 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Potential of Bilevel Optimization for Calibrating Neural Networks
Mar 17, 2025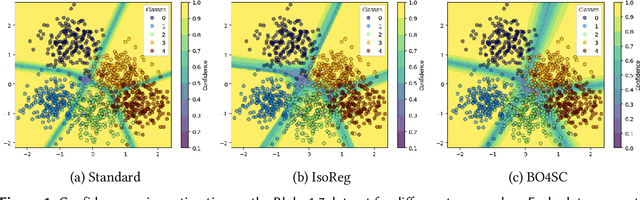
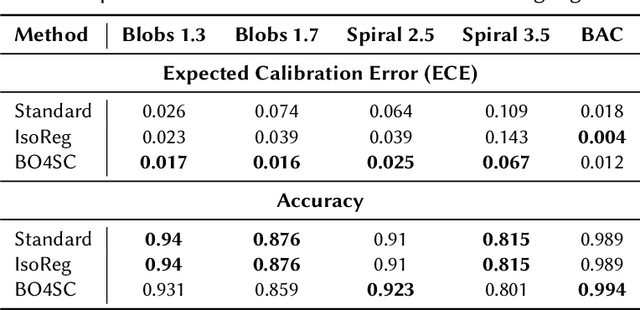
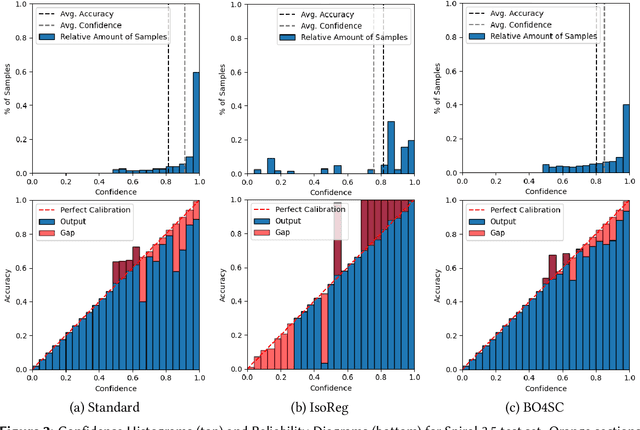
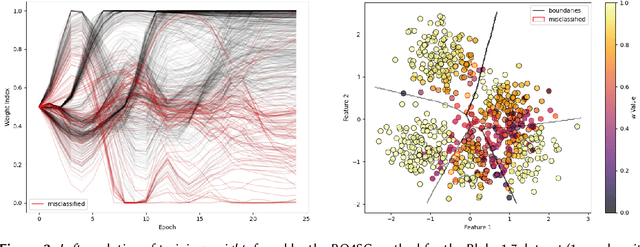
Handling uncertainty is critical for ensuring reliable decision-making in intelligent systems. Modern neural networks are known to be poorly calibrated, resulting in predicted confidence scores that are difficult to use. This article explores improving confidence estimation and calibration through the application of bilevel optimization, a framework designed to solve hierarchical problems with interdependent optimization levels. A self-calibrating bilevel neural-network training approach is introduced to improve a model's predicted confidence scores. The effectiveness of the proposed framework is analyzed using toy datasets, such as Blobs and Spirals, as well as more practical simulated datasets, such as Blood Alcohol Concentration (BAC). It is compared with a well-known and widely used calibration strategy, isotonic regression. The reported experimental results reveal that the proposed bilevel optimization approach reduces the calibration error while preserving accuracy.
