 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating representations by the complexity of learning low-loss predictors
Paper and Code
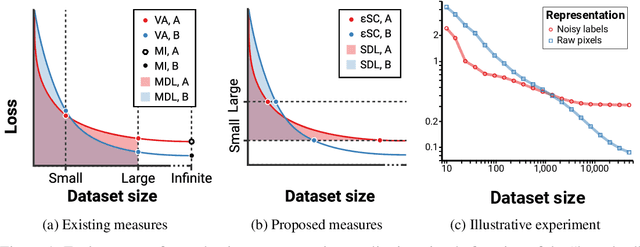
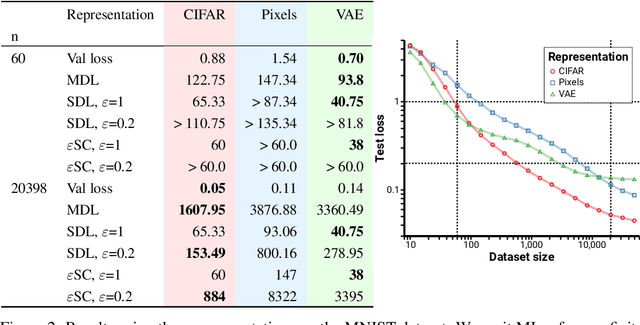
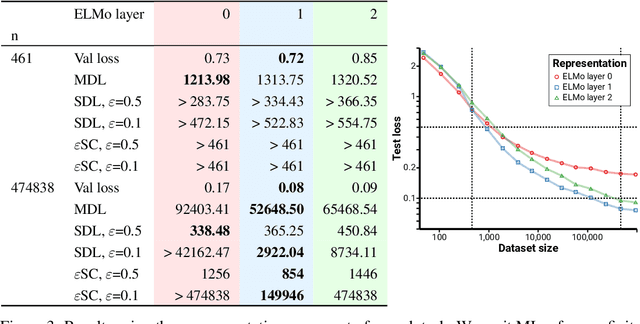
We consider the problem of evaluating representations of data for use in solving a downstream task. We propose to measure the quality of a representation by the complexity of learning a predictor on top of the representation that achieves low loss on a task of interest, and introduce two methods, surplus description length (SDL) and $\varepsilon$ sample complexity ($\varepsilon$SC). In contrast to prior methods, which measure the amount of information about the optimal predictor that is present in a specific amount of data, our methods measure the amount of information needed from the data to recover an approximation of the optimal predictor up to a specified tolerance. We present a framework to compare these methods based on plotting the validation loss versus training set size (the "loss-data" curve). Existing measures, such as mutual information and minimum description length probes, correspond to slices and integrals along the data-axis of the loss-data curve, while ours correspond to slices and integrals along the loss-axis. We provide experiments on real data to compare the behavior of each of these methods over datasets of varying size along with a high performance open source library for representation evaluation at https://github.com/willwhitney/reprieve.