 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFootprints of Data in a Classifier Model: The Privacy Issues and Their Mitigation through Data Obfuscation
Paper and Code
Jul 02, 2024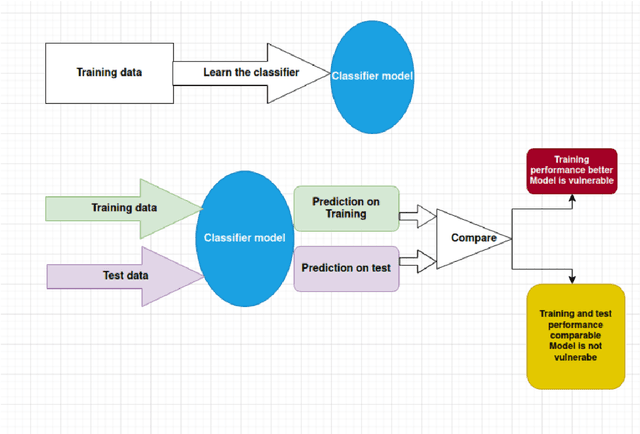
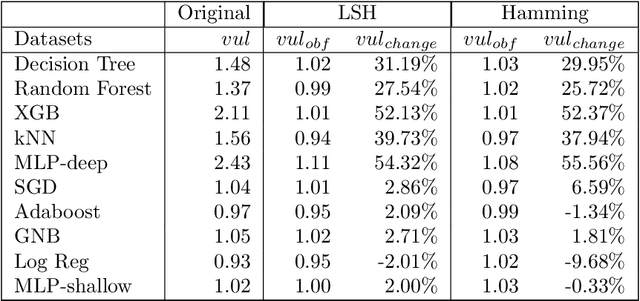
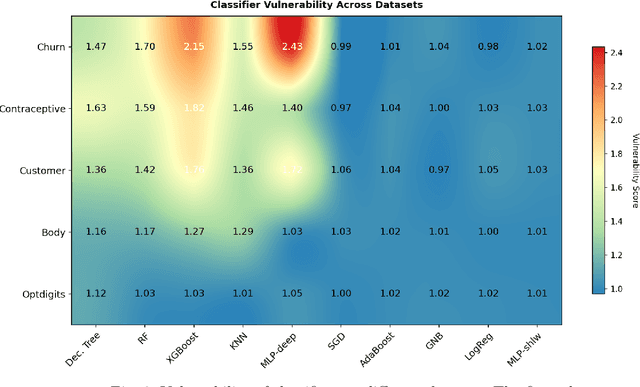
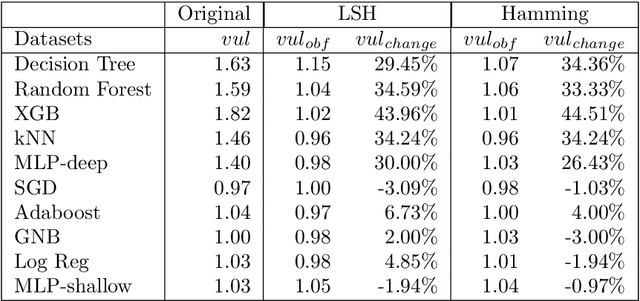
The avalanche of AI deployment and its security-privacy concerns are two sides of the same coin. Article 17 of GDPR calls for the Right to Erasure; data has to be obliterated from a system to prevent its compromise. Extant research in this aspect focuses on effacing sensitive data attributes. However, several passive modes of data compromise are yet to be recognized and redressed. The embedding of footprints of training data in a prediction model is one such facet; the difference in performance quality in test and training data causes passive identification of data that have trained the model. This research focuses on addressing the vulnerability arising from the data footprints. The three main aspects are -- i] exploring the vulnerabilities of different classifiers (to segregate the vulnerable and the non-vulnerable ones), ii] reducing the vulnerability of vulnerable classifiers (through data obfuscation) to preserve model and data privacy, and iii] exploring the privacy-performance tradeoff to study the usability of the data obfuscation techniques. An empirical study is conducted on three datasets and eight classifiers to explore the above objectives. The results of the initial research identify the vulnerability in classifiers and segregate the vulnerable and non-vulnerable classifiers. The additional experiments on data obfuscation techniques reveal their utility to render data and model privacy and also their capability to chalk out a privacy-performance tradeoff in most scenarios. The results can aid the practitioners with their choice of classifiers in different scenarios and contexts.