Counterfactual Explanations for Misclassified Images: How Human and Machine Explanations Differ
Dec 16, 2022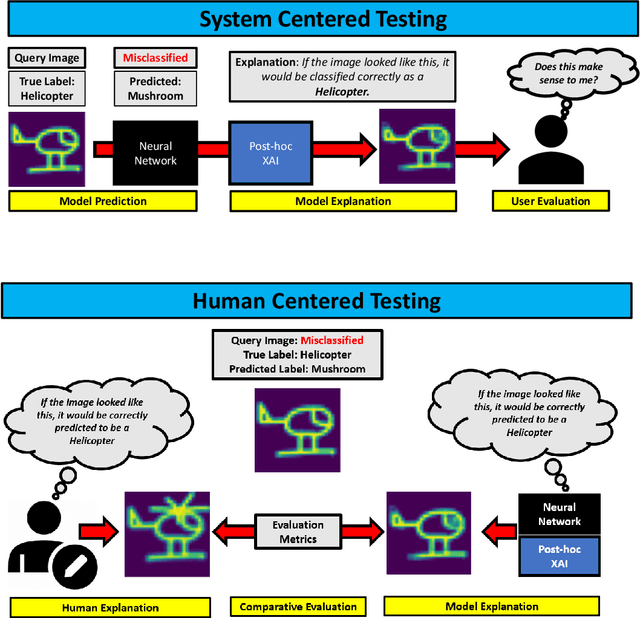
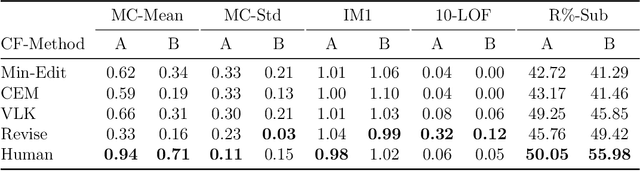
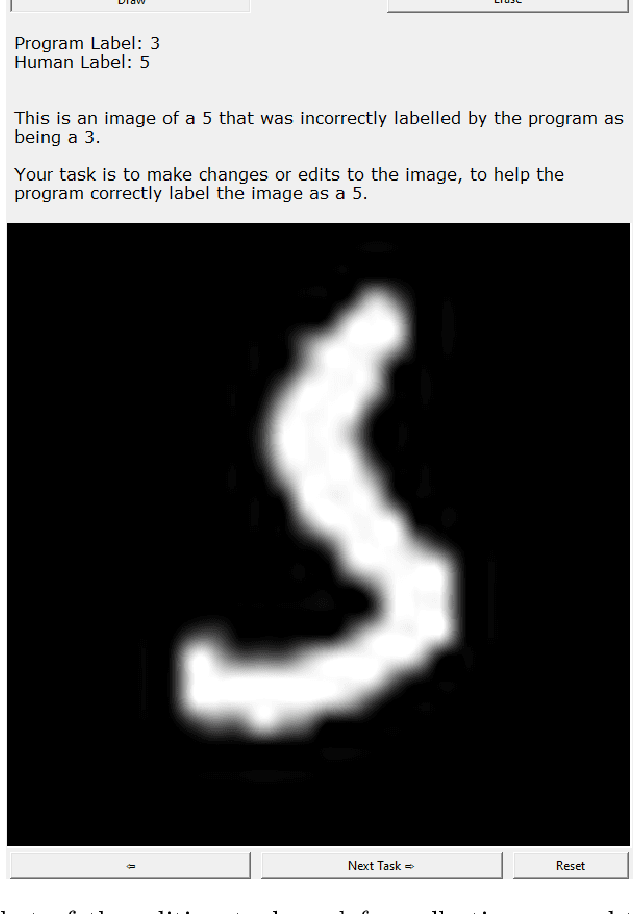
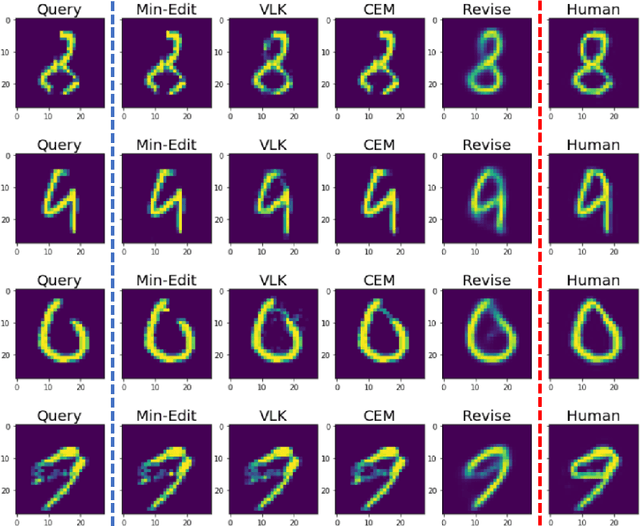
Counterfactual explanations have emerged as a popular solution for the eXplainable AI (XAI) problem of elucidating the predictions of black-box deep-learning systems due to their psychological validity, flexibility across problem domains and proposed legal compliance. While over 100 counterfactual methods exist, claiming to generate plausible explanations akin to those preferred by people, few have actually been tested on users ($\sim7\%$). So, the psychological validity of these counterfactual algorithms for effective XAI for image data is not established. This issue is addressed here using a novel methodology that (i) gathers ground truth human-generated counterfactual explanations for misclassified images, in two user studies and, then, (ii) compares these human-generated ground-truth explanations to computationally-generated explanations for the same misclassifications. Results indicate that humans do not "minimally edit" images when generating counterfactual explanations. Instead, they make larger, "meaningful" edits that better approximate prototypes in the counterfactual class.
