 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Counterfactual Explanation Methods for Text Classifiers
Nov 04, 2024



Counterfactual explanations can be used to interpret and debug text classifiers by producing minimally altered text inputs that change a classifier's output. In this work, we evaluate five methods for generating counterfactual explanations for a BERT text classifier on two datasets using three evaluation metrics. The results of our experiments suggest that established white-box substitution-based methods are effective at generating valid counterfactuals that change the classifier's output. In contrast, newer methods based on large language models (LLMs) excel at producing natural and linguistically plausible text counterfactuals but often fail to generate valid counterfactuals that alter the classifier's output. Based on these results, we recommend developing new counterfactual explanation methods that combine the strengths of established gradient-based approaches and newer LLM-based techniques to generate high-quality, valid, and plausible text counterfactual explanations.
Advancing Post Hoc Case Based Explanation with Feature Highlighting
Nov 06, 2023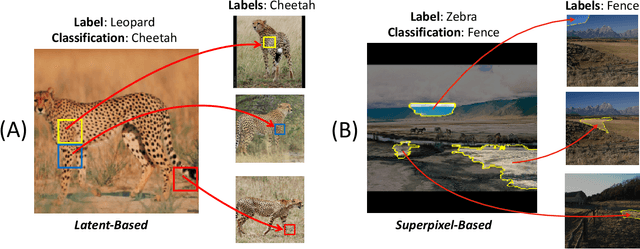
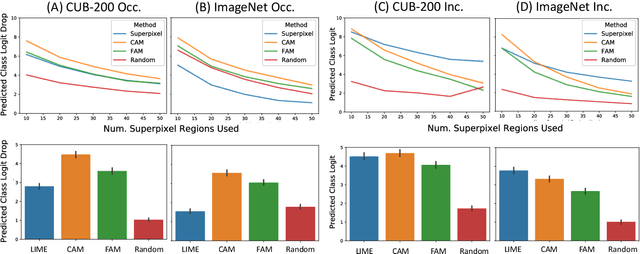
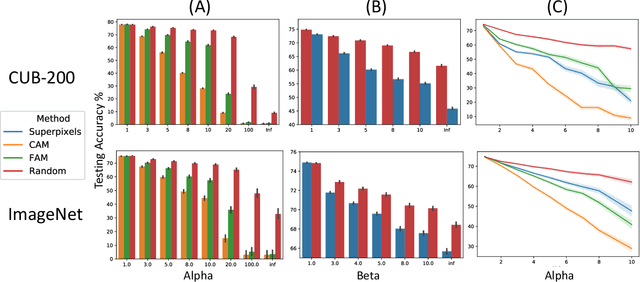
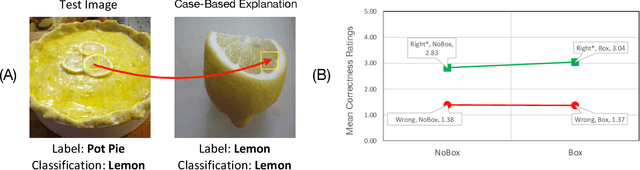
Explainable AI (XAI) has been proposed as a valuable tool to assist in downstream tasks involving human and AI collaboration. Perhaps the most psychologically valid XAI techniques are case based approaches which display 'whole' exemplars to explain the predictions of black box AI systems. However, for such post hoc XAI methods dealing with images, there has been no attempt to improve their scope by using multiple clear feature 'parts' of the images to explain the predictions while linking back to relevant cases in the training data, thus allowing for more comprehensive explanations that are faithful to the underlying model. Here, we address this gap by proposing two general algorithms (latent and super pixel based) which can isolate multiple clear feature parts in a test image, and then connect them to the explanatory cases found in the training data, before testing their effectiveness in a carefully designed user study. Results demonstrate that the proposed approach appropriately calibrates a users feelings of 'correctness' for ambiguous classifications in real world data on the ImageNet dataset, an effect which does not happen when just showing the explanation without feature highlighting.
A Computational Theory of Subjective Probability
May 08, 2014

In this article we demonstrate how algorithmic probability theory is applied to situations that involve uncertainty. When people are unsure of their model of reality, then the outcome they observe will cause them to update their beliefs. We argue that classical probability cannot be applied in such cases, and that subjective probability must instead be used. In Experiment 1 we show that, when judging the probability of lottery number sequences, people apply subjective rather than classical probability. In Experiment 2 we examine the conjunction fallacy and demonstrate that the materials used by Tversky and Kahneman (1983) involve model uncertainty. We then provide a formal mathematical proof that, for every uncertain model, there exists a conjunction of outcomes which is more subjectively probable than either of its constituents in isolation.
