 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Phenotype Definitions for Algorithmic Fairness
Mar 10, 2022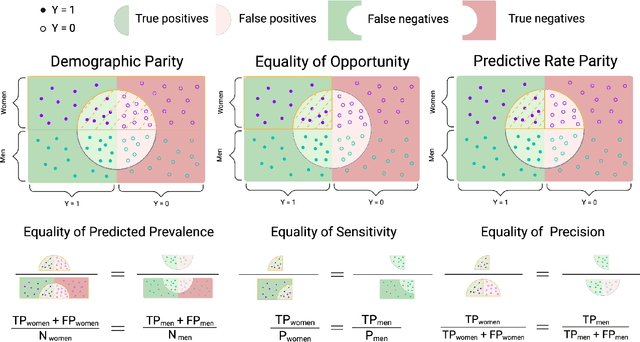
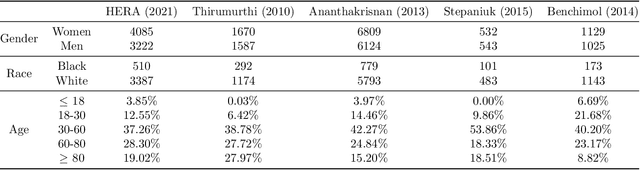
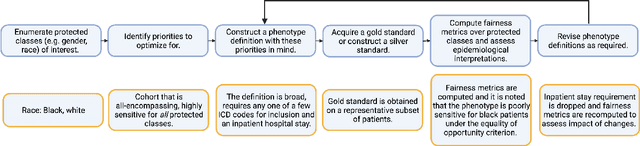
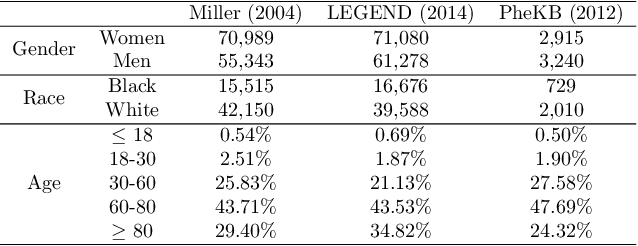
Disease identification is a core, routine activity in observational health research. Cohorts impact downstream analyses, such as how a condition is characterized, how patient risk is defined, and what treatments are studied. It is thus critical to ensure that selected cohorts are representative of all patients, independently of their demographics or social determinants of health. While there are multiple potential sources of bias when constructing phenotype definitions which may affect their fairness, it is not standard in the field of phenotyping to consider the impact of different definitions across subgroups of patients. In this paper, we propose a set of best practices to assess the fairness of phenotype definitions. We leverage established fairness metrics commonly used in predictive models and relate them to commonly used epidemiological cohort description metrics. We describe an empirical study for Crohn's disease and diabetes type 2, each with multiple phenotype definitions taken from the literature across two sets of patient subgroups (gender and race). We show that the different phenotype definitions exhibit widely varying and disparate performance according to the different fairness metrics and subgroups. We hope that the proposed best practices can help in constructing fair and inclusive phenotype definitions.
Evaluating representations by the complexity of learning low-loss predictors
Sep 15, 2020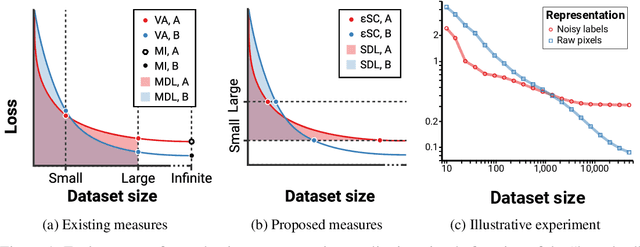
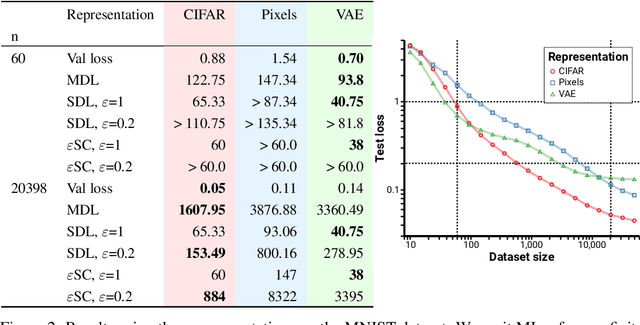
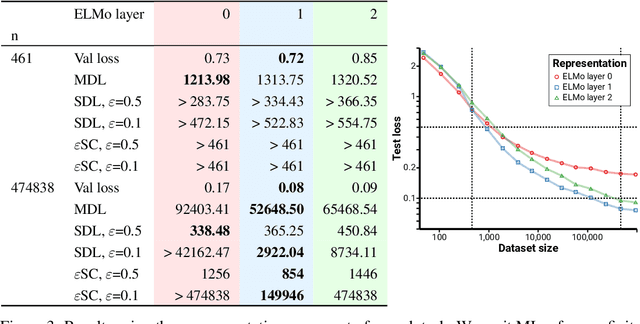
We consider the problem of evaluating representations of data for use in solving a downstream task. We propose to measure the quality of a representation by the complexity of learning a predictor on top of the representation that achieves low loss on a task of interest, and introduce two methods, surplus description length (SDL) and $\varepsilon$ sample complexity ($\varepsilon$SC). In contrast to prior methods, which measure the amount of information about the optimal predictor that is present in a specific amount of data, our methods measure the amount of information needed from the data to recover an approximation of the optimal predictor up to a specified tolerance. We present a framework to compare these methods based on plotting the validation loss versus training set size (the "loss-data" curve). Existing measures, such as mutual information and minimum description length probes, correspond to slices and integrals along the data-axis of the loss-data curve, while ours correspond to slices and integrals along the loss-axis. We provide experiments on real data to compare the behavior of each of these methods over datasets of varying size along with a high performance open source library for representation evaluation at https://github.com/willwhitney/reprieve.
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
Apr 11, 2019