Random Walk-steered Majority Undersampling
Sep 25, 2021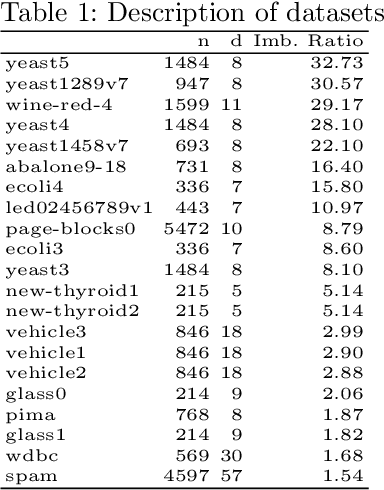
In this work, we propose Random Walk-steered Majority Undersampling (RWMaU), which undersamples the majority points of a class imbalanced dataset, in order to balance the classes. Rather than marking the majority points which belong to the neighborhood of a few minority points, we are interested to perceive the closeness of the majority points to the minority class. Random walk, a powerful tool for perceiving the proximities of connected points in a graph, is used to identify the majority points which lie close to the minority class of a class-imbalanced dataset. The visit frequencies and the order of visits of the majority points in the walks enable us to perceive an overall closeness of the majority points to the minority class. The ones lying close to the minority class are subsequently undersampled. Empirical evaluation on 21 datasets and 3 classifiers demonstrate substantial improvement in performance of RWMaU over the competing methods.
