 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Head Attention
Feb 24, 2026Multi-Head Attention (MHA) is the core computational primitive underlying modern Large Language Models (LLMs). However, MHA suffers from a fundamental linear scaling limitation: $H$ attention heads produce exactly $H$ independent attention matrices, with no communication between heads during attention computation. This becomes problematic for multi-step reasoning, where correct answers depend on aggregating evidence from multiple parts of the context and composing latent token-to-token relations over a chain of intermediate inferences. To address this, we propose Interleaved Head Attention (IHA), which enables cross-head mixing by constructing $P$ pseudo-heads per head (typically $P=H$), where each pseudo query/key/value is a learned linear combination of all $H$ original queries, keys and values respectively. Interactions between pseudo-query and pseudo-key heads induce up to $P^2$ attention patterns per head with modest parameter overhead $\mathcal{O}(H^2P)$. We provide theory showing improved efficiency in terms of number of parameters on the synthetic Polynomial task (IHA uses $Θ(\sqrt{k}n^2)$ parameters vs. $Θ(kn^2)$ for MHA) and on the synthetic order-sensitive CPM-3 task (IHA uses $\lceil\sqrt{N_{\max}}\rceil$ heads vs. $N_{\max}$ for MHA). On real-world benchmarks, IHA improves Multi-Key retrieval on RULER by 10-20% (4k-16k) and, after fine-tuning for reasoning on OpenThoughts, improves GSM8K by 5.8% and MATH-500 by 2.8% (Majority Vote) over full attention.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
GQ-VAE: A gated quantized VAE for learning variable length tokens
Dec 26, 2025While most frontier models still use deterministic frequency-based tokenization algorithms such as byte-pair encoding (BPE), there has been significant recent work to design learned neural tokenizers. However, these schemes generally add to underlying language model complexity and force large changes to architecture, making them hard to implement at large scales. To overcome these challenges, we propose the gated quantized variational autoencoder (GQ-VAE), a novel architecture that can be independently pre-trained to serve as a drop-in replacement for existing tokenizers. The key innovation of the architecture is to learn to encode variable-length discrete tokens. GQ-VAE improves compression and language modeling performance over a standard VQ-VAE tokenizer, and approaches the compression rate and language modeling performance of BPE. Interestingly, if we use BPE with a smaller vocabulary, such that the compression is equivalent between GQ-VAE and BPE, we find that GQ-VAE improves downstream language model learning. We conclude with a discussion of several exciting avenues for future work. Code can be found at https://github.com/Theo-Datta-115/gq-vae.
Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
The Role of Sparsity for Length Generalization in Transformers
Feb 24, 2025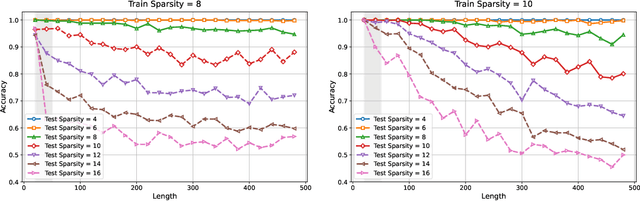

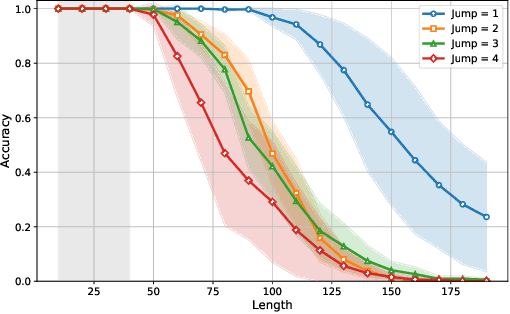
Training large language models to predict beyond their training context lengths has drawn much attention in recent years, yet the principles driving such behavior of length generalization remain underexplored. We propose a new theoretical framework to study length generalization for the next-token prediction task, as performed by decoder-only transformers. Conceptually, we show that length generalization occurs as long as each predicted token depends on a small (fixed) number of previous tokens. We formalize such tasks via a notion we call $k$-sparse planted correlation distributions, and show that an idealized model of transformers which generalize attention heads successfully length-generalize on such tasks. As a bonus, our theoretical model justifies certain techniques to modify positional embeddings which have been introduced to improve length generalization, such as position coupling. We support our theoretical results with experiments on synthetic tasks and natural language, which confirm that a key factor driving length generalization is a ``sparse'' dependency structure of each token on the previous ones. Inspired by our theory, we introduce Predictive Position Coupling, which trains the transformer to predict the position IDs used in a positional coupling approach. Predictive Position Coupling thereby allows us to broaden the array of tasks to which position coupling can successfully be applied to achieve length generalization.