Deconstructing analogy
Aug 09, 2013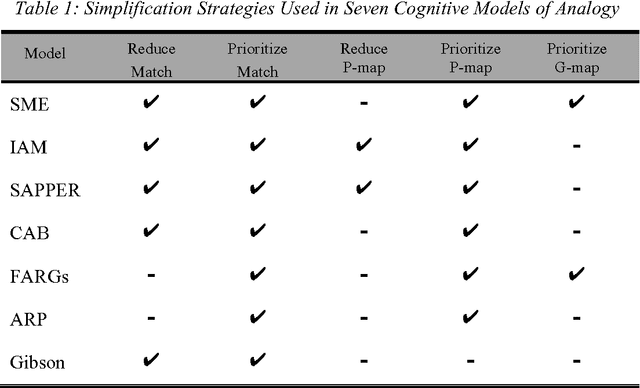
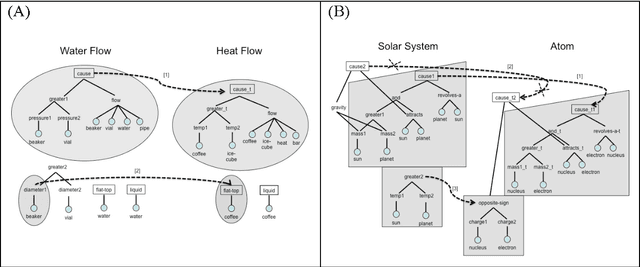
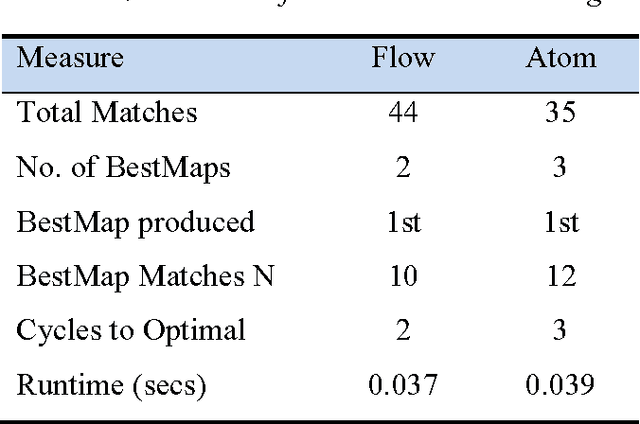
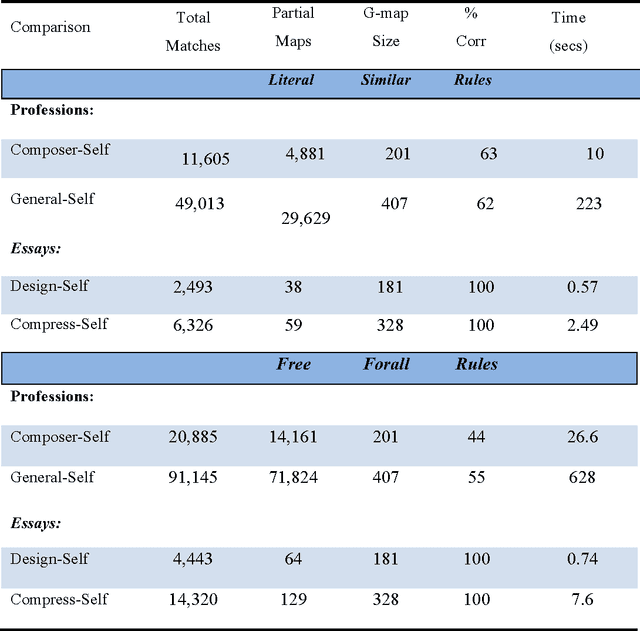
Analogy has been shown to be important in many key cognitive abilities, including learning, problem solving, creativity and language change. For cognitive models of analogy, the fundamental computational question is how its inherent complexity (its NP-hardness) is solved by the human cognitive system. Indeed, different models of analogical processing can be categorized by the simplification strategies they adopt to make this computational problem more tractable. In this paper, I deconstruct several of these models in terms of the simplification-strategies they use; a deconstruction that provides some interesting perspectives on the relative differences between them. Later, I consider whether any of these computational simplifications reflect the actual strategies used by people and sketch a new cognitive model that tries to present a closer fit to the psychological evidence.