Integrating Unsupervised Clustering and Label-specific Oversampling to Tackle Imbalanced Multi-label Data
Sep 25, 2021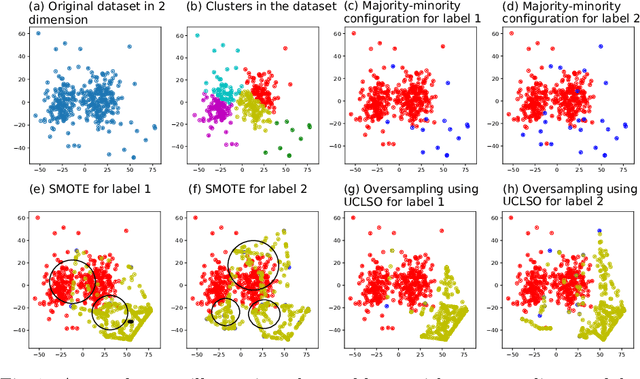
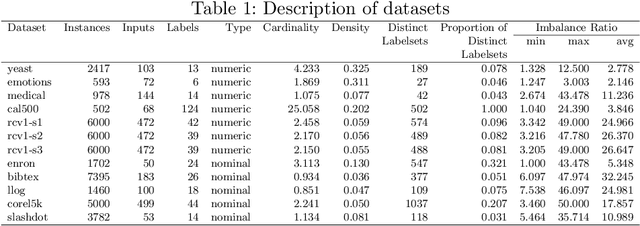
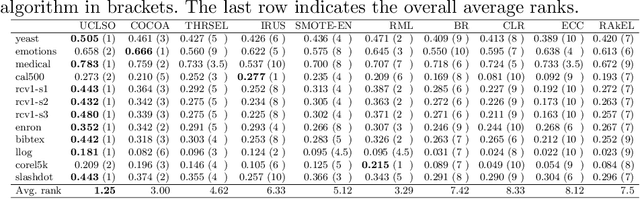
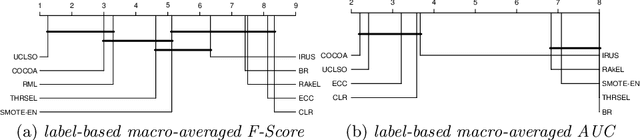
There is often a mixture of very frequent labels and very infrequent labels in multi-label datatsets. This variation in label frequency, a type class imbalance, creates a significant challenge for building efficient multi-label classification algorithms. In this paper, we tackle this problem by proposing a minority class oversampling scheme, UCLSO, which integrates Unsupervised Clustering and Label-Specific data Oversampling. Clustering is performed to find out the key distinct and locally connected regions of a multi-label dataset (irrespective of the label information). Next, for each label, we explore the distributions of minority points in the cluster sets. Only the minority points within a cluster are used to generate the synthetic minority points that are used for oversampling. Even though the cluster set is the same across all labels, the distributions of the synthetic minority points will vary across the labels. The training dataset is augmented with the set of label-specific synthetic minority points, and classifiers are trained to predict the relevance of each label independently. Experiments using 12 multi-label datasets and several multi-label algorithms show that the proposed method performed very well compared to the other competing algorithms.
The Deep Radial Basis Function Data Descriptor (D-RBFDD) Network: A One-Class Neural Network for Anomaly Detection
Jan 29, 2021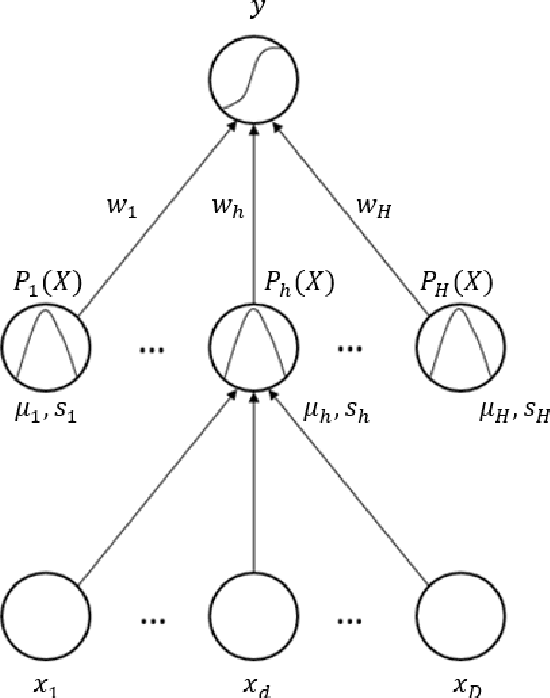