Loss-to-Loss Prediction: Scaling Laws for All Datasets
Nov 19, 2024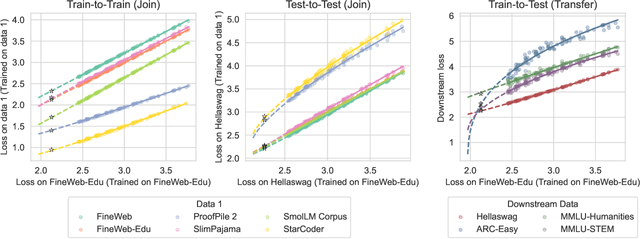
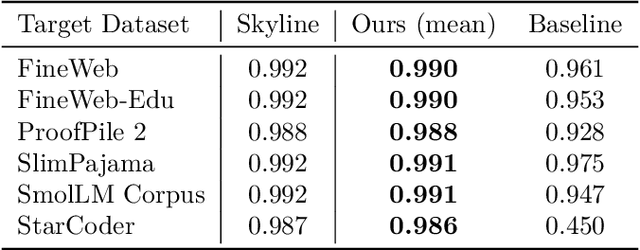
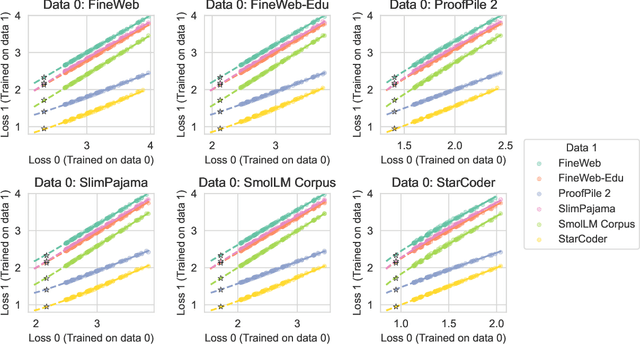

While scaling laws provide a reliable methodology for predicting train loss across compute scales for a single data distribution, less is known about how these predictions should change as we change the distribution. In this paper, we derive a strategy for predicting one loss from another and apply it to predict across different pre-training datasets and from pre-training data to downstream task data. Our predictions extrapolate well even at 20x the largest FLOP budget used to fit the curves. More precisely, we find that there are simple shifted power law relationships between (1) the train losses of two models trained on two separate datasets when the models are paired by training compute (train-to-train), (2) the train loss and the test loss on any downstream distribution for a single model (train-to-test), and (3) the test losses of two models trained on two separate train datasets (test-to-test). The results hold up for pre-training datasets that differ substantially (some are entirely code and others have no code at all) and across a variety of downstream tasks. Finally, we find that in some settings these shifted power law relationships can yield more accurate predictions than extrapolating single-dataset scaling laws.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024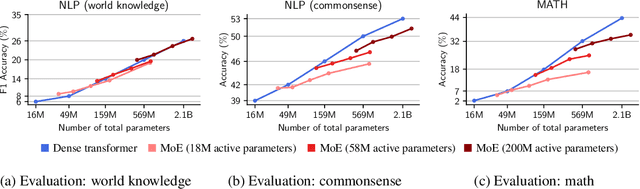
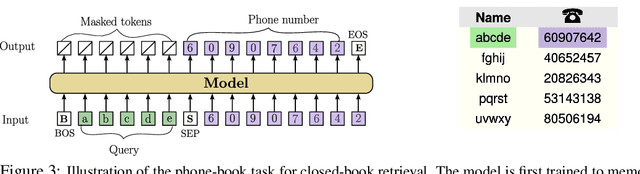
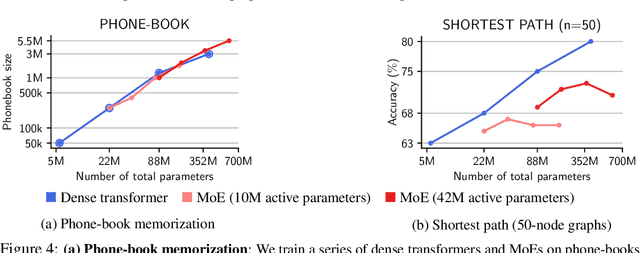
The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.
SOAP: Improving and Stabilizing Shampoo using Adam
Sep 17, 2024



There is growing evidence of the effectiveness of Shampoo, a higher-order preconditioning method, over Adam in deep learning optimization tasks. However, Shampoo's drawbacks include additional hyperparameters and computational overhead when compared to Adam, which only updates running averages of first- and second-moment quantities. This work establishes a formal connection between Shampoo (implemented with the 1/2 power) and Adafactor -- a memory-efficient approximation of Adam -- showing that Shampoo is equivalent to running Adafactor in the eigenbasis of Shampoo's preconditioner. This insight leads to the design of a simpler and computationally efficient algorithm: $\textbf{S}$hampo$\textbf{O}$ with $\textbf{A}$dam in the $\textbf{P}$reconditioner's eigenbasis (SOAP). With regards to improving Shampoo's computational efficiency, the most straightforward approach would be to simply compute Shampoo's eigendecomposition less frequently. Unfortunately, as our empirical results show, this leads to performance degradation that worsens with this frequency. SOAP mitigates this degradation by continually updating the running average of the second moment, just as Adam does, but in the current (slowly changing) coordinate basis. Furthermore, since SOAP is equivalent to running Adam in a rotated space, it introduces only one additional hyperparameter (the preconditioning frequency) compared to Adam. We empirically evaluate SOAP on language model pre-training with 360m and 660m sized models. In the large batch regime, SOAP reduces the number of iterations by over 40% and wall clock time by over 35% compared to AdamW, with approximately 20% improvements in both metrics compared to Shampoo. An implementation of SOAP is available at https://github.com/nikhilvyas/SOAP.