Identifying Metaphoric Antonyms in a Corpus Analysis of Finance Articles
Feb 04, 2013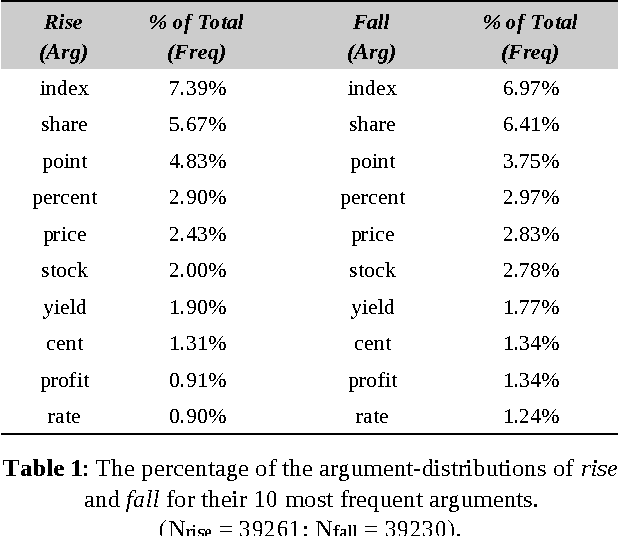


Using a corpus of 17,000+ financial news reports (involving over 10M words), we perform an analysis of the argument-distributions of the UP and DOWN verbs used to describe movements of indices, stocks and shares. In Study 1 participants identified antonyms of these verbs in a free-response task and a matching task from which the most commonly identified antonyms were compiled. In Study 2, we determined whether the argument-distributions for the verbs in these antonym-pairs were sufficiently similar to predict the most frequently-identified antonym. Cosine similarity correlates moderately with the proportions of antonym-pairs identified by people (r = 0.31). More impressively, 87% of the time the most frequently-identified antonym is either the first- or second-most similar pair in the set of alternatives. The implications of these results for distributional approaches to determining metaphoric knowledge are discussed.
* arXiv admin note: text overlap with arXiv:1212.3138
Identifying Metaphor Hierarchies in a Corpus Analysis of Finance Articles
Dec 13, 2012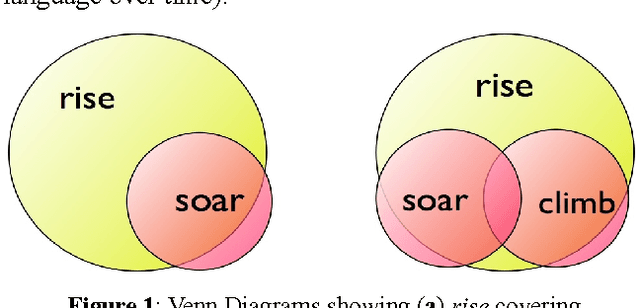
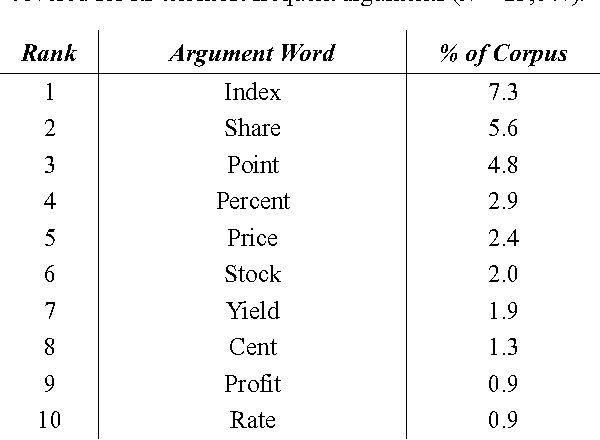
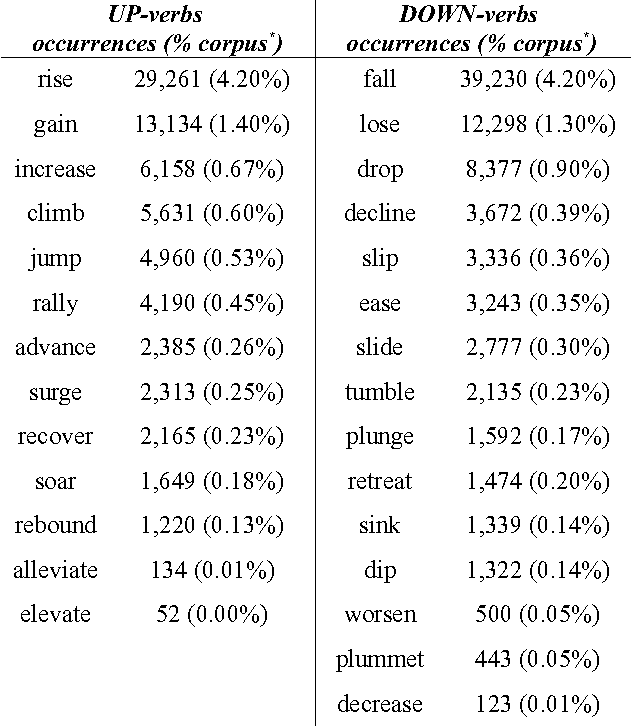

Using a corpus of over 17,000 financial news reports (involving over 10M words), we perform an analysis of the argument-distributions of the UP- and DOWN-verbs used to describe movements of indices, stocks, and shares. Using measures of the overlap in the argument distributions of these verbs and k-means clustering of their distributions, we advance evidence for the proposal that the metaphors referred to by these verbs are organised into hierarchical structures of superordinate and subordinate groups.
