 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Unsupervised Clustering and Label-specific Oversampling to Tackle Imbalanced Multi-label Data
Sep 25, 2021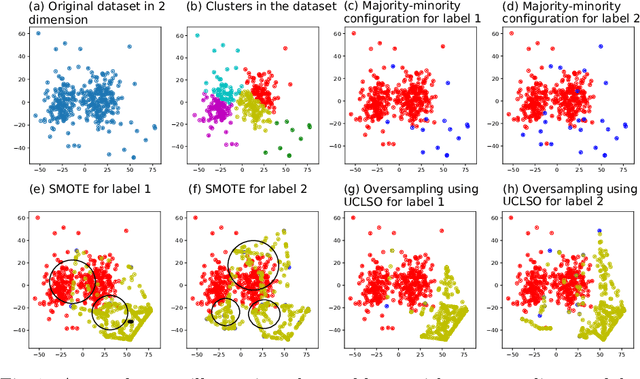
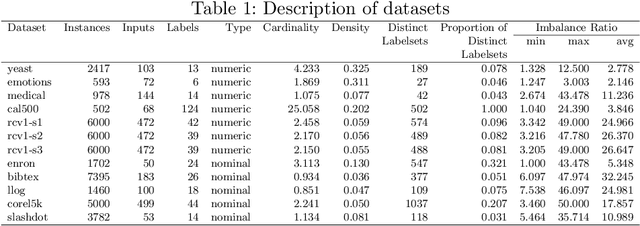
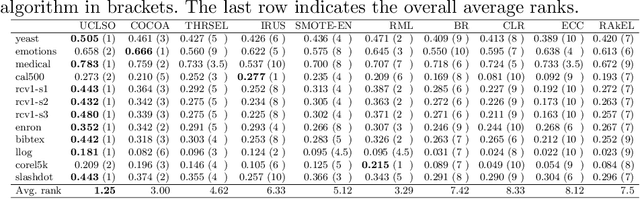
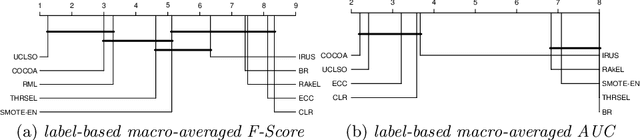
There is often a mixture of very frequent labels and very infrequent labels in multi-label datatsets. This variation in label frequency, a type class imbalance, creates a significant challenge for building efficient multi-label classification algorithms. In this paper, we tackle this problem by proposing a minority class oversampling scheme, UCLSO, which integrates Unsupervised Clustering and Label-Specific data Oversampling. Clustering is performed to find out the key distinct and locally connected regions of a multi-label dataset (irrespective of the label information). Next, for each label, we explore the distributions of minority points in the cluster sets. Only the minority points within a cluster are used to generate the synthetic minority points that are used for oversampling. Even though the cluster set is the same across all labels, the distributions of the synthetic minority points will vary across the labels. The training dataset is augmented with the set of label-specific synthetic minority points, and classifiers are trained to predict the relevance of each label independently. Experiments using 12 multi-label datasets and several multi-label algorithms show that the proposed method performed very well compared to the other competing algorithms.