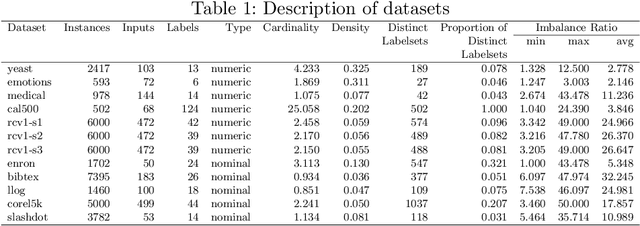
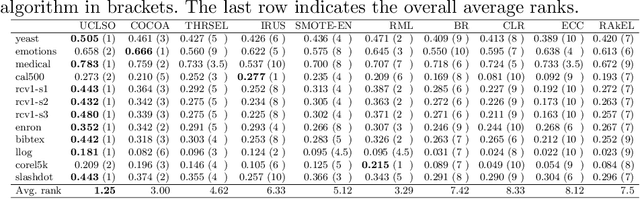
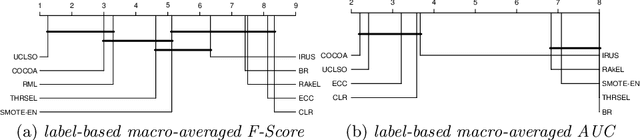
There is often a mixture of very frequent labels and very infrequent labels in multi-label datatsets. This variation in label frequency, a type class imbalance, creates a significant challenge for building efficient multi-label classification algorithms. In this paper, we tackle this problem by proposing a minority class oversampling scheme, UCLSO, which integrates Unsupervised Clustering and Label-Specific data Oversampling. Clustering is performed to find out the key distinct and locally connected regions of a multi-label dataset (irrespective of the label information). Next, for each label, we explore the distributions of minority points in the cluster sets. Only the minority points within a cluster are used to generate the synthetic minority points that are used for oversampling. Even though the cluster set is the same across all labels, the distributions of the synthetic minority points will vary across the labels. The training dataset is augmented with the set of label-specific synthetic minority points, and classifiers are trained to predict the relevance of each label independently. Experiments using 12 multi-label datasets and several multi-label algorithms show that the proposed method performed very well compared to the other competing algorithms.