 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflexive Regular Equivalence for Bipartite Data
Feb 16, 2017

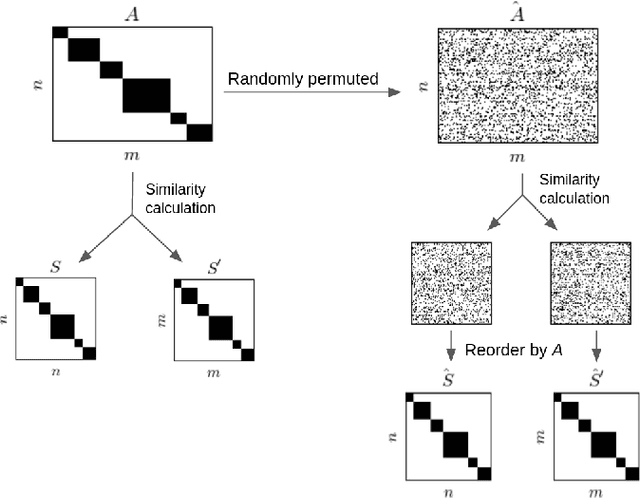
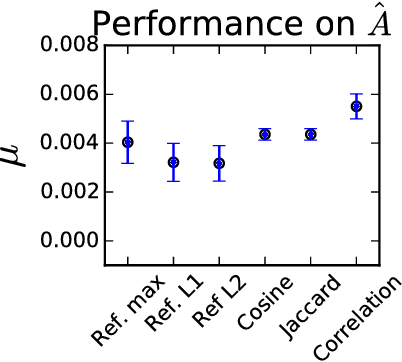
Bipartite data is common in data engineering and brings unique challenges, particularly when it comes to clustering tasks that impose on strong structural assumptions. This work presents an unsupervised method for assessing similarity in bipartite data. Similar to some co-clustering methods, the method is based on regular equivalence in graphs. The algorithm uses spectral properties of a bipartite adjacency matrix to estimate similarity in both dimensions. The method is reflexive in that similarity in one dimension is used to inform similarity in the other. Reflexive regular equivalence can also use the structure of transitivities -- in a network sense -- the contribution of which is controlled by the algorithm's only free-parameter, $\alpha$. The method is completely unsupervised and can be used to validate assumptions of co-similarity, which are required but often untested, in co-clustering analyses. Three variants of the method with different normalizations are tested on synthetic data. The method is found to be robust to noise and well-suited to asymmetric co-similar structure, making it particularly informative for cluster analysis and recommendation in bipartite data of unknown structure. In experiments, the convergence and speed of the algorithm are found to be stable for different levels of noise. Real-world data from a network of malaria genes are analyzed, where the similarity produced by the reflexive method is shown to out-perform other measures' ability to correctly classify genes.
Fast, Flexible Models for Discovering Topic Correlation across Weakly-Related Collections
Aug 19, 2015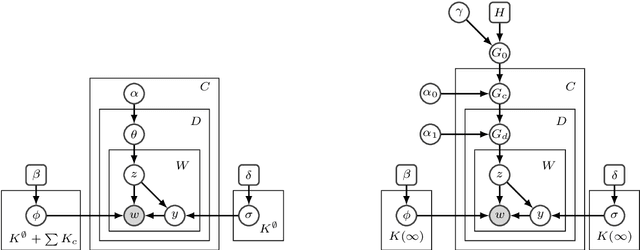