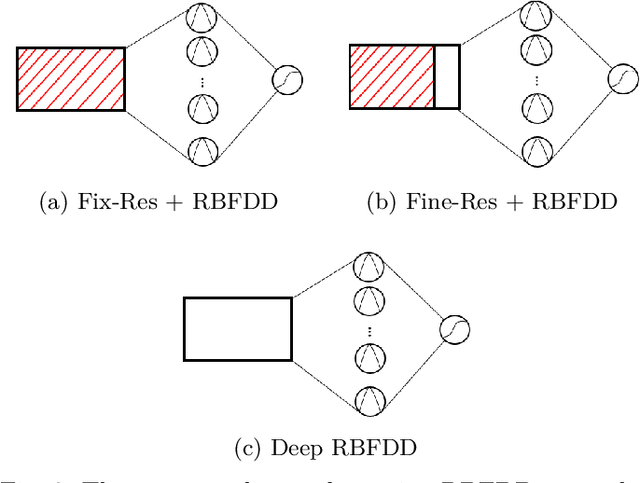
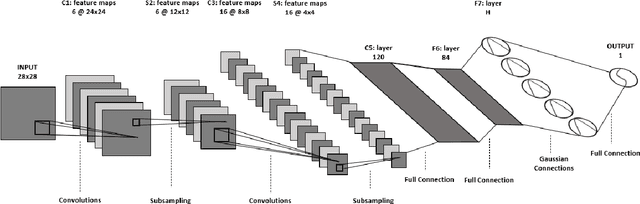
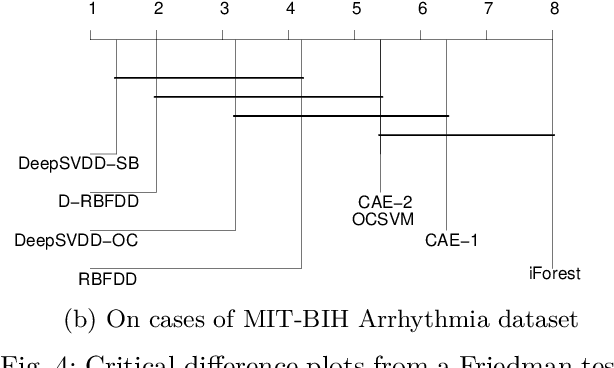
Anomaly detection is a challenging problem in machine learning, and is even more so when dealing with instances that are captured in low-level, raw data representations without a well-behaved set of engineered features. The Radial Basis Function Data Descriptor (RBFDD) network is an effective solution for anomaly detection, however, it is a shallow model that does not deal effectively with raw data representations. This paper investigates approaches to modifying the RBFDD network to transform it into a deep one-class classifier suitable for anomaly detection problems with low-level raw data representations. We show that approaches based on transfer learning are not effective and our results suggest that this is because the latent representations learned by generic classification models are not suitable for anomaly detection. Instead we show that an approach that adds multiple convolutional layers before the RBF layer, to form a Deep Radial Basis Function Data Descriptor (D-RBFDD) network, is very effective. This is shown in a set of evaluation experiments using multiple anomaly detection scenarios created from publicly available image classification datasets, and a real-world anomaly detection dataset in which different types of arrhythmia are detected in electrocardiogram (ECG) data. Our experiments show that the D-RBFDD network out-performs state-of-the-art anomaly detection methods including the Deep Support Vector Data Descriptor (Deep SVDD), One-Class SVM, and Isolation Forest on the image datasets, and produces competitive results for the ECG dataset.