Mining the Web for the Voice of the Herd to Track Stock Market Bubbles
Dec 11, 2012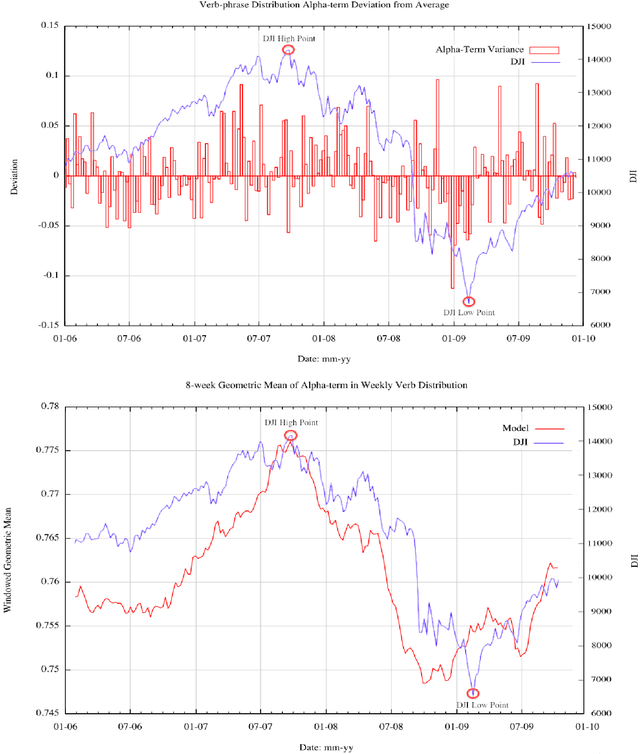
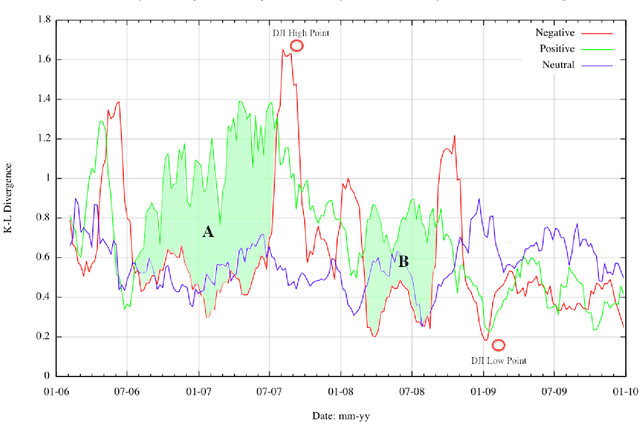
We show that power-law analyses of financial commentaries from newspaper web-sites can be used to identify stock market bubbles, supplementing traditional volatility analyses. Using a four-year corpus of 17,713 online, finance-related articles (10M+ words) from the Financial Times, the New York Times, and the BBC, we show that week-to-week changes in power-law distributions reflect market movements of the Dow Jones Industrial Average (DJI), the FTSE-100, and the NIKKEI-225. Notably, the statistical regularities in language track the 2007 stock market bubble, showing emerging structure in the language of commentators, as progressively greater agreement arose in their positive perceptions of the market. Furthermore, during the bubble period, a marked divergence in positive language occurs as revealed by a Kullback-Leibler analysis.