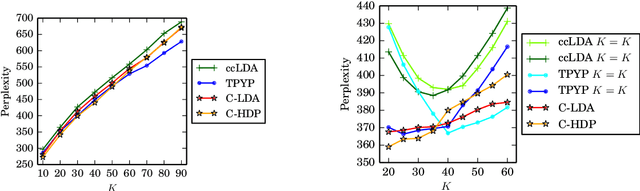

Weak topic correlation across document collections with different numbers of topics in individual collections presents challenges for existing cross-collection topic models. This paper introduces two probabilistic topic models, Correlated LDA (C-LDA) and Correlated HDP (C-HDP). These address problems that can arise when analyzing large, asymmetric, and potentially weakly-related collections. Topic correlations in weakly-related collections typically lie in the tail of the topic distribution, where they would be overlooked by models unable to fit large numbers of topics. To efficiently model this long tail for large-scale analysis, our models implement a parallel sampling algorithm based on the Metropolis-Hastings and alias methods (Yuan et al., 2015). The models are first evaluated on synthetic data, generated to simulate various collection-level asymmetries. We then present a case study of modeling over 300k documents in collections of sciences and humanities research from JSTOR.
Identifying Metaphoric Antonyms in a Corpus Analysis of Finance Articles
Feb 04, 2013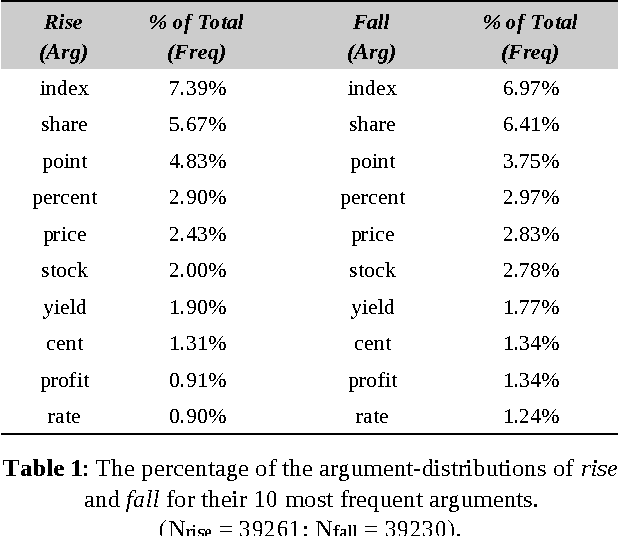


Using a corpus of 17,000+ financial news reports (involving over 10M words), we perform an analysis of the argument-distributions of the UP and DOWN verbs used to describe movements of indices, stocks and shares. In Study 1 participants identified antonyms of these verbs in a free-response task and a matching task from which the most commonly identified antonyms were compiled. In Study 2, we determined whether the argument-distributions for the verbs in these antonym-pairs were sufficiently similar to predict the most frequently-identified antonym. Cosine similarity correlates moderately with the proportions of antonym-pairs identified by people (r = 0.31). More impressively, 87% of the time the most frequently-identified antonym is either the first- or second-most similar pair in the set of alternatives. The implications of these results for distributional approaches to determining metaphoric knowledge are discussed.
* arXiv admin note: text overlap with arXiv:1212.3138
Diachronic Variation in Grammatical Relations
Dec 13, 2012