Ramifications of Approximate Posterior Inference for Bayesian Deep Learning in Adversarial and Out-of-Distribution Settings
Oct 03, 2020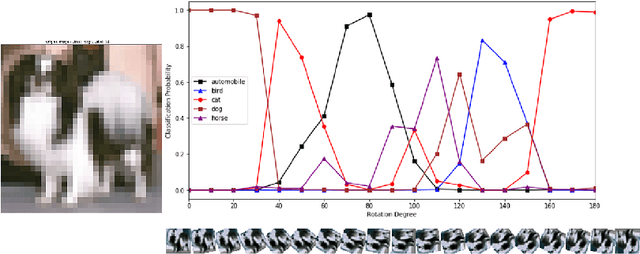
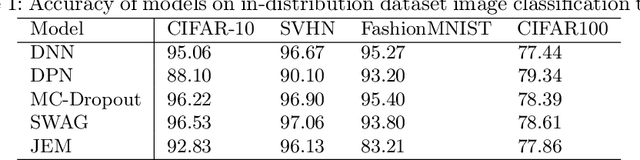
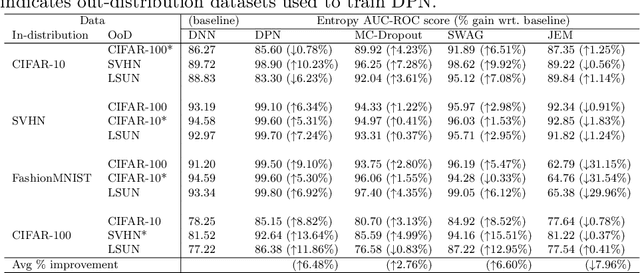
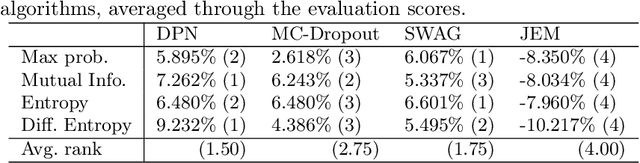
Deep neural networks have been successful in diverse discriminative classification tasks, although, they are poorly calibrated often assigning high probability to misclassified predictions. Potential consequences could lead to trustworthiness and accountability of the models when deployed in real applications, where predictions are evaluated based on their confidence scores. Existing solutions suggest the benefits attained by combining deep neural networks and Bayesian inference to quantify uncertainty over the models' predictions for ambiguous datapoints. In this work we propose to validate and test the efficacy of likelihood based models in the task of out of distribution detection (OoD). Across different datasets and metrics we show that Bayesian deep learning models on certain occasions marginally outperform conventional neural networks and in the event of minimal overlap between in/out distribution classes, even the best models exhibit a reduction in AUC scores in detecting OoD data. Preliminary investigations indicate the potential inherent role of bias due to choices of initialisation, architecture or activation functions. We hypothesise that the sensitivity of neural networks to unseen inputs could be a multi-factor phenomenon arising from the different architectural design choices often amplified by the curse of dimensionality. Furthermore, we perform a study to find the effect of the adversarial noise resistance methods on in and out-of-distribution performance, as well as, also investigate adversarial noise robustness of Bayesian deep learners.
KFHE-HOMER: Kalman Filter-based Heuristic Ensemble of HOMER for Multi-Label Classification
Apr 23, 2019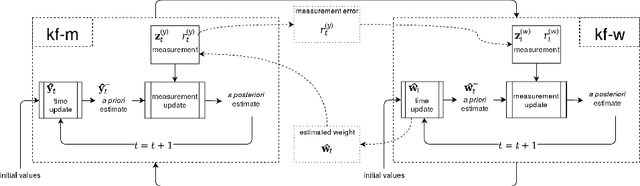
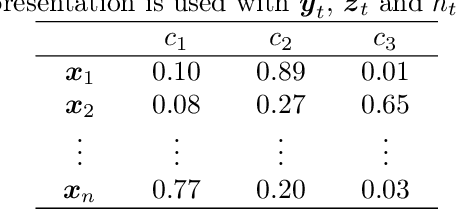
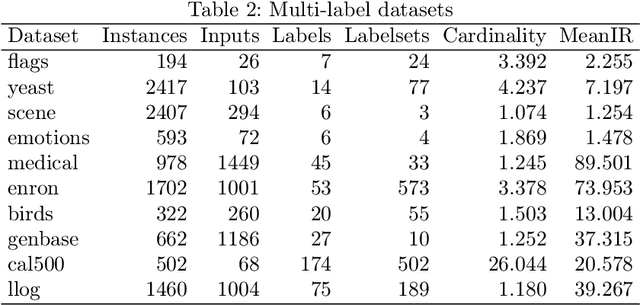

Multi-label classification allows a datapoint to be labelled with more than one class at the same time. Ensemble methods generally perform much better than single classifiers. Except bagging style ensembles like ECC, RAkEL, in multi-label classification, other ensemble methods have not been explored much. KFHE (Kalman Filter-based Heuristic Ensemble), is a recent ensemble method which uses the Kalman filter to combine several models. KFHE views the final ensemble to be learned as a state to be estimated which it estimates using multiple noisy "measurements". These "measurements" are essentially component classifiers trained under different settings. This work extends KFHE to multi-label domain by proposing KFHE-HOMER which enhances the performance of HOMER using the KFHE framework. KFHE-HOMER sequentially trains multiple HOMER classifiers using weighted training datapoints and random hyperparameters. These models are considered as measurements and their related error as the uncertainty of the measurements. Then the Kalman filter framework is used to combine these measurements to get a more accurate estimate. The method was tested on 10 multi-label datasets and compared with other multi-label classification algorithms. Results show that KFHE-HOMER performs consistently better than similar multi-label ensemble methods.