Clinical notes contain information about patients that goes beyond structured data like lab values and medications. However, clinical notes have been underused relative to structured data, because notes are high-dimensional and sparse. This work develops and evaluates representations of clinical notes using bidirectional transformers (ClinicalBERT). ClinicalBERT uncovers high-quality relationships between medical concepts as judged by humans. ClinicalBert outperforms baselines on 30-day hospital readmission prediction using both discharge summaries and the first few days of notes in the intensive care unit. Code and model parameters are available.
Noisin: Unbiased Regularization for Recurrent Neural Networks
Jul 13, 2018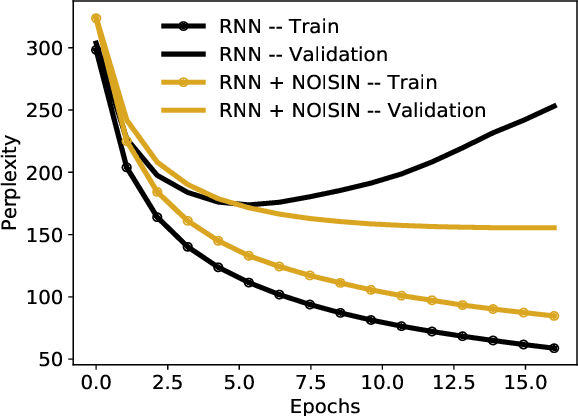
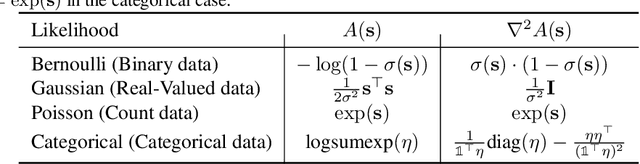

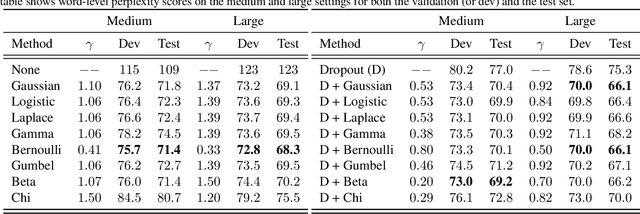
Recurrent neural networks (RNNs) are powerful models of sequential data. They have been successfully used in domains such as text and speech. However, RNNs are susceptible to overfitting; regularization is important. In this paper we develop Noisin, a new method for regularizing RNNs. Noisin injects random noise into the hidden states of the RNN and then maximizes the corresponding marginal likelihood of the data. We show how Noisin applies to any RNN and we study many different types of noise. Noisin is unbiased--it preserves the underlying RNN on average. We characterize how Noisin regularizes its RNN both theoretically and empirically. On language modeling benchmarks, Noisin improves over dropout by as much as 12.2% on the Penn Treebank and 9.4% on the Wikitext-2 dataset. We also compared the state-of-the-art language model of Yang et al. 2017, both with and without Noisin. On the Penn Treebank, the method with Noisin more quickly reaches state-of-the-art performance.
Operator Variational Inference
Mar 15, 2018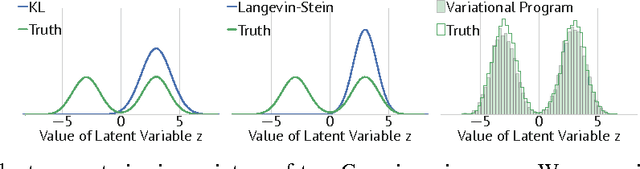