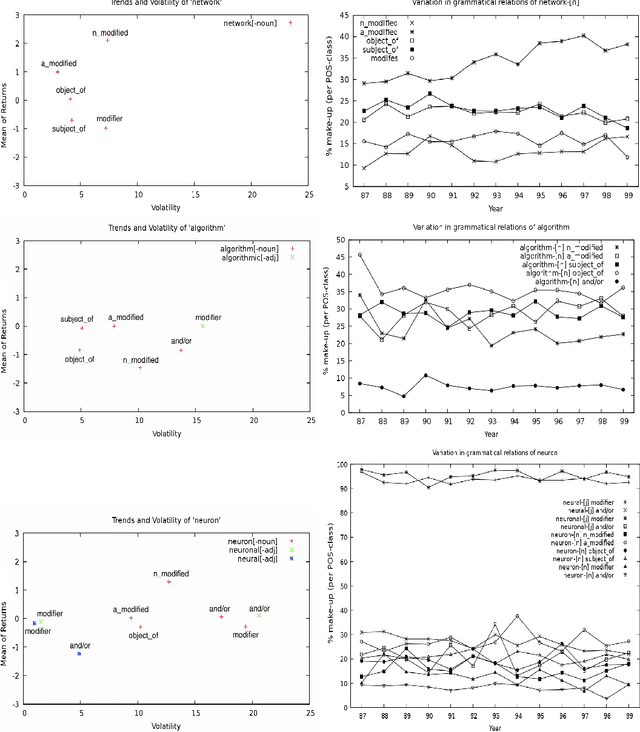
We present a method of finding and analyzing shifts in grammatical relations found in diachronic corpora. Inspired by the econometric technique of measuring return and volatility instead of relative frequencies, we propose them as a way to better characterize changes in grammatical patterns like nominalization, modification and comparison. To exemplify the use of these techniques, we examine a corpus of NIPS papers and report trends which manifest at the token, part-of-speech and grammatical levels. Building up from frequency observations to a second-order analysis, we show that shifts in frequencies overlook deeper trends in language, even when part-of-speech information is included. Examining token, POS and grammatical levels of variation enables a summary view of diachronic text as a whole. We conclude with a discussion about how these methods can inform intuitions about specialist domains as well as changes in language use as a whole.
Mining the Web for the Voice of the Herd to Track Stock Market Bubbles
Dec 11, 2012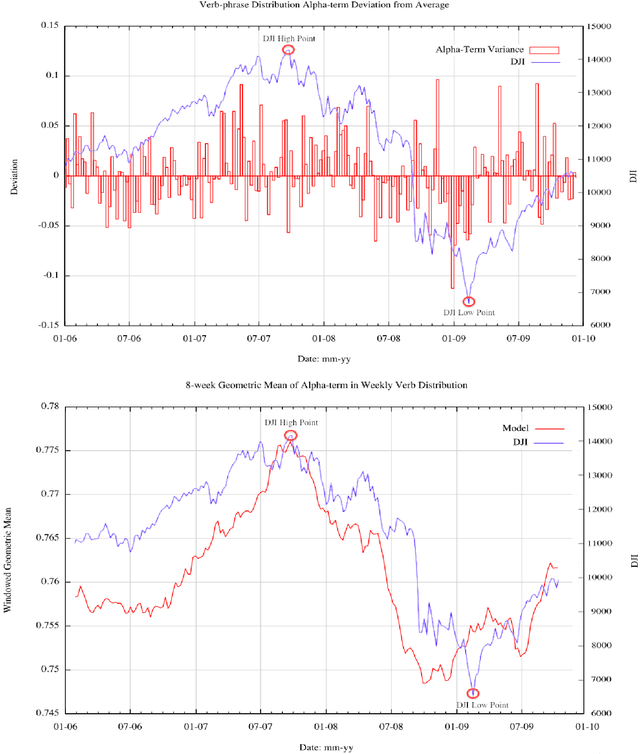
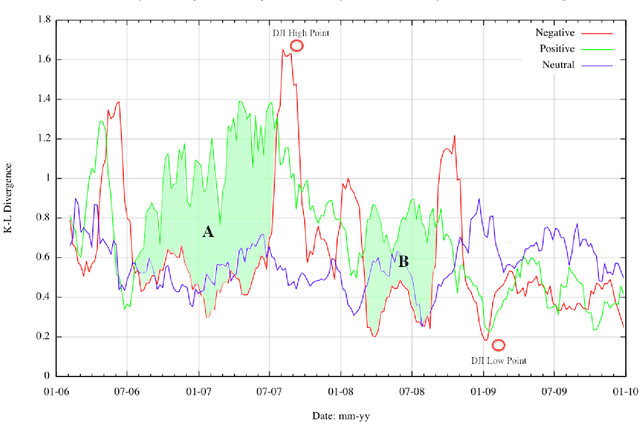
We show that power-law analyses of financial commentaries from newspaper web-sites can be used to identify stock market bubbles, supplementing traditional volatility analyses. Using a four-year corpus of 17,713 online, finance-related articles (10M+ words) from the Financial Times, the New York Times, and the BBC, we show that week-to-week changes in power-law distributions reflect market movements of the Dow Jones Industrial Average (DJI), the FTSE-100, and the NIKKEI-225. Notably, the statistical regularities in language track the 2007 stock market bubble, showing emerging structure in the language of commentators, as progressively greater agreement arose in their positive perceptions of the market. Furthermore, during the bubble period, a marked divergence in positive language occurs as revealed by a Kullback-Leibler analysis.