CascadeML: An Automatic Neural Network Architecture Evolution and Training Algorithm for Multi-label Classification
Apr 23, 2019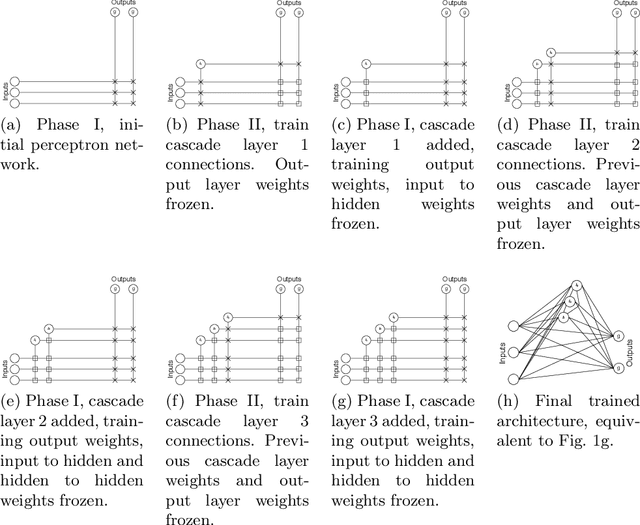


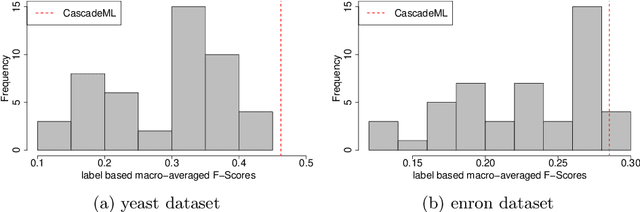
Multi-label classification is an approach which allows a datapoint to be labelled with more than one class at the same time. A common but trivial approach is to train individual binary classifiers per label, but the performance can be improved by considering associations within the labels. Like with any machine learning algorithm, hyperparameter tuning is important to train a good multi-label classifier model. The task of selecting the best hyperparameter settings for an algorithm is an optimisation problem. Very limited work has been done on automatic hyperparameter tuning and AutoML in the multi-label domain. This paper attempts to fill this gap by proposing a neural network algorithm, CascadeML, to train multi-label neural network based on cascade neural networks. This method requires minimal or no hyperparameter tuning and also considers pairwise label associations. The cascade algorithm grows the network architecture incrementally in a two phase process as it learns the weights using adaptive first order gradient algorithm, therefore omitting the requirement of preselecting the number of hidden layers, nodes and the learning rate. The method was tested on 10 multi-label datasets and compared with other multi-label classification algorithms. Results show that CascadeML performs very well without hyperparameter tuning.
