 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Ability of Explanations to Disambiguate Models in a Rashomon Set
Jan 13, 2026Explainable artificial intelligence (XAI) is concerned with producing explanations indicating the inner workings of models. For a Rashomon set of similarly performing models, explanations provide a way of disambiguating the behavior of individual models, helping select models for deployment. However explanations themselves can vary depending on the explainer used, and need to be evaluated. In the paper "Evaluating Model Explanations without Ground Truth", we proposed three principles of explanation evaluation and a new method "AXE" to evaluate the quality of feature-importance explanations. We go on to illustrate how evaluation metrics that rely on comparing model explanations against ideal ground truth explanations obscure behavioral differences within a Rashomon set. Explanation evaluation aligned with our proposed principles would highlight these differences instead, helping select models from the Rashomon set. The selection of alternate models from the Rashomon set can maintain identical predictions but mislead explainers into generating false explanations, and mislead evaluation methods into considering the false explanations to be of high quality. AXE, our proposed explanation evaluation method, can detect this adversarial fairwashing of explanations with a 100% success rate. Unlike prior explanation evaluation strategies such as those based on model sensitivity or ground truth comparison, AXE can determine when protected attributes are used to make predictions.
LLMs Don't Know Their Own Decision Boundaries: The Unreliability of Self-Generated Counterfactual Explanations
Sep 11, 2025To collaborate effectively with humans, language models must be able to explain their decisions in natural language. We study a specific type of self-explanation: self-generated counterfactual explanations (SCEs), where a model explains its prediction by modifying the input such that it would have predicted a different outcome. We evaluate whether LLMs can produce SCEs that are valid, achieving the intended outcome, and minimal, modifying the input no more than necessary. When asked to generate counterfactuals, we find that LLMs typically produce SCEs that are valid, but far from minimal, offering little insight into their decision-making behaviour. Worryingly, when asked to generate minimal counterfactuals, LLMs typically make excessively small edits that fail to change predictions. The observed validity-minimality trade-off is consistent across several LLMs, datasets, and evaluation settings. Our findings suggest that SCEs are, at best, an ineffective explainability tool and, at worst, can provide misleading insights into model behaviour. Proposals to deploy LLMs in high-stakes settings must consider the impact of unreliable self-explanations on downstream decision-making. Our code is available at https://github.com/HarryMayne/SCEs.
Evaluating Model Explanations without Ground Truth
May 15, 2025There can be many competing and contradictory explanations for a single model prediction, making it difficult to select which one to use. Current explanation evaluation frameworks measure quality by comparing against ideal "ground-truth" explanations, or by verifying model sensitivity to important inputs. We outline the limitations of these approaches, and propose three desirable principles to ground the future development of explanation evaluation strategies for local feature importance explanations. We propose a ground-truth Agnostic eXplanation Evaluation framework (AXE) for evaluating and comparing model explanations that satisfies these principles. Unlike prior approaches, AXE does not require access to ideal ground-truth explanations for comparison, or rely on model sensitivity - providing an independent measure of explanation quality. We verify AXE by comparing with baselines, and show how it can be used to detect explanation fairwashing. Our code is available at https://github.com/KaiRawal/Evaluating-Model-Explanations-without-Ground-Truth.
Resource-constrained Fairness
Jun 03, 2024Access to resources strongly constrains the decisions we make. While we might wish to offer every student a scholarship, or schedule every patient for follow-up meetings with a specialist, limited resources mean that this is not possible. Existing tools for fair machine learning ignore these key constraints, with the majority of methods disregarding any finite resource limitations under which decisions are made. Our research introduces the concept of ``resource-constrained fairness" and quantifies the cost of fairness within this framework. We demonstrate that the level of available resources significantly influences this cost, a factor that has been overlooked in previous evaluations.