Variational inference is an umbrella term for algorithms which cast Bayesian inference as optimization. Classically, variational inference uses the Kullback-Leibler divergence to define the optimization. Though this divergence has been widely used, the resultant posterior approximation can suffer from undesirable statistical properties. To address this, we reexamine variational inference from its roots as an optimization problem. We use operators, or functions of functions, to design variational objectives. As one example, we design a variational objective with a Langevin-Stein operator. We develop a black box algorithm, operator variational inference (OPVI), for optimizing any operator objective. Importantly, operators enable us to make explicit the statistical and computational tradeoffs for variational inference. We can characterize different properties of variational objectives, such as objectives that admit data subsampling---allowing inference to scale to massive data---as well as objectives that admit variational programs---a rich class of posterior approximations that does not require a tractable density. We illustrate the benefits of OPVI on a mixture model and a generative model of images.
Proximity Variational Inference
May 24, 2017

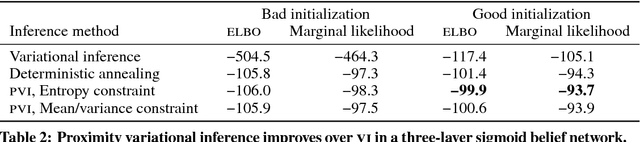

Variational inference is a powerful approach for approximate posterior inference. However, it is sensitive to initialization and can be subject to poor local optima. In this paper, we develop proximity variational inference (PVI). PVI is a new method for optimizing the variational objective that constrains subsequent iterates of the variational parameters to robustify the optimization path. Consequently, PVI is less sensitive to initialization and optimization quirks and finds better local optima. We demonstrate our method on three proximity statistics. We study PVI on a Bernoulli factor model and sigmoid belief network with both real and synthetic data and compare to deterministic annealing (Katahira et al., 2008). We highlight the flexibility of PVI by designing a proximity statistic for Bayesian deep learning models such as the variational autoencoder (Kingma and Welling, 2014; Rezende et al., 2014). Empirically, we show that PVI consistently finds better local optima and gives better predictive performance.
Fast, Flexible Models for Discovering Topic Correlation across Weakly-Related Collections
Aug 19, 2015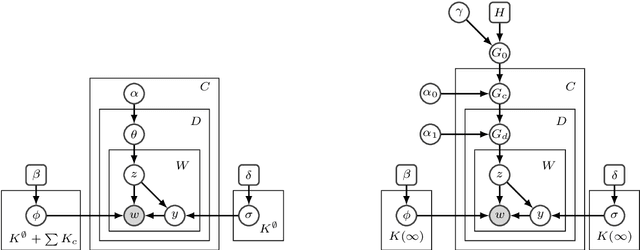

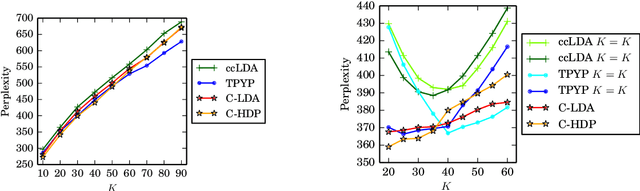

Weak topic correlation across document collections with different numbers of topics in individual collections presents challenges for existing cross-collection topic models. This paper introduces two probabilistic topic models, Correlated LDA (C-LDA) and Correlated HDP (C-HDP). These address problems that can arise when analyzing large, asymmetric, and potentially weakly-related collections. Topic correlations in weakly-related collections typically lie in the tail of the topic distribution, where they would be overlooked by models unable to fit large numbers of topics. To efficiently model this long tail for large-scale analysis, our models implement a parallel sampling algorithm based on the Metropolis-Hastings and alias methods (Yuan et al., 2015). The models are first evaluated on synthetic data, generated to simulate various collection-level asymmetries. We then present a case study of modeling over 300k documents in collections of sciences and humanities research from JSTOR.