A Kalman filtering induced heuristic optimization based partitional data clustering
Jan 25, 2019

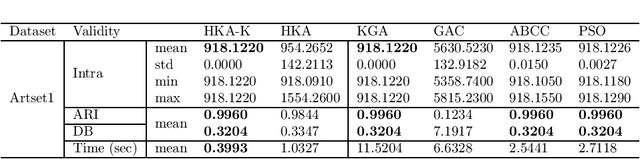
Clustering algorithms have regained momentum with recent popularity of data mining and knowledge discovery approaches. To obtain good clustering in reasonable amount of time, various meta-heuristic approaches and their hybridization, sometimes with K-Means technique, have been employed. A Kalman Filtering based heuristic approach called Heuristic Kalman Algorithm (HKA) has been proposed a few years ago, which may be used for optimizing an objective function in data/feature space. In this paper at first HKA is employed in partitional data clustering. Then an improved approach named HKA-K is proposed, which combines the benefits of global exploration of HKA and the fast convergence of K-Means method. Implemented and tested on several datasets from UCI machine learning repository, the results obtained by HKA-K were compared with other hybrid meta-heuristic clustering approaches. It is shown that HKA-K is atleast as good as and often better than the other compared algorithms.
Kalman Filter-based Heuristic Ensemble : A New Perspective on Multi-class Ensemble Classification Using Kalman Filters
Sep 29, 2018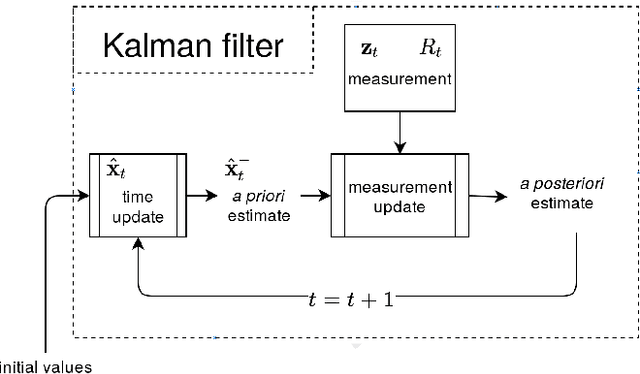
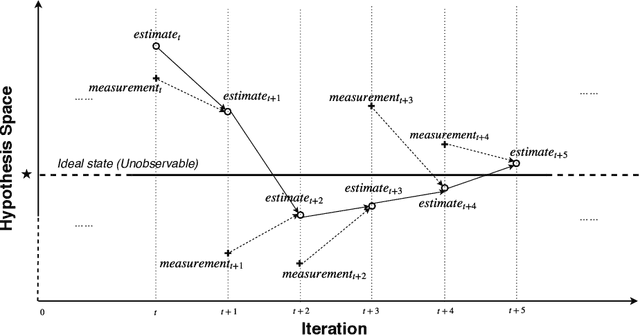
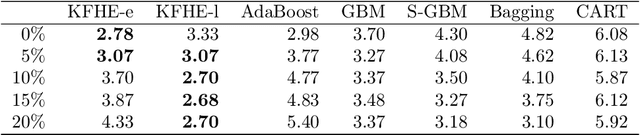
A classifier ensemble is a combination of multiple diverse classifier models whose outputs are aggregated into a single prediction. Ensembles have been repeatedly shown to perform better than single classifier models, however, existing approaches trade off performance and robustness to class label noise. The objective of this paper is to first introduce a new perspective on multi-class ensemble classification by considering the training of the ensemble as a state estimation problem. The new perspective considers the final ensemble classifier model as a static state, which can be estimated using a Kalman filter that combines noisy estimates made by individual classifier models. A new algorithm based on this perspective, Kalman Filter-based Heuristic Ensemble (KFHE), is also presented in this paper which shows the practical applicability of the new perspective. Experiments performed on 30 real-life datasets, comparing KFHE with state-of-the-art multi-class ensemble classification algorithms uncover the potential and effectiveness of the proposed new perspective and algorithm. KFHE is shown to be significantly better or at least as good as the state-of-the-art algorithms for datasets both with and without class label noise.