Advancing Post Hoc Case Based Explanation with Feature Highlighting
Nov 06, 2023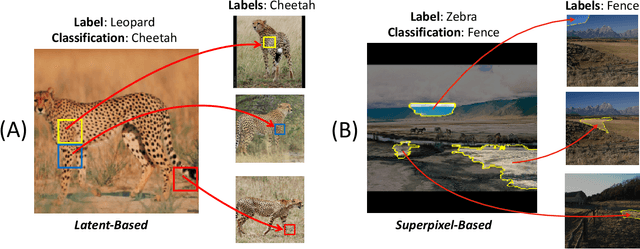
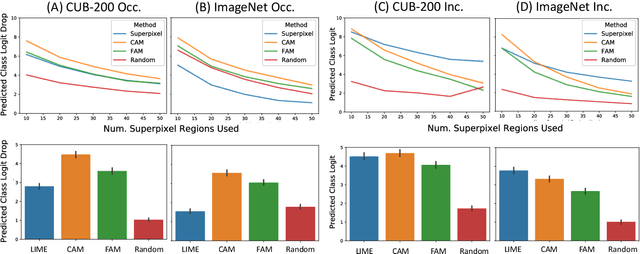
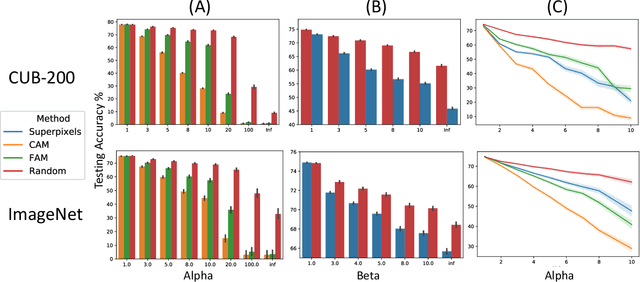
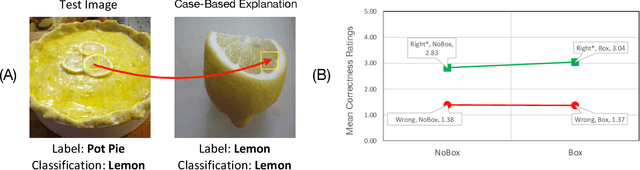
Explainable AI (XAI) has been proposed as a valuable tool to assist in downstream tasks involving human and AI collaboration. Perhaps the most psychologically valid XAI techniques are case based approaches which display 'whole' exemplars to explain the predictions of black box AI systems. However, for such post hoc XAI methods dealing with images, there has been no attempt to improve their scope by using multiple clear feature 'parts' of the images to explain the predictions while linking back to relevant cases in the training data, thus allowing for more comprehensive explanations that are faithful to the underlying model. Here, we address this gap by proposing two general algorithms (latent and super pixel based) which can isolate multiple clear feature parts in a test image, and then connect them to the explanatory cases found in the training data, before testing their effectiveness in a carefully designed user study. Results demonstrate that the proposed approach appropriately calibrates a users feelings of 'correctness' for ambiguous classifications in real world data on the ImageNet dataset, an effect which does not happen when just showing the explanation without feature highlighting.