Deconstructing What Makes a Good Optimizer for Language Models
Jul 10, 2024Training language models becomes increasingly expensive with scale, prompting numerous attempts to improve optimization efficiency. Despite these efforts, the Adam optimizer remains the most widely used, due to a prevailing view that it is the most effective approach. We aim to compare several optimization algorithms, including SGD, Adafactor, Adam, and Lion, in the context of autoregressive language modeling across a range of model sizes, hyperparameters, and architecture variants. Our findings indicate that, except for SGD, these algorithms all perform comparably both in their optimal performance and also in terms of how they fare across a wide range of hyperparameter choices. Our results suggest to practitioners that the choice of optimizer can be guided by practical considerations like memory constraints and ease of implementation, as no single algorithm emerged as a clear winner in terms of performance or stability to hyperparameter misspecification. Given our findings, we further dissect these approaches, examining two simplified versions of Adam: a) signed momentum (Signum) which we see recovers both the performance and hyperparameter stability of Adam and b) Adalayer, a layerwise variant of Adam which we introduce to study Adam's preconditioning. Examining Adalayer leads us to the conclusion that the largest impact of Adam's preconditioning is restricted to the last layer and LayerNorm parameters, and, perhaps surprisingly, the remaining layers can be trained with SGD.
Universal Length Generalization with Turing Programs
Jul 03, 2024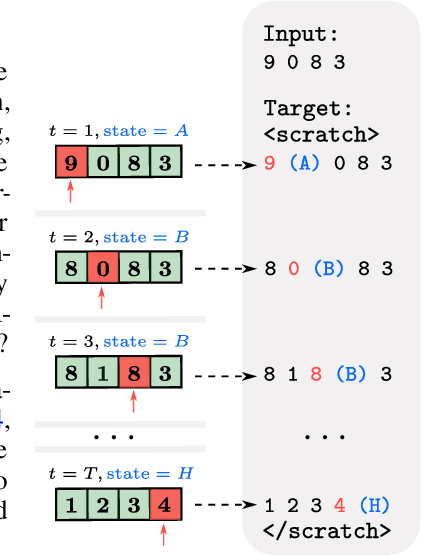

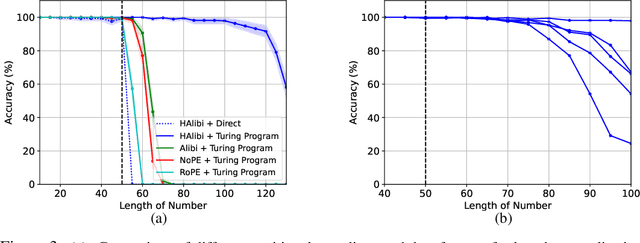
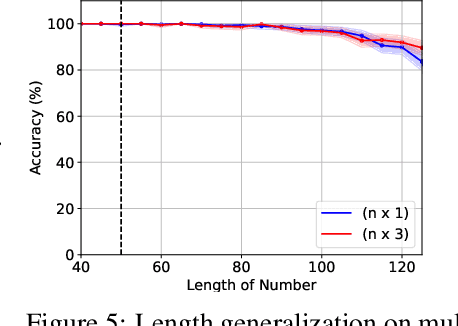
Length generalization refers to the ability to extrapolate from short training sequences to long test sequences and is a challenge for current large language models. While prior work has proposed some architecture or data format changes to achieve length generalization, these proposals typically apply to a limited set of tasks. Building on prior scratchpad and Chain-of-Thought (CoT) techniques, we propose Turing Programs, a novel CoT strategy that decomposes an algorithmic task into steps mimicking the computation of a Turing Machine. This framework is both universal, as it can accommodate any algorithmic task, and simple, requiring only copying text from the context with small modifications. We show that by using Turing Programs, we obtain robust length generalization on a range of algorithmic tasks: addition, multiplication and in-context SGD. We then demonstrate that transformers achieve length generalization on random Turing Programs, suggesting that length generalization is possible for any algorithmic task. Finally, we theoretically prove that transformers can implement Turing Programs, constructing a simple RASP (Weiss et al.) program that simulates an arbitrary Turing machine.