Explaining Groups of Instances Counterfactually for XAI: A Use Case, Algorithm and User Study for Group-Counterfactuals
Mar 16, 2023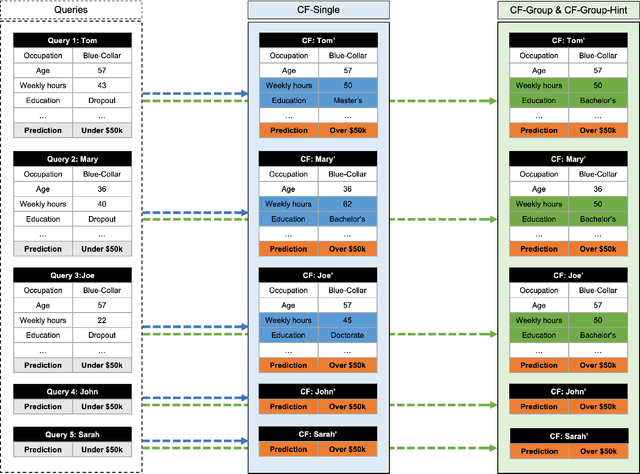
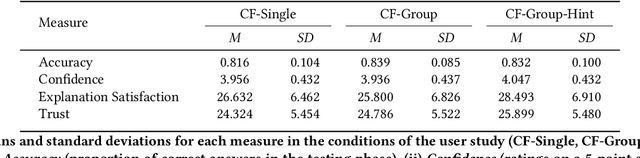

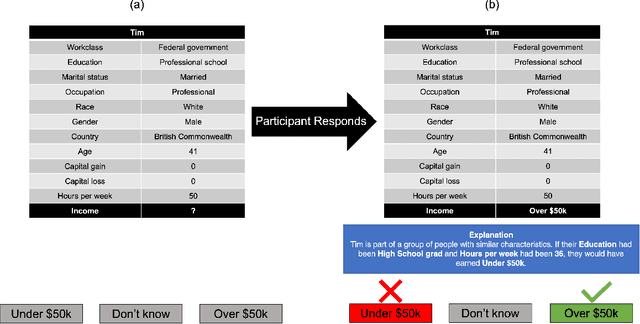
Counterfactual explanations are an increasingly popular form of post hoc explanation due to their (i) applicability across problem domains, (ii) proposed legal compliance (e.g., with GDPR), and (iii) reliance on the contrastive nature of human explanation. Although counterfactual explanations are normally used to explain individual predictive-instances, we explore a novel use case in which groups of similar instances are explained in a collective fashion using ``group counterfactuals'' (e.g., to highlight a repeating pattern of illness in a group of patients). These group counterfactuals meet a human preference for coherent, broad explanations covering multiple events/instances. A novel, group-counterfactual algorithm is proposed to generate high-coverage explanations that are faithful to the to-be-explained model. This explanation strategy is also evaluated in a large, controlled user study (N=207), using objective (i.e., accuracy) and subjective (i.e., confidence, explanation satisfaction, and trust) psychological measures. The results show that group counterfactuals elicit modest but definite improvements in people's understanding of an AI system. The implications of these findings for counterfactual methods and for XAI are discussed.
Counterfactual Explanations for Misclassified Images: How Human and Machine Explanations Differ
Dec 16, 2022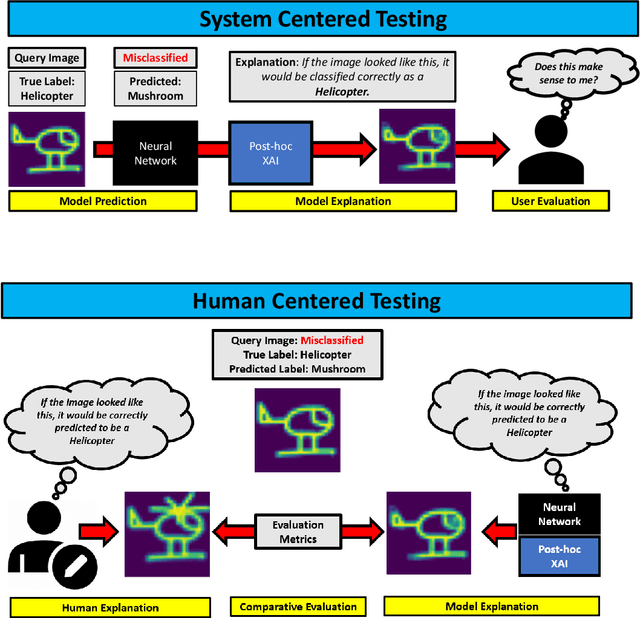
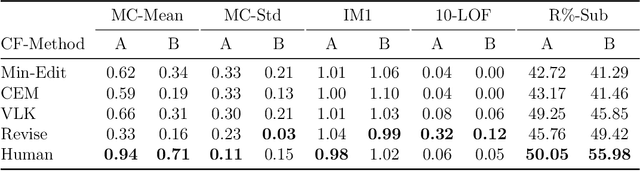
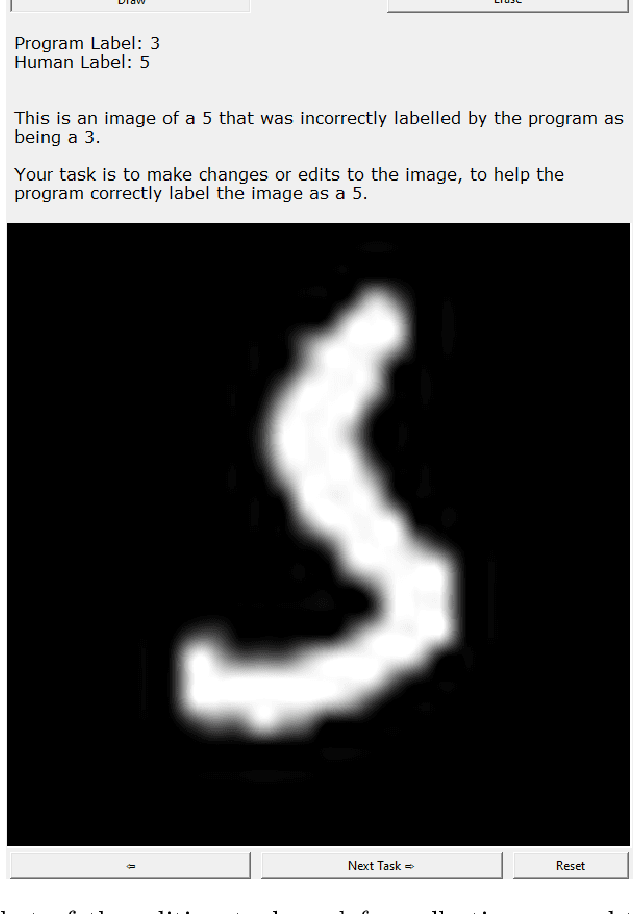
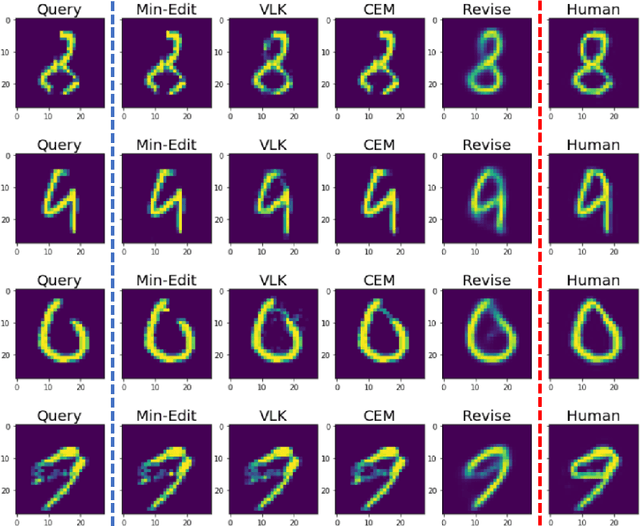
Counterfactual explanations have emerged as a popular solution for the eXplainable AI (XAI) problem of elucidating the predictions of black-box deep-learning systems due to their psychological validity, flexibility across problem domains and proposed legal compliance. While over 100 counterfactual methods exist, claiming to generate plausible explanations akin to those preferred by people, few have actually been tested on users ($\sim7\%$). So, the psychological validity of these counterfactual algorithms for effective XAI for image data is not established. This issue is addressed here using a novel methodology that (i) gathers ground truth human-generated counterfactual explanations for misclassified images, in two user studies and, then, (ii) compares these human-generated ground-truth explanations to computationally-generated explanations for the same misclassifications. Results indicate that humans do not "minimally edit" images when generating counterfactual explanations. Instead, they make larger, "meaningful" edits that better approximate prototypes in the counterfactual class.
Uncertainty Estimation and Out-of-Distribution Detection for Counterfactual Explanations: Pitfalls and Solutions
Jul 20, 2021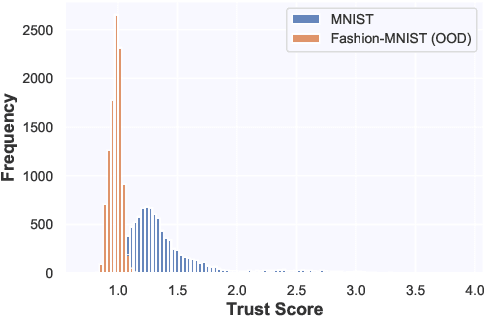
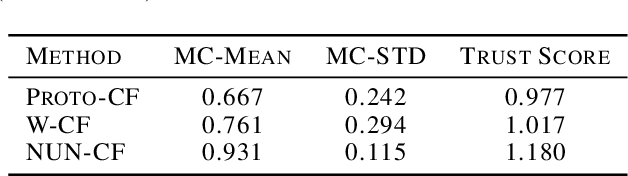
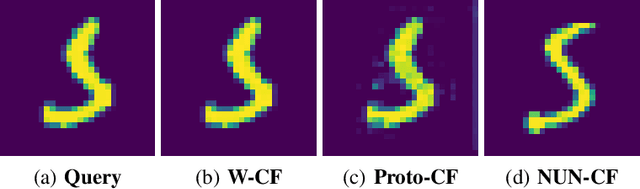
Whilst an abundance of techniques have recently been proposed to generate counterfactual explanations for the predictions of opaque black-box systems, markedly less attention has been paid to exploring the uncertainty of these generated explanations. This becomes a critical issue in high-stakes scenarios, where uncertain and misleading explanations could have dire consequences (e.g., medical diagnosis and treatment planning). Moreover, it is often difficult to determine if the generated explanations are well grounded in the training data and sensitive to distributional shifts. This paper proposes several practical solutions that can be leveraged to solve these problems by establishing novel connections with other research works in explainability (e.g., trust scores) and uncertainty estimation (e.g., Monte Carlo Dropout). Two experiments demonstrate the utility of our proposed solutions.
If Only We Had Better Counterfactual Explanations: Five Key Deficits to Rectify in the Evaluation of Counterfactual XAI Techniques
Feb 26, 2021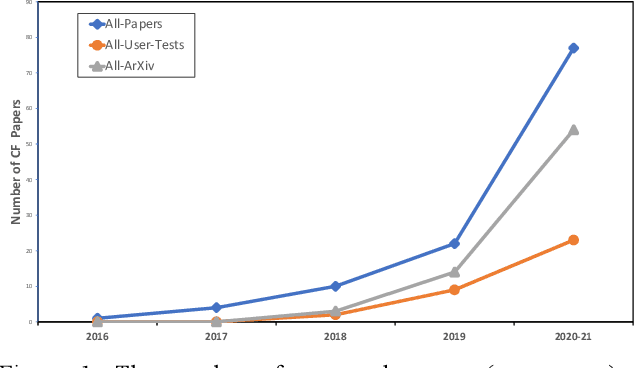
In recent years, there has been an explosion of AI research on counterfactual explanations as a solution to the problem of eXplainable AI (XAI). These explanations seem to offer technical, psychological and legal benefits over other explanation techniques. We survey 100 distinct counterfactual explanation methods reported in the literature. This survey addresses the extent to which these methods have been adequately evaluated, both psychologically and computationally, and quantifies the shortfalls occurring. For instance, only 21% of these methods have been user tested. Five key deficits in the evaluation of these methods are detailed and a roadmap, with standardised benchmark evaluations, is proposed to resolve the issues arising; issues, that currently effectively block scientific progress in this field.
Instance-Based Counterfactual Explanations for Time Series Classification
Sep 28, 2020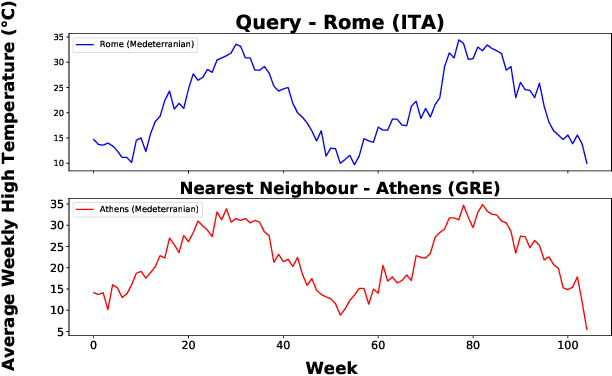

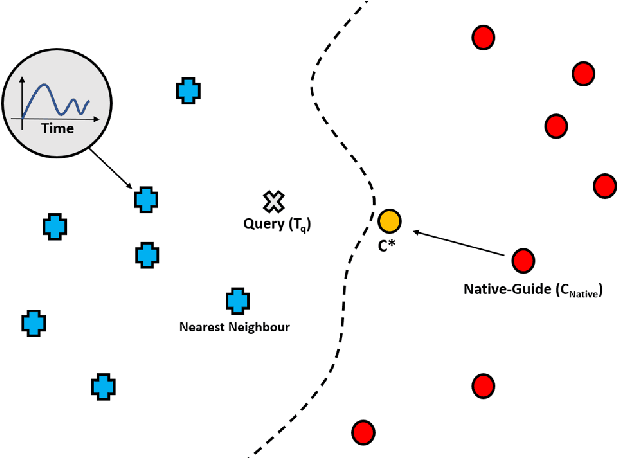
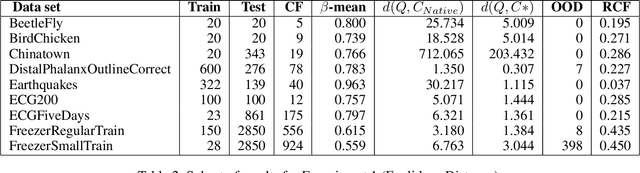
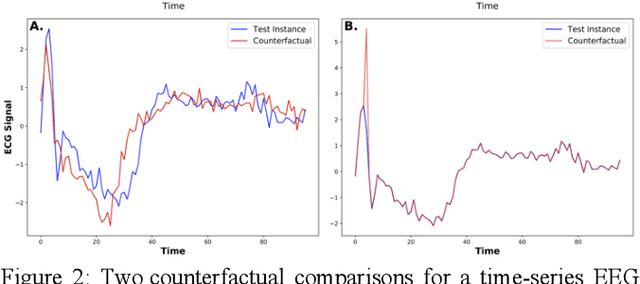
In recent years there has been a cascade of research in attempting to make AI systems more interpretable by providing explanations; so-called Explainable AI (XAI). Most of this research has dealt with the challenges that arise in explaining black-box deep learning systems in classification and regression tasks, with a focus on tabular and image data; for example, there is a rich seam of work on post-hoc counterfactual explanations for a variety of black-box classifiers (e.g., when a user is refused a loan, the counterfactual explanation tells the user about the conditions under which they would get the loan). However, less attention has been paid to the parallel interpretability challenges arising in AI systems dealing with time series data. This paper advances a novel technique, called Native-Guide, for the generation of proximal and plausible counterfactual explanations for instance-based time series classification tasks (e.g., where users are provided with alternative time series to explain how a classification might change). The Native-Guide method retrieves and uses native in-sample counterfactuals that already exist in the training data as "guides" for perturbation in time series counterfactual generation. This method can be coupled with both Euclidean and Dynamic Time Warping (DTW) distance measures. After illustrating the technique on a case study involving a climate classification task, we reported on a comprehensive series of experiments on both real-world and synthetic data sets from the UCR archive. These experiments provide computational evidence of the quality of the counterfactual